
Свернуть! Векторные модели длинных текстов Стратегии чанкинга Конкуренция

Векторная модель длинного текста способна закодировать десять страниц текста в один вектор, что звучит мощно, но так ли это на самом деле?
Многие думают... Не обязательно.
Можно ли использовать его напрямую? Должен ли он быть разбит на куски? Как разделить наиболее эффективные? В этой статье мы подробно рассмотрим различные стратегии разбиения на куски для векторных моделей длинных текстов, проанализируем плюсы и минусы и поможем вам избежать подводных камней.
Проблема векторизации длинных текстов
Для начала давайте посмотрим, какие проблемы возникают при сжатии целой статьи в один вектор.
В качестве примера построения системы поиска документов можно привести одну статью, которая может содержать несколько тем. Например, в этом блоге, посвященном докладу участников ICML 2024, есть введение в конференцию, презентация работы Джины ИИ (jina-clip-v1) и резюме других научных работ. Если всю статью векторизовать в один вектор, то в этом векторе будет смешана информация из трех разных тем:
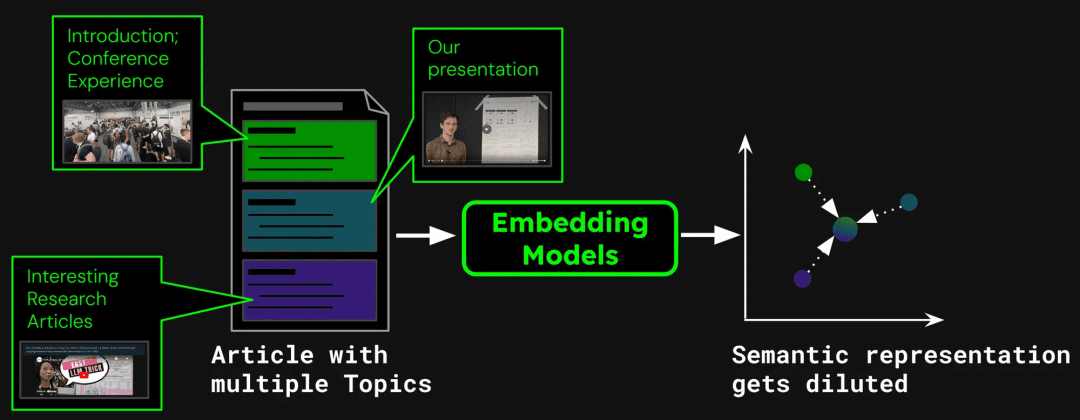
Это может привести к следующим проблемам:
1. Размывание репрезентативности
указывает на то, что разбавление ослабляет точность текстовых векторов. Хотя запись в блоге содержит несколько тем, вОднако поисковые запросы пользователей, как правило, сосредоточены только на одном из них. Представление всей статьи одним вектором эквивалентно сжатию всей информации о теме в одну точку в векторном пространстве. По мере добавления текста на вход модели этот вектор постепенно представляет общую тематику статьи, размывая детали отдельных отрывков или тем. Это похоже на смешивание нескольких пигментов в один цвет, что затрудняет пользователю выделение конкретного цвета из смеси при попытке его найти.
2. ограниченные возможности
Размеры вектора, создаваемого моделью, фиксированы, а длинный текст содержит много информации, что неизбежно приведет к ее потере в процессе преобразования. Это похоже на сжатие карты высокой четкости в почтовую марку, при котором многие детали не видны.
3. Потеря информации
Многие модели длинных текстов могут обрабатывать только до 8192 лексем. Более длинный текст придется обрезать, обычно в конце, и если ключевая информация находится в конце документа, поиск может оказаться неудачным.
4. требования к сегментации
Некоторые приложения нуждаются в векторизации только определенных сегментов текста, например, системы вопросов и ответов, где для векторизации нужно извлекать только абзацы, содержащие ответы. В этом случае все равно требуется разбиение текста на части.
3 Стратегии обработки длинных текстов
Прежде чем начать эксперимент, во избежание концептуальной путаницы, мы определим три стратегии работы с кусками:
1. Никакого чанкинга:Кодирует весь текст непосредственно в один вектор.
