
Мини-модель с открытым исходным кодом 1.6B "Little Fox", превосходящая аналогичные модели Qwen и Gemma


с (какого-то времени) Чатгпт С момента своего появления количество параметров LLM (Large Language Models) кажется гонкой на понижение для каждой компании. Количество параметров GPT-1 составляло 117 миллионов (117M), а его четвертое поколение, GPT-4, обновилось до 1,8 триллиона (1800B).
Как и в других моделях LLM, таких как Bloom (176 миллиардов, 176B) и Chinchilla (70 миллиардов, 70B), количество параметров также постоянно растет. Количество параметров напрямую влияет на производительность и возможности модели: большее количество параметров означает, что модель способна обрабатывать более сложные языковые модели, понимать более богатую контекстную информацию и демонстрировать более высокий уровень интеллекта в широком спектре задач.
Однако эти огромные параметры также напрямую влияют на стоимость обучения и среду разработки LLM, и ограничивают возможности изучения LLM большинством исследовательских компаний, в результате чего большие языковые модели постепенно превращаются в гонку вооружений между крупными компаниями.
Недавно компания TensorOpera, специализирующаяся на разработке искусственного интеллекта, выпустилаМалые языковые модели FOX с открытым исходным кодомдоказывая индустрии, что малые языковые модели (SLM) могут проявить себя и в области интеллигенции.

FOX - этоМалые языковые модели, предназначенные для облачных и краевых вычислений. В отличие от больших языковых моделей с десятками миллиардов параметров, FOX Всего 1,6 миллиарда параметровЭто отличный способ получить максимальную отдачу от компьютера, а также продемонстрировать потрясающую производительность при выполнении нескольких задач.
Название диссертации:
ТЕХНИЧЕСКИЙ ОТЧЕТ ПО ЛИСЕ-1
Ссылка на статью:
https://arxiv.org/abs/2411.05281

Кто такой TensorOpera?
TensorOpera - инновационная компания в области искусственного интеллекта, базирующаяся в Кремниевой долине, штат Калифорния. Ранее они разработали экосистему генеративного искусственного интеллекта TensorOpera® AI Platform и платформу федерального обучения и аналитики TensorOpera® FedML. Название компании, TensorOpera, - это сочетание технологии и искусства, символизирующее разработку компанией GenAI мультимодальных и мультимодельных композитных систем искусственного интеллекта.

Доктор Джаред Каплан, соучредитель и генеральный директор TensorOpera, сказал: "Модель FOX была изначально разработана для значительного снижения требований к вычислительным ресурсам при сохранении высокой производительности. Это не только делает технологию искусственного интеллекта более доступной, но и снижает барьер использования для предприятий".
Как работает модель Fox?
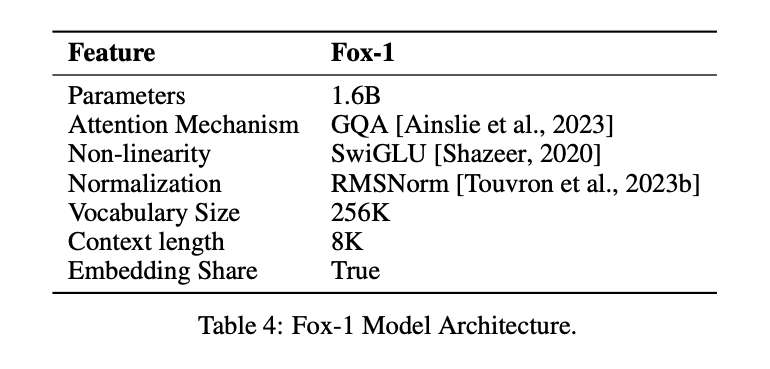
Для достижения того же эффекта, что и в LLM, при меньшем количестве параметров, модель Fox-1Только декодерархитектуру и вносит различные улучшения и изменения для повышения производительности. К ним относятся
① сетевой уровень: При разработке архитектуры модели более широкие и мелкие нейронные сети обладают лучшими возможностями памяти, а более глубокие и тонкие сети - более сильными возможностями вывода. Следуя этому принципу, Fox-1 использует более глубокую архитектуру, чем большинство современных SLM. В частности, Fox-1 состоит из 32 самоаттентивных слоев, что на 781 TP3T глубже, чем Gemma-2B (18 слоев), и на 331 TP3T глубже, чем StableLM-2-1.6B (24 слоя) и Qwen1.5-1.8B (24 слоя).
