Кими запускает MoBA: прорыв в создании бесконечного контекста!

Смешение экспертов и разреженное внимание делают возможным практически неограниченное количество контекстов. Это позволяет ИИ-агенту RAG поглощать целые кодовые базы и документы без контекстных ограничений.
📌 Вызов длительного контекстного внимания
Когда последовательности становятся очень большими, трансформаторы все равно сталкиваются с большой вычислительной нагрузкой. Модель внимания по умолчанию принимает каждую жетон Сравнение со всеми остальными лексемами приводит к квадратичному увеличению вычислительных затрат. Эти накладные расходы становятся проблемой при чтении целых баз кодов, многоглавых документов или больших объемов юридического текста.
📌 MoBA
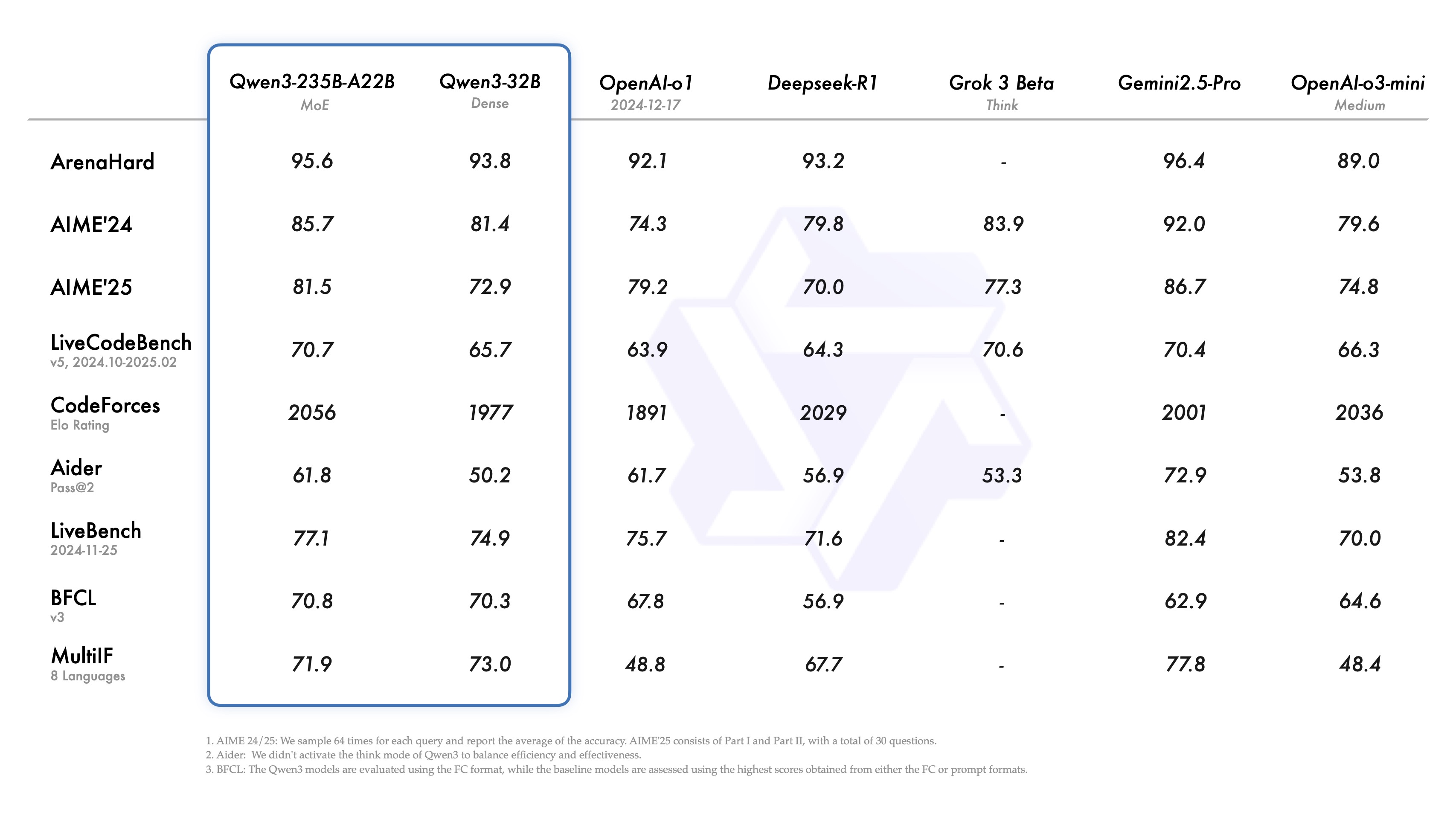
MoBA (Mixture of Block Attention) применяет концепцию Mixture of Experts к механизму внимания. Модель делит входную последовательность на несколько блоков, а затем обучаемая функция контроля вычисляет балл корреляции между каждой лексемой запроса и каждым блоком. При вычислении внимания используются только блоки с наибольшим количеством баллов, что позволяет избежать внимания к каждой лексеме в полной последовательности.