2. Наивный чанкинг:Сначала текст разбивается на несколько фрагментов и векторизуется по отдельности. Обычно используются такие методы, как разбиение на части фиксированного размера, при котором текст разбивается на фиксированные жетон количество фрагментов; фрагментация на основе предложений: фрагментация в предложениях; фрагментация на основе семантики: фрагментация на основе семантической информации. В данном эксперименте используются куски фиксированного размера.
3. Поздний чанкинг:Это новый метод чтения всего текста перед его разбивкой на куски, состоящий из двух основных этапов:
- Полный текст кодекса: Сначала кодируйте весь документ, чтобы получить векторное представление каждой лексемы, сохраняя полную информацию о контексте.
- объединение блоков: Генерирование векторов для каждого текстового блока путем усреднения векторов лексем одного текстового блока в соответствии с границей чанка. Поскольку вектор каждой лексемы генерируется в контексте полного текста, позднее разбиение может сохранить контекстную информацию между блоками.
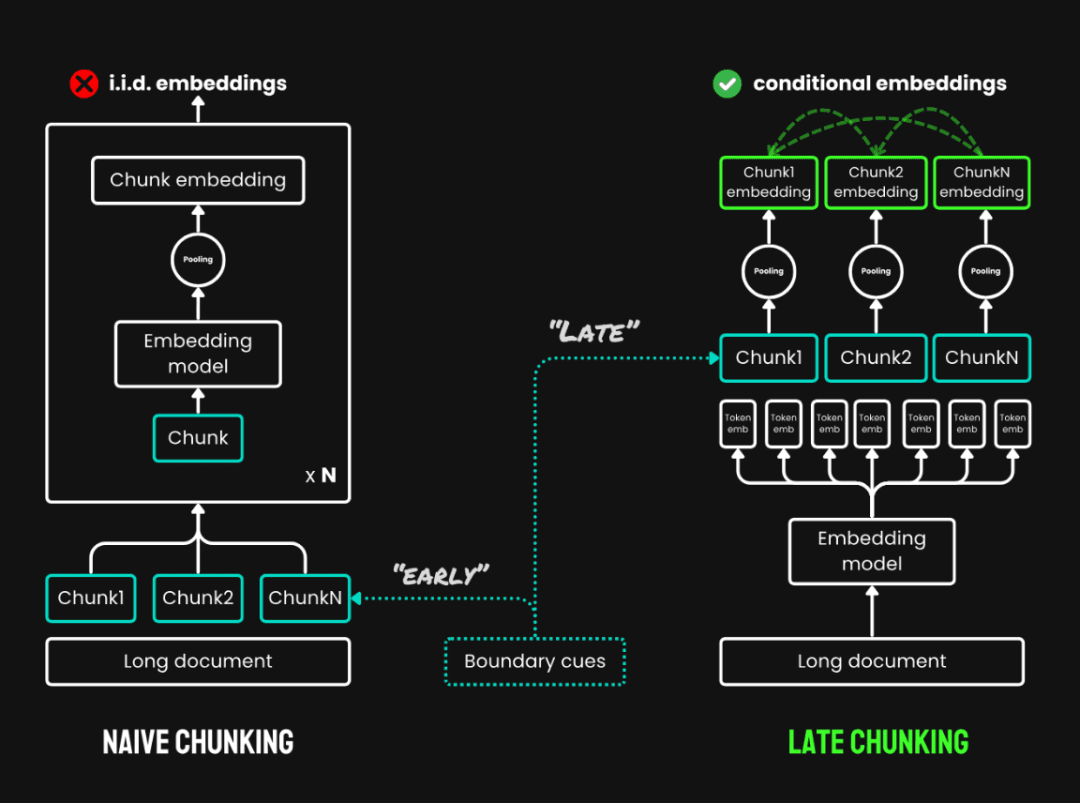
Позднее расщепление по сравнению с простым расщеплением
Для моделей, превышающих максимальную длину входного сигнала (например, 8192 жетоны), мы используем Длинный поздний чанкингК позднему расщеплению добавляется этап предварительной сегментации: сначала документ разбивается на несколько перекрывающихся макроблоков, каждый из которых имеет длину в пределах обрабатываемого диапазона модели. Затем внутри каждого макроблока применяется стандартная стратегия поздней сегментации (кодирование и объединение). Перекрытие между макроблоками используется для обеспечения непрерывности контекстной информации.