② Совместное встраиваниеВ модели Fox-1 используется 2 048 скрытых измерений для создания 256 000 словарей с примерно 500 миллионами параметров. Более крупные модели обычно используют отдельные слои встраивания для входного слоя (словарь - встроенные выражения) и выходного слоя (встроенные выражения - словарь). Для Fox-1 один только слой встраивания требует 1 миллиард параметров. Чтобы уменьшить общее число параметров, совместное использование входного и выходного слоев встраивания позволяет максимально эффективно использовать вес.
(iii) преднормализацияFox-1 использует RMSNorm для нормализации входов каждого слоя преобразования; RMSNorm является предпочтительным выбором для предварительной нормализации в современных крупномасштабных языковых моделях, и он демонстрирует лучшую эффективность, чем LayerNorm.
④ Поворотное позиционное кодирование (RoPE): Fox-1 по умолчанию принимает входные лексемы длиной до 8K, и для повышения производительности в более длинных контекстных окнах Fox-1 использует позиционное кодирование с поворотом, где θ устанавливается на 10,000 для кодирования жетон Относительная позиционная зависимость между
⑤ Групповое внимание по запросу (GQA)Группированное внимание к запросам разделяет головки запросов многоголового слоя внимания на группы, каждая из которых использует один и тот же набор головок ключ-значение. Fox-1 оснащен 4 головками ключ-значение и 16 головками внимания, что позволяет увеличить скорость обучения и вывода и уменьшить потребление памяти.
В дополнение к моделированию структурных улучшений.FOX-1 также улучшает процесс токенизации и обучения..
часть речи (в китайской грамматике)В Fox-1 используется классификатор Gemma на основе SentencePiece, который обеспечивает объем словарного запаса 256K. Увеличение объема словаря имеет, по крайней мере, два основных преимущества. Во-первых, увеличивается длина скрытой информации в контексте, поскольку каждая лексема кодирует более плотную информацию. Например, словарь размером 26 может кодировать только один символ [a-z], а словарь размером 262 может кодировать две буквы одновременно, что позволяет представлять более длинные строки в токенах фиксированной длины. Во-вторых, больший объем словарного запаса снижает вероятность появления неизвестных слов или фраз, что приводит к улучшению практического выполнения задачи. Большой словарный запас, используемый Fox-1, позволяет использовать меньшее количество лексем для данного корпуса текстов, что обеспечивает лучшую производительность в области умозаключений.
Лиса-1Данные предварительного обученияИсточник - наборы данных Redpajama, SlimPajama, Dolma, Pile и Falcon общим объемом 3 триллиона текстовых данных. Чтобы уменьшить неэффективность предварительного обучения для длинных последовательностей, обусловленную механизмом внимания, Fox-1 вводит на этапе предварительного обученияТрехфазная стратегия изучения учебной программыFox-1 - это трехфазный конвейер предварительного обучения, в котором длина чанка обучающих образцов постепенно увеличивается с 2К до 8К, чтобы обеспечить большие контекстные возможности при небольших затратах. Чтобы соответствовать трехфазному конвейеру предварительного обучения, Fox-1 реорганизует исходные данные в три различных набора, включая наборы данных без надзора и наборы данных для настройки инструкций, а также данные из различных доменов, таких как код, веб-контент, математические и научные документы.
Тренировку Fox-1 можно разделить на три этапа.
- Первая фаза включает в себя около 39% образцов данных в процессе предварительного обучения, где 1,05 триллиона токенов разбивается на образцы длиной 2 000, с размером партии 2 M. На этой фазе используется линейная разминка 2 000epoch.
- Второй этап включает около 59% образцов с 1,58 триллионами токенов и увеличивает длину чанка с 2K до 4K и 8K. Фактическая длина чанка варьируется в разных источниках данных. Учитывая, что второй этап занимает больше всего времени и включает разные источники из разных наборов данных, размер пакета также увеличен до 4 М, чтобы повысить эффективность обучения.
- Наконец, на третьем этапе модель Fox обучается на 6,2 миллиардах лексем (около 0,02% от общего количества) высококачественных данных, закладывая основу для различных возможностей последующих задач, таких как выполнение команд, светская беседа, вопросы и ответы по конкретной области и так далее.
