Late Chunking x Milvus: как повысить точность RAG


01.контексты
При разработке приложения RAG первым шагом является разбивка документа на куски, эффективная разбивка документа может эффективно повысить точность последующего отзыва содержимого. Как эффективно разбить документ на куски является горячей темой для обсуждения, есть такие, как фиксированный размер chunking, случайный размер chunking, скользящее окно повторной выборки, рекурсивный chunking, на основе содержания семантического chunking и другие методы. Метод Late Chunking, предложенный компанией Jina AI, рассматривает проблему кускования с другой стороны, давайте рассмотрим его.
02.Что такое Late Chunking?
При работе с длинными документами традиционное разбиение на фрагменты может привести к потере дальних контекстных зависимостей в документах, что является одним из основных препятствий для поиска и понимания информации. То есть, когда ключевая информация разбросана по нескольким текстовым блокам, фрагмент текста, вырванный из контекста, скорее всего, потеряет свой первоначальный смысл, что приведет к ухудшению последующего запоминания.
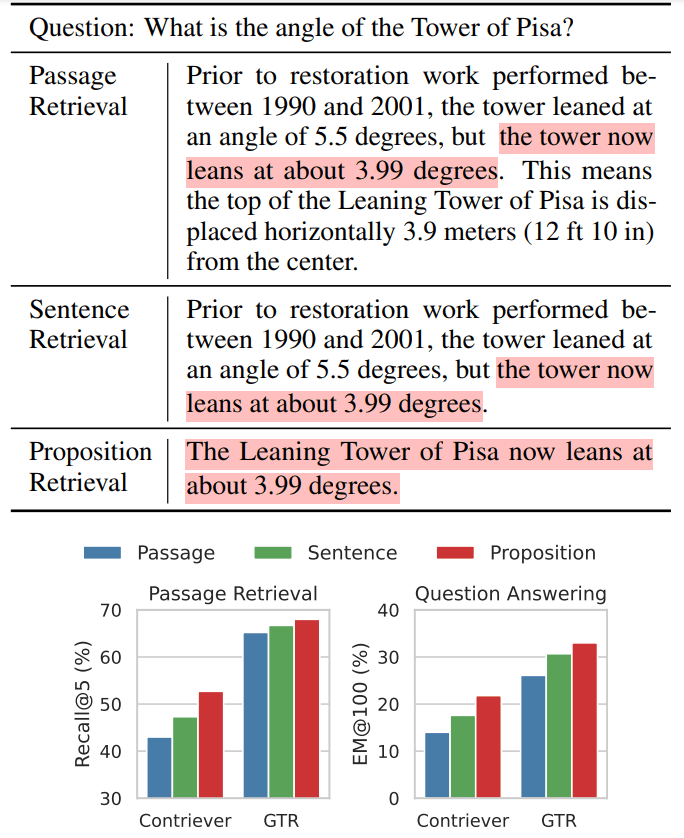
Возьмем, к примеру, релиз Milvus 2.4.13, если он разделен на два блока документов, как показано ниже, и если мы хотим запроситьMilvus 2.4.13有哪些新功能?Непосредственно релевантный контент находится в чанке 2, а информация о версии Milvus - в чанке 1. В этот момент модели встраивания сложно правильно связать эти ссылки с сущностями, что приводит к низкому качеству встраивания.
LLM испытывает трудности с решением такой проблемы корреляции из-за того, что функциональное описание не находится в том же фрагменте, что и информация о версии, а также из-за отсутствия более крупного контекстного документа. Хотя существует ряд эвристик, которые пытаются решить эту проблему, например, повторная выборка скользящего окна, перекрытие длин контекстных окон и многократное сканирование документов, однако, как и все эвристики, эти методы не всегда срабатывают; они могут сработать в некоторых случаях, но теоретических гарантий нет.
При традиционном разбиении используется стратегия предварительного разбиения, т. е. сначала разбиение на части, а затем прохождение через модель встраивания. Сначала текст разрезается по таким параметрам, как предложение, абзац или заданная максимальная длина. Затем модель встраивания обрабатывает эти фрагменты один за другим с помощью таких методов, как объединение средних и жетон Поздний чанкинг - это процесс, при котором мы сначала проходим через модель Embedding, а затем чанкируем ее (вот что значит "поздний"). Late Chunking, с другой стороны, - это прохождение через модель Embedding перед ее измельчением (вот где смысл слова late - сначала векторизация, а потом измельчение), мы сначала берем модель Embedding трансформатор Слой применяется ко всему тексту, генерируя последовательность векторных представлений для каждой лексемы, содержащей богатую контекстную информацию. Затем эти векторные последовательности лексем равномерно объединяются, чтобы получить окончательный блок Embedding, учитывающий весь контекст текста.