Поздняя оценка Код конкретного выполнения: https://github.com/jina-ai/late-chunking在 Опыт работы в тетради: https://colab.research.google.com/drive/1iz3ACFs5aLV2O_ uZEjiR1aHGlXqj0HY7?usp=sharing
Так какой же метод лучше?
Для сравнения мы использовали набор данных из 5 наборов данных, используя jina-embeddings-v3 Были проведены эксперименты, в которых все длинные тексты были обрезаны до максимальной длины входного сигнала модели (8192 токена) и сегментированы на текстовые блоки по 64 токена каждый.

5 тестовых наборов данных также соответствуют 5 различным задачам поиска
На рисунке ниже показана разница в производительности между тремя методами на разных задачах. Ни один метод не является лучшим во всех случаях, и выбор зависит от конкретной задачи.
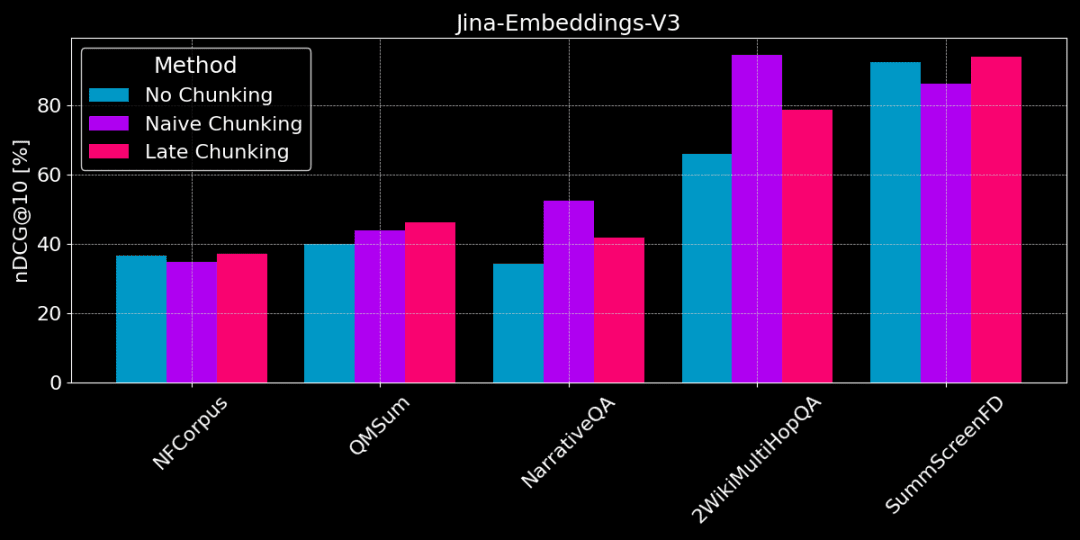
Отсутствие chunking vs простой chunking vs поздний chunking
👩🏫 Найдите конкретные факты, хорошо подходит простой кусок.
Если из текста необходимо извлечь конкретную, локализованную фактическую информацию (например, "Кто украл что-то?") ), таких наборов данных, как QMSum, NarrativeQA и 2WikiMultiHopQA, обычная выемка лучше, чем векторизация всего документа. Поскольку ответы обычно располагаются в определенной части текста, обычная разбивка может более точно определить местоположение фрагмента текста, содержащего ответ, не отвлекаясь на другую постороннюю информацию.
Но при простом разбиении на части контекст также отсекается, и может быть потеряна глобальная информация, необходимая для правильного разбора референциальных отношений и ссылок в тексте.
👩🏫 Статья тематически последовательна, а поздние оценки лучше.
Позднее деление на части более эффективно, если тема ясна, а структура текста последовательна. Поскольку при позднем делении учитывается контекст, оно позволяет лучше понять смысл и значимость каждой части, включая референциальные отношения в длинных текстах.