Как выступил Fox-1?
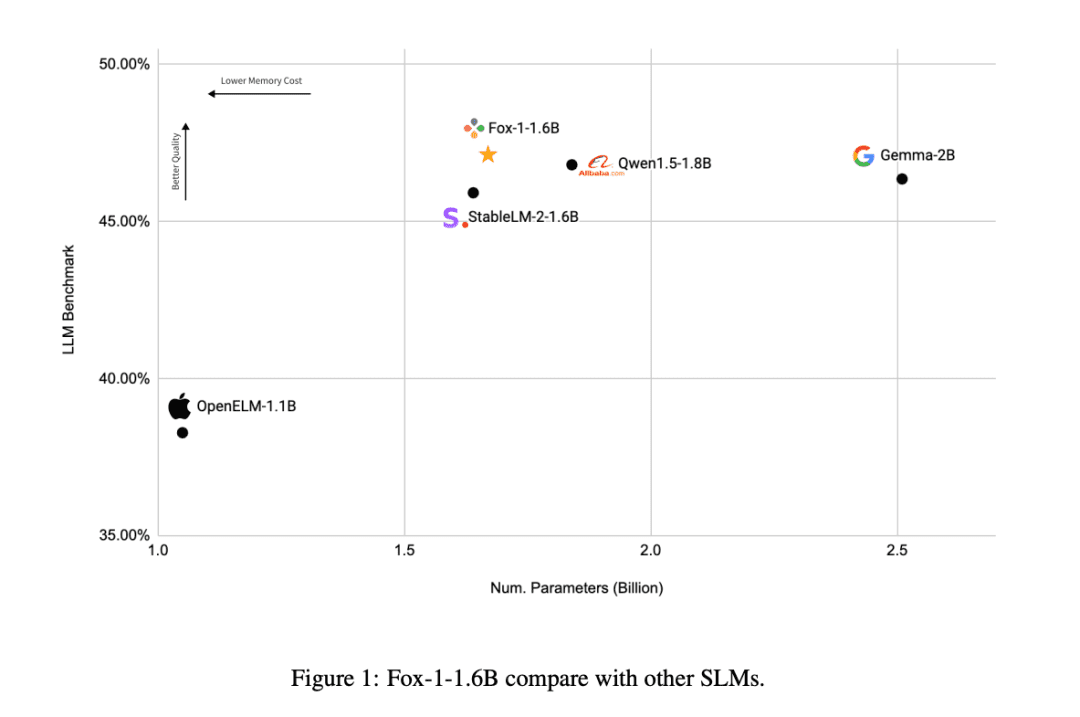
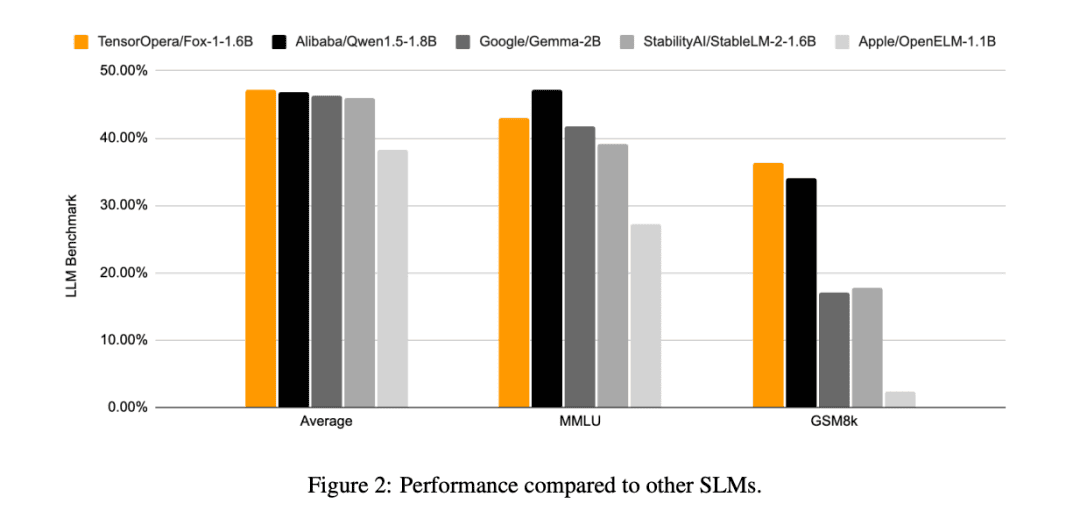
По сравнению с другими моделями SLM (Gemma-2B, Qwen1.5-1.8B, StableLM-2-1.6B и OpenELM1.1B), FOX-1 более успешна в ARC Challenge (25 выстрелов), HellaSwag (10 выстрелов), TruthfulQA (0 выстрелов), MMLU (5 выстрелов), Winogrande (5 выстрелов), GSM8k (5 выстрелов), GSM8k (5 выстрелов), GSM8k (5 выстрелов) и GSM8k (5 выстрелов). MMLU (5-shot), Winogrande (5-shot), GSM8k (5-shot)Средние оценки бенчмарка для шести задач были самыми высокими и значительно лучше на GSM8k.