Блоки определяются путем разбиения последовательности на равные отрезки. Каждый маркер запроса рассматривает агрегированное представление ключей в каждом блоке (например, с помощью объединения средних), а затем ранжирует их важность, выбирая несколько блоков для детального вычисления внимания. Блок, содержащий запрос, выбирается всегда. Каузальная маскировка гарантирует, что маркеры не увидят будущую информацию, сохраняя порядок генерации слева направо.
📌 Плавное переключение между раздельным и полным вниманием
MoBA заменяет стандартный механизм внимания, но не меняет количество параметров. Он похож на стандартный Трансформатор Интерфейсы совместимы, поэтому разреженное и полное внимание можно переключать между разными слоями или этапами обучения. Некоторые слои могут резервировать полное внимание для решения специфических задач (например, для тонкой настройки под наблюдением), в то время как большинство слоев используют MoBA для снижения вычислительных затрат.
📌 Это применимо к большим стекам трансформеров, заменяя стандартные вызовы внимания. Механизм стробирования гарантирует, что каждый запрос фокусируется только на небольшом количестве блоков. Причинность обрабатывается путем фильтрации будущих блоков и применения локальной маски в текущем блоке запроса.
📌 На рисунке ниже показано, что запрос направляется только к нескольким "экспертным" блокам ключей/значений, а не ко всей последовательности. Механизм стробирования назначает каждый запрос наиболее релевантному блоку, тем самым снижая сложность вычисления внимания с квадратичной до субквадратичной.
📌 Механизм контроля вычисляет показатель корреляции между каждым запросом и когерентным представлением каждого блока. Затем он выбирает k блоков с наивысшей оценкой для каждого запроса, независимо от того, насколько далеко в последовательности они находятся.
Поскольку на один запрос обрабатывается всего несколько блоков, вычисления остаются субквадратичными, но модель все равно может переходить к лексемам, расположенным далеко от текущего блока, если показатель стробирования показывает высокую корреляцию.
Реализация PyTorch
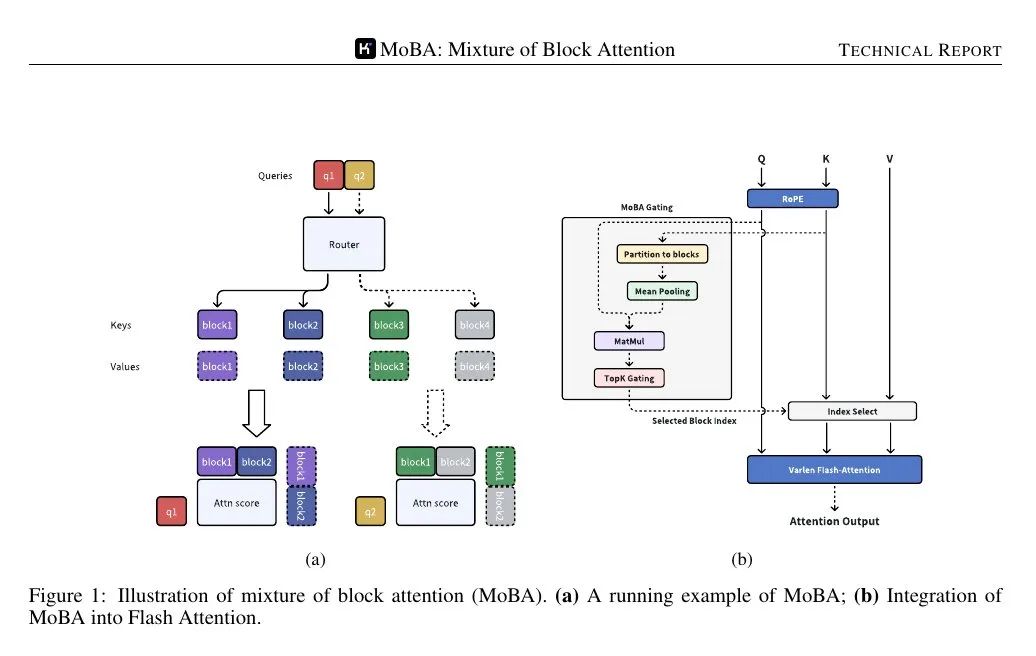
Этот псевдокод делит ключи и значения на блоки, вычисляет среднее объединенное представление каждого блока и рассчитывает оценку стробирования (S) путем умножения запроса (Q) на объединенное представление.