Однако если в статье много нерелевантного контента, то поздний подсчет будет учитывать "шум" и приведет к снижению производительности и точности. Например, NarrativeQA и 2WikiMultiHopQA работают не так хорошо, как обычный chunking, потому что в этих статьях слишком много нерелевантной информации.
Влияет ли размер куска?
На следующем рисунке показана производительность методов простой и поздней расчлененки на различных наборах данных с разными размерами фрагментов:
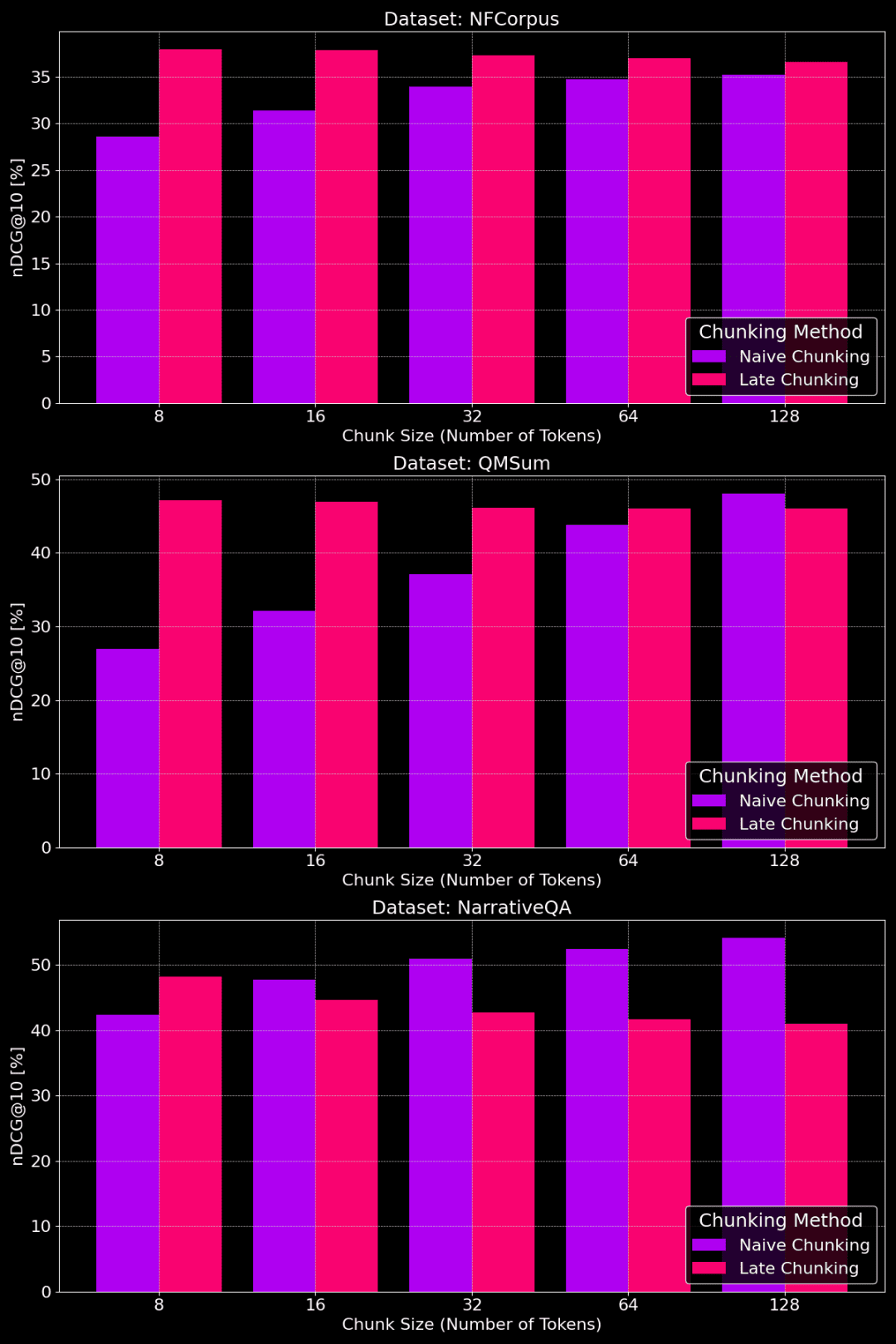
Сравнение производительности простой и поздней кусковой обработки для разных размеров кусков
Как видно из рисунка, оптимальный размер куска зависит от того, как выглядит конкретный набор данных.