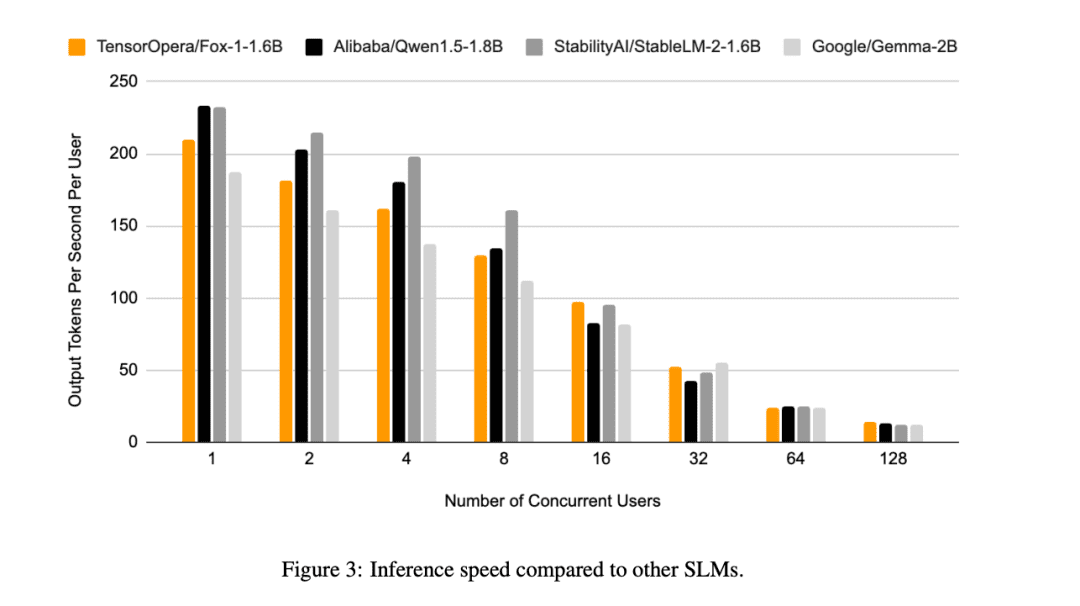
Кроме того, TensorOpera оценила Fox-1, Qwen1.5-1.8B и Gemma-2B, используя vLLM Эффективность сквозных вычислений с помощью платформы TensorOpera Service Platform на одном NVIDIA H100.
Fox-1 достигает пропускной способности более 200 токенов в секунду, превосходя Gemma-2B и соответствуя Qwen1.5-1.8B в той же среде развертывания. При точности BF16 Fox-1 требует всего 3703 Мбайт памяти GPU, в то время как Qwen1.5-1.8B, StableLM-2-1.6B и Gemma-2B - 4739 Мбайт, 3852 Мбайт и 5379 Мбайт, соответственно.
Небольшие параметры, но все еще конкурентоспособные
В то время как все компании, занимающиеся разработкой ИИ, сейчас соревнуются в создании больших языковых моделей, TensorOpera выбрала другой подход, прорвавшись в область SLM, достигнув результатов, схожих с LLM, при объеме всего 1,6 ББ, и показав хорошие результаты в различных бенчмарках.
Даже при ограниченных ресурсах данных TensorOpera может проводить предварительное обучение языковых моделей с конкурентоспособной производительностью, предлагая новый способ мышления для других компаний, занимающихся разработкой ИИ.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...