Kats: набор инструментов для анализа временных рядов данных и прогнозирования будущих тенденций в данных

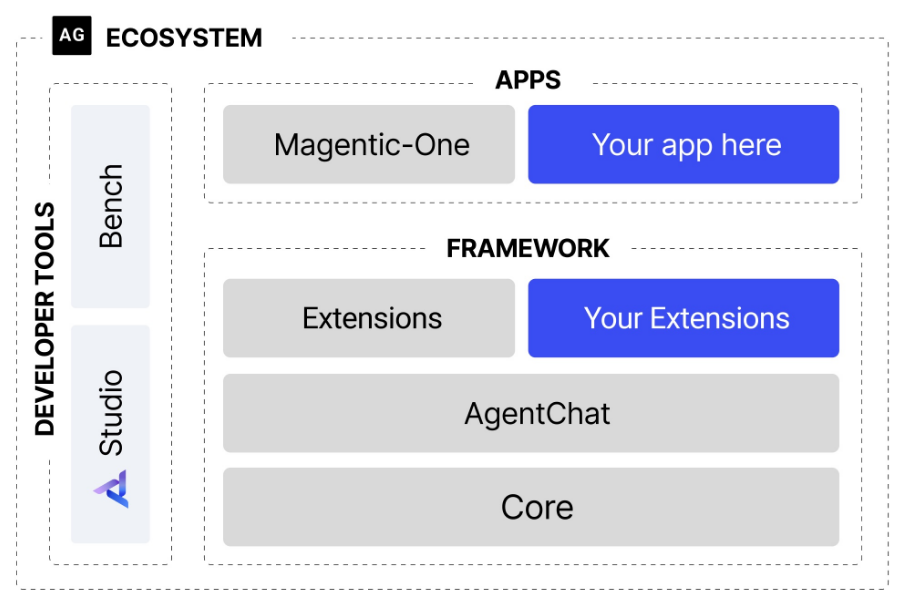
Общее введение
Kats - это набор инструментов с открытым исходным кодом, разработанный группой исследователей из Meta (ранее Facebook) и предназначенный для анализа временных рядов. Kats представляет собой легкую и простую в использовании структуру, которая охватывает широкий спектр функций - от базового статистического анализа до сложного прогнозного моделирования, обнаружения аномалий и извлечения признаков. Будь вы специалист по анализу данных или инженер, Kats поможет вам более эффективно обрабатывать и изучать данные временных рядов. Он не только поддерживает широкий спектр моделей, но и предоставляет богатые учебные пособия и примеры, чтобы помочь пользователям быстро начать работу.

Список функций
- Анализ временных рядов данных: Обеспечить понимание и анализ основных статистических характеристик.
- Обнаружение точки изменения: Определение точек изменения в данных временного ряда.
- обнаружение аномалий: Обнаружение выбросов в данных временного ряда.
- Прогнозы тенденций: Использование нескольких моделей для прогнозирования будущих тенденций.
- Извлечение и встраивание признаков: Извлечение полезных свойств из данных временного ряда.
- многомерный анализ: Поддержка анализа многомерных временных рядов.
Использование помощи
Процесс установки
Kats можно установить через PyPI, вот подробные шаги по установке:
- Обновить пипл:
pip install --upgrade pip
- Установите катсы:
pip install kats
- Если вам нужны только некоторые функции Kats, вы можете установить lite-версию:
MINIMAL_KATS=1 pip install kats
Руководство по использованию
Анализ временных рядов данных
- Импортируйте необходимые библиотеки и данные:
import pandas as pd
from kats.consts import TimeSeriesData
from kats.models.prophet import ProphetModel, ProphetParams
# 读取数据
air_passengers_df = pd.read_csv("path/to/air_passengers.csv", header=0, names=["time", "passengers"])
air_passengers_ts = TimeSeriesData(air_passengers_df)
- Создание и обучение прогностических моделей:
params = ProphetParams(seasonality_mode='multiplicative')
model = ProphetModel(air_passengers_ts, params)
model.fit()
- Делайте прогнозы:
forecast = model.predict(steps=30, freq="MS")
Обнаружение точки изменения
- Представляем алгоритмы обнаружения точек изменения:
from kats.detectors.cusum_detection import CUSUMDetector
# 模拟时间序列数据
df_increase = pd.DataFrame({'time': pd.date_range('2019-01-01', '2019-03-01'), 'value': np.random.randn(60).cumsum()})
ts = TimeSeriesData(df_increase)
# 进行变化点检测
detector = CUSUMDetector(ts)
change_points = detector.detector()
обнаружение аномалий
- Импорт алгоритмов обнаружения аномалий:
from kats.detectors.bocpd import BOCPDetector
# 使用模拟数据进行异常检测
detector = BOCPDetector(ts)
anomalies = detector.detector()
Рекомендации по использованию
- Предварительная обработка данных: убедитесь в чистоте данных временных рядов и устраните недостающие значения или выбросы, чтобы повысить точность анализа.
- Выбор модели: выберите подходящую модель в соответствии с характеристиками ваших данных. kats предоставляет несколько моделей, и вы можете найти наиболее подходящую путем экспериментов.
- Визуализация: используйте встроенные в Kats возможности визуализации для понимания закономерностей данных и производительности модели, что полезно при анализе и составлении отчетов о результатах.
- Оценка производительности: оценка производительности различных моделей и выбор наилучших гиперпараметров перед применением модели.
Решение распространенных проблем
- Проблемы с установкой: Если во время установки вы столкнулись с конфликтами зависимостей, попробуйте установить в виртуальной среде или ознакомьтесь с FAQ на официальной странице Kats на GitHub.
- Проблемы с форматом данных: если формат ваших данных отличается от ожидаемого Kats, это может привести к ошибке. Убедитесь, что имена столбцов данных правильные, а типы данных соответствуют требованиям.
- Вопросы производительности: для больших массивов данных следует рассмотреть возможность выборки данных или использовать более эффективные модели для сокращения времени вычислений.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...