Для метода позднего разбиения небольшие фрагменты лучше передают контекстную информацию и поэтому работают лучше. В частности, если в наборе данных много контента, не относящегося к теме (как в случае с набором данных NarrativeQA), слишком большой объем контекста может внести шум и снизить производительность.
При обычном разбиении на куски большие куски иногда работают лучше, потому что содержащаяся в них информация более полная и с меньшими потерями. Однако иногда куски слишком велики и информация слишком загромождена, что, в свою очередь, снижает точность поиска. Таким образом, оптимальный размер фрагмента должен подбираться в зависимости от конкретного набора данных и задачи, и универсального ответа не существует.
Разобравшись в преимуществах и недостатках различных стратегий разбивки на части, как выбрать правильную?
1. В каких случаях уместна полнотекстовая векторизация (без чанкинга)?
- Тема единая, ключевая информация сосредоточена в начале:Например, в структурированных новостных материалах ключевая информация часто содержится в заголовках и начальных абзацах. В этом случае прямое использование полнотекстовой векторизации обычно дает хорошие результаты, поскольку модель захватывает основную информацию.
- В целом, если в модель поместить как можно больше текстового контента, это не повлияет на результаты поиска. Однако модели длинных текстов склонны уделять больше внимания начальной части (заголовку, введению и т. д.), а информация в середине и конце может быть проигнорирована. Поэтому, если ключевая информация находится в середине или в конце статьи, этот метод будет гораздо менее эффективным.
- Подробные экспериментальные результаты приведены в статье:https://jina.ai/news/still-need-chunking-when-long-context-models-can-do-it-all
2. В каких случаях уместно использовать Naive Chunking?
- Разнообразие тем, необходимость получения конкретной информации: Если ваш текст содержит более одной темы или если запрос пользователя направлен на конкретный факт в тексте, простая разбивка на части - хороший выбор. Она позволяет эффективно избежать размывания информации и повысить точность поиска конкретной информации.
- Необходимо отображать локализованные фрагменты текста: Подобно поисковой системе, необходимость отображения в результатах запроса фрагментов текста, относящихся к запросу, обусловливает необходимость применения стратегии разбиения на части.
- Кроме того, разбивка на блоки влияет на объем памяти и время обработки, поскольку приходится векторизовать больше блоков текста.
3. Где используется поздний чанкинг?
- Тематическая согласованность, потребность в контекстной информации: Для длинных текстов со связными темами, таких как эссе, длинные отчеты и т. д., метод позднего разбиения может эффективно сохранять контекстную информацию и, таким образом, лучше понимать общую семантику текста. Он особенно подходит для задач, требующих понимания взаимосвязи между различными частями текста, таких как понимание прочитанного и семантическое сопоставление длинных текстов.
- Необходим баланс между локальными деталями и глобальной семантикой: Метод позднего разбиения может эффективно сбалансировать локальные детали и глобальную семантику при меньшем размере кусков и во многих случаях позволяет достичь лучших результатов, чем два других метода. Однако следует отметить, что если в статье много нерелевантного контента, поздняя разбивка повлияет на эффект из-за учета такой нерелевантной информации.
вынести вердикт
Выбор стратегии векторизации длинных текстов - сложный вопрос, не имеющий универсального решения, и требует учета характеристик данных и целей поиска, включая упомянутую ранее длину текста, количество тем и расположение ключевой информации.
В этой статье мы надеемся предоставить сравнительный анализ различных стратегий разбиения на части и дать некоторые рекомендации на основе экспериментальных результатов. В практическом применении вы можете сравнить больше экспериментов и выбрать наиболее подходящую стратегию для вашего сценария.
Если вас интересует векторизация длинных текстовjina-embeddings-v3Благодаря расширенным возможностям обработки длинных текстов, многоязыковой поддержке и позднему набору баллов его стоит попробовать.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...