📌 Затем он применяет каузальные маски для того, чтобы запросы не фокусировались на будущих блоках, использует оператор top-k для выбора наиболее релевантных блоков для каждого запроса и организует данные для эффективного вычисления внимания.
📌 ВспышкаВнимание были применены к блоку самовнимания (текущая позиция) и блоку, выбранному MoBA, соответственно, и, наконец, результаты были объединены с помощью онлайн softmax.
📌 Конечным результатом является механизм разреженного внимания, который сохраняет причинно-следственную структуру и фиксирует дальние зависимости, избегая при этом квадратичных вычислительных затрат стандартного внимания.

Этот код сочетает в себе логику "смесь экспертов" с разреженным вниманием, так что каждый запрос фокусируется только на нескольких блоках.
Механизм контроля оценивает каждый блок и запрос и выбирает k лучших "экспертов", тем самым сокращая количество сравнений ключ/значение.
Таким образом, вычислительные затраты на внимание остаются на субквадратичном уровне, что позволяет обрабатывать очень длинные входные данные без увеличения нагрузки на вычислительную систему и память.
В то же время, механизм ограничения гарантирует, что при необходимости запрос сможет сфокусироваться на удаленных лексемах, тем самым сохраняя способность трансформатора обрабатывать глобальный контекст.
Эта стратегия, основанная на блоках и стробировании, в точности соответствует тому, как MoBA реализует почти бесконечные контексты в LLM.

Экспериментальные наблюдения
Модели, использующие MoBA, практически сопоставимы с полным вниманием с точки зрения потерь при моделировании языка и выполнения последующих задач. Результаты согласуются даже с длиной контекста в сотни тысяч или миллионы лексем. Эксперименты с "хвостовыми лексемами" подтверждают, что важные зависимости на большом расстоянии все еще улавливаются, когда запрос определяет соответствующие фрагменты.
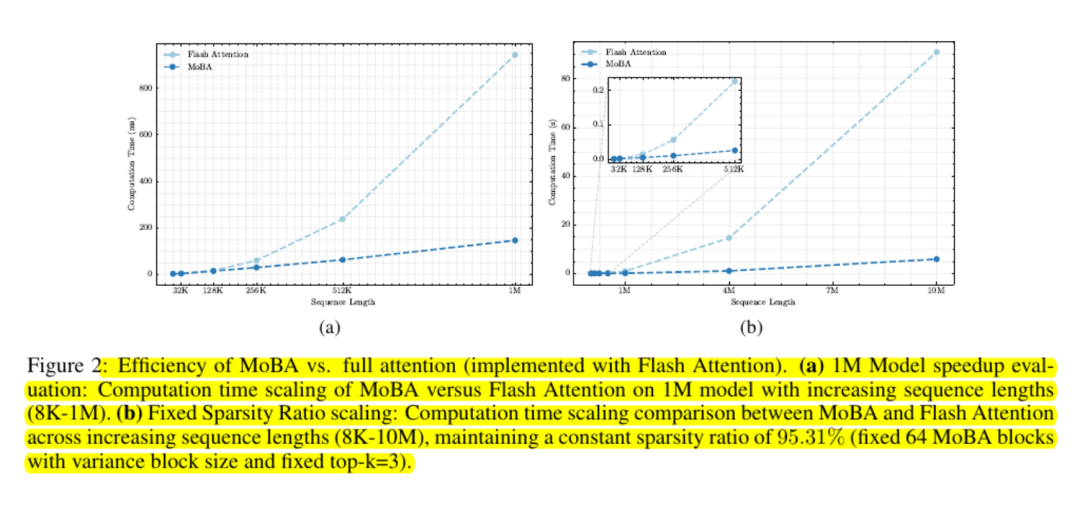
Тесты на масштабируемость показывают, что кривая затрат является субквадратичной. Исследователи сообщают об ускорении до шести раз при одном миллионе токенов и о более значительном приросте за пределами этого диапазона.
MoBA поддерживает удобство работы с памятью, избегая использования полных матриц внимания и используя стандартные ядра GPU для вычислений на основе блоков.
Заключительные замечания
MoBA снижает нагрузку на внимание благодаря простой идее: пусть запрос узнает, какие блоки являются важными, и игнорирует все остальные.
Он сохраняет стандартный интерфейс внимания на основе softmax и позволяет избежать навязывания жесткой локальной модели. Многие крупные языковые модели могут интегрировать этот механизм по принципу plug-and-play.
Это делает MoBA очень привлекательным для рабочих нагрузок, в которых необходимо работать с очень длинными контекстами, такими как сканирование всей кодовой базы или резюмирование огромных документов, без необходимости вносить серьезные изменения в веса предварительного обучения или тратить много времени на переобучение.

© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...