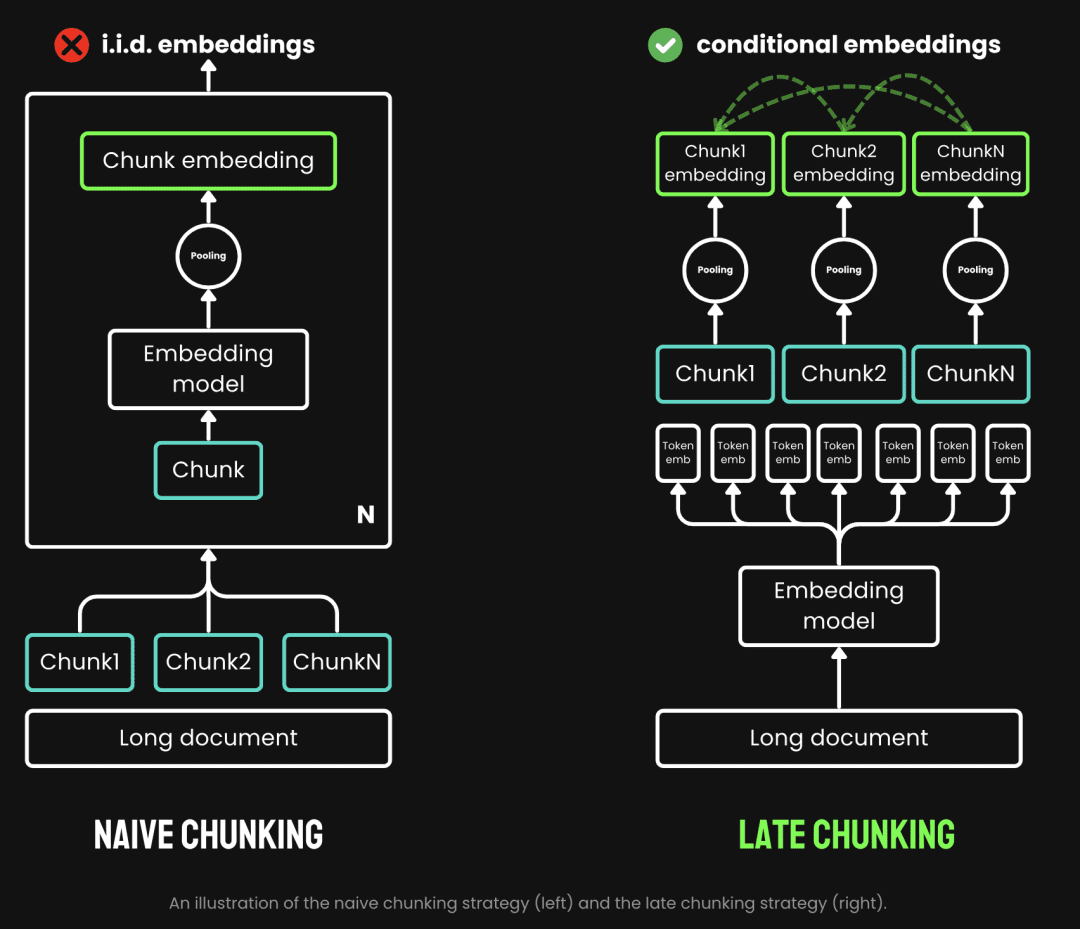
(Источник изображения: https://jina.ai/news/late-chunking-in-long-context-embedding-models/)
Поздний чанкинг генерирует блочное встраивание, где каждый блок кодирует больше контекстной информации, что повышает качество и точность кодирования. Мы можем поддерживать модели встраивания с длинным контекстом, поддерживая длинные контексты, такие как jina-embeddings-v2-base-enОн может обрабатывать до 8192 лексем текста (что эквивалентно 10 страницам бумаги формата А4), что в основном удовлетворяет контекстным требованиям большинства длинных текстов.
Таким образом, мы видим преимущества Late Chunking в приложениях RAG:
- Повышенная точность: благодаря сохранению контекстной информации Late Chunking возвращает более релевантный контент для запросов, чем простое разбиение.
- Эффективные вызовы LLM: Late Chunking сокращает объем текста, передаваемого в LLM, поскольку возвращает меньше и более релевантных фрагментов.
03.Тестирование поздней фрагментации
3.1. Реализация базы позднего чанкинга
Функция sentence_chunker для разбиения исходного документа на абзацы, возвращает содержимое фрагментов и информацию о разметке фрагментов span_annotations (то есть начало и конец разметки фрагментов)
def sentence_chunker(document, batch_size=10000):
nlp = spacy.blank("en")
nlp.add_pipe("sentencizer", config={"punct_chars": None})
doc = nlp(document)
docs = []
for i in range(0, len(document), batch_size):
batch = document[i : i + batch_size]
docs.append(nlp(batch))
doc = Doc.from_docs(docs)
span_annotations = []
chunks = []
for i, sent in enumerate(doc.sents):
span_annotations.append((sent.start, sent.end))
chunks.append(sent.text)
return chunks, span_annotations
Функция document_to_token_embeddings передает модель jinaai/jina-embeddings-v2-base-en модель, а также токенизатор, который возвращает Embedding всего документа.
def document_to_token_embeddings(model, tokenizer, document, batch_size=4096): tokenized_document = tokenizer(document, return_tensors="pt") tokens = tokenized_document.tokens() outputs = [] for i in range(0, len(tokens), batch_size): start = i end = min(i + batch_size, len(tokens)) batch_inputs = {k: v[:, start:end] for k, v in tokenized_document.items()} with torch.no_grad(): model_output = model(**batch_inputs) outputs.append(model_output.last_hidden_state) model_output = torch.cat(outputs, dim=1) return model_output
Функция late_chunking разбивает на куски вкрапления всего документа, а также информацию о разметке span_annotations исходных кусков.
def late_chunking(token_embeddings, span_annotation, max_length=None): outputs = [] for embeddings, annotations in zip(token_embeddings, span_annotation): if ( max_length is not None ): annotations = [ (start, min(end, max_length - 1)) for (start, end) in annotations if start < (max_length - 1) ] pooled_embeddings = [] for start, end in annotations: if (end - start) >= 1: pooled_embeddings.append( embeddings[start:end].sum(dim=0) / (end - start) ) pooled_embeddings = [ embedding.detach().cpu().numpy() for embedding in pooled_embeddings ] outputs.append(pooled_embeddings) return outputs
Если используется модельjinaai/jina-embeddings-v2-base-enВыполните позднюю расчлененку
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
# First chunk the text as normal, to obtain the beginning and end points of the chunks.
chunks, span_annotations = sentence_chunker(document)
# Then embed the full document.
token_embeddings = document_to_token_embeddings(model, tokenizer, document)
# Then perform the late chunking
chunk_embeddings = late_chunking(token_embeddings, [span_annotations])[0]
3.2. Сравнение с традиционными методами встраивания
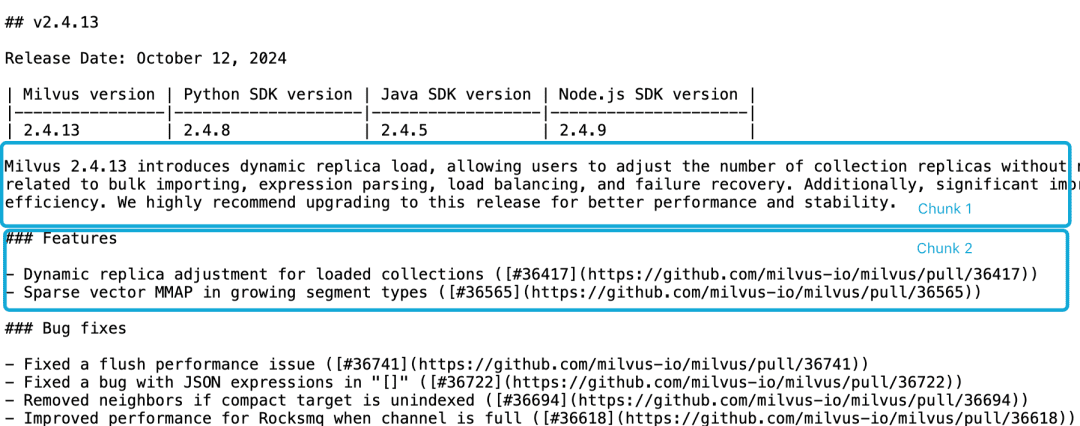
В качестве примера возьмем релиз milvus 2.4.13.
В Milvus 2.4.13 появилась динамическая загрузка реплик, позволяющая пользователям изменять количество реплик коллекции без необходимости освобождать и перезагружать коллекцию. коллекцию.
В этой версии также исправлено несколько критических ошибок, связанных с массовым импортом, разбором выражений, балансировкой нагрузки и восстановлением после сбоев.
Кроме того, были внесены значительные улучшения в использование ресурсов MMAP и производительность импорта, что повысило общую эффективность системы.
Мы настоятельно рекомендуем перейти на этот выпуск для повышения производительности и стабильности.
Традиционное встраивание, т.е. разбиение на куски с последующим встраиванием, и встраивание с использованием позднего подхода, т.е. встраивание с последующим разбиением на куски, выполняются соответственно. Затем milvus 2.4.13 Сравните полученные результаты с результатами двух подходов к встраиванию, соответственно
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
milvus_embedding = model.encode('milvus 2.4.13')
for chunk, late_chunking_embedding, traditional_embedding in zip(chunks, chunk_embeddings, embeddings_traditional_chunking):
print(f'similarity_late_chunking("milvus 2.4.13", "{chunk}")')
print('late_chunking: ', cos_sim(milvus_embedding, late_chunking_embedding))
print(f'similarity_traditional("milvus 2.4.13", "{chunk}")')
print('traditional_chunking: ', cos_sim(milvus_embedding, traditional_embeddings))
Судя по результатам, слова milvus 2.4.13 Сходство результатов Late Chunking с разбитыми на фрагменты документами выше, чем у традиционного встраивания, потому что Late Chunking сначала выполняет встраивание для всего текстового фрагмента, в результате чего весь текстовый фрагмент получает milvus 2.4.13 информации, что, в свою очередь, значительно улучшает сходство при последующих сравнениях текстов.
similarity_late_chunking("milvus 2.4.13", "Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.")
late_chunking: 0.8785206
similarity_traditional("milvus 2.4.13", "Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.")
traditional_chunking: 0.8354263
similarity_late_chunking("milvus 2.4.13", "This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.")
late_chunking: 0.84828955
similarity_traditional("milvus 2.4.13", "This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.")
traditional_chunking: 0.7222632
similarity_late_chunking("milvus 2.4.13", "Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.")
late_chunking: 0.84942204
similarity_traditional("milvus 2.4.13", "Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.")
traditional_chunking: 0.6907381
similarity_late_chunking("milvus 2.4.13", "We highly recommend upgrading to this release for better performance and stability.")
late_chunking: 0.85431844
similarity_traditional("milvus 2.4.13", "We highly recommend upgrading to this release for better performance and stability.")
traditional_chunking: 0.71859795
3.3. Тестирование позднего чанкинга в Milvus
Импорт данных позднего чанкинга в Milvus
batch_data=[]
for i in range(len(chunks)):
data = {
"content": chunks[i],
"embedding": chunk_embeddings[i].tolist(),
}
batch_data.append(data)
res = client.insert(
collection_name=collection,
data=batch_data,
)
Тестирование запросов
Мы определяем метод запроса по косинусному сходству, а также используем метод нативного запроса Milvus для позднего чанкинга соответственно.
def late_chunking_query_by_milvus(query, top_k = 3):
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
res = client.search(
collection_name=collection,
data=[query_vector.tolist()],
limit=top_k,
output_fields=["id", "content"],
)
return [item.get("entity").get("content") for items in res for item in items]
def late_chunking_query_by_cosine_sim(query, k = 3):
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
results = np.empty(len(chunk_embeddings))
for i, (chunk, embedding) in enumerate(zip(chunks, chunk_embeddings)):
results[i] = cos_sim(query_vector, embedding)
results_order = results.argsort()[::-1]
return np.array(chunks)[results_order].tolist()[:k]
Судя по результатам, оба метода возвращают одинаковое содержимое, что говорит о том, что результаты запроса Late Chunking in Milvus являются точными.
> late_chunking_query_by_milvus("What are new features in milvus 2.4.13", 3)
['nn### Featuresnn- Dynamic replica adjustment for loaded collections ([#36417](https://github.com/milvus-io/milvus/pull/36417))n- Sparse vector MMAP in growing segment types ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
> late_chunking_query_by_cosine_sim("What are new features in milvus 2.4.13", 3)
['nn### Featuresnn- Dynamic replica adjustment for loaded collections ([#36417](https://github.com/milvus-io/milvus/pull/36417))n- Sparse vector MMAP in growing segment types ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
04.резюме
Мы рассказываем о предыстории, основных концепциях и базовой реализации Late Chunking, как она возникла, а затем выясняем, что Late Chunking хорошо работает, тестируя его в Mivlus. В целом, сочетание точности, эффективности и простоты реализации делает Late Chunking эффективным подходом для приложений RAG.
Ссылка.
- https://stackoverflow.blog/2024/06/06/breaking-up-is-hard-to-do-chunking-in-rag-applications
- https://jina.ai/news/late-chunking-in-long-context-embedding-models/
- https://jina.ai/news/what-late-chunking-really-is-and-what-its-not-part-ii/
Код примера:
Ссылка: https://pan.baidu.com/s/1cYNfZTTXd7RwjnjPFylReg?pwd=1234 Код извлечения: 1234 Код работает на машине aws g4dn.xlarge
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...