Тонкая настройка модели DeepSeek R1 для обеспечения точной медицины в вопросах и ответах: раскрытие потенциала ИИ с открытым исходным кодом

DeepSeek Представили ряд продвинутых моделей вывода, чтобы оспорить позиции OpenAI в индустрии, иСовершенно бесплатно, без ограничений на использованиеПрограмма рассчитана на всех пользователей.
В этой статье мы описываем, как провести тонкую настройку модели DeepSeek-R1-Distill-Llama-8B с помощью набора данных Hugging Face's Medical Thinking Chain. Эта облегченная версия DeepSeek-R1 Модель, полученная путем тонкой настройки модели Llama 3 8B на данных, сгенерированных DeepSeek-R1, демонстрирует превосходные выводы по сравнению с оригинальной моделью.

Расшифровка DeepSeek R1
DeepSeek-R1 и DeepSeek-R1-Zero превосходят модель o1 от OpenAI в задачах по математике, программированию и логическим рассуждениям.Стоит отметить, что и R1, и R1-Zero - это модели с открытым исходным кодом..
DeepSeek-R1-Zero
DeepSeek-R1-Zero - это первая модель с открытым исходным кодом, обученная исключительно с помощью крупномасштабного обучения с усилением (RL), в отличие от традиционных моделей, использующих в качестве начального этапа Supervised Fine-Tuning (SFT). Этот инновационный подход позволяет моделям самостоятельно исследовать CoT (Chain-of-Thought) рассуждения, что дает им возможность решать сложные задачи и итеративно оптимизировать результат. Однако этот подход также создает некоторые проблемы, такие как возможное дублирование шагов рассуждения, снижение удобочитаемости и несоответствие стилей языка, что, в свою очередь, влияет на ясность и полезность модели.
DeepSeek-R1
Выпуск DeepSeek-R1 направлен на преодоление недостатков DeepSeek-R1-Zero. Благодаря введению данных холодного старта перед обучением с подкреплением, DeepSeek-R1 закладывает более прочный фундамент для задач как с выводом, так и без него. Эта многоступенчатая стратегия обучения позволяет DeepSeek-R1 достичь лидирующего уровня производительности по сравнению с OpenAI-o1 в математике, программировании и задачах на вывод, а также значительно улучшить читаемость и связность результатов.
Модель дистилляции DeepSeek
DeepSeek также представила семейство дистилляционных моделей. Эти модели меньше и эффективнее, но при этом сохраняют отличную производительность при выводе данных. Несмотря на то, что размер параметров варьируется от 1,5 до 70 Б, все эти модели сохраняют сильные возможности для вывода. Среди них DeepSeek-R1-Distill-Qwen-32B превосходит модель OpenAI-o1-mini в нескольких бенчмарках. Модели меньшего масштаба наследуют паттерны выводов больших моделей, что полностью демонстрирует эффективность техники дистилляции.
-1")
Тонкая настройка DeepSeek R1 в действии
1. конфигурация окружающей среды
В этом упражнении по тонкой настройке модели Kaggle была выбрана в качестве облачной IDE, поскольку Kaggle предоставляет бесплатные ресурсы GPU. Изначально было выбрано два графических процессора T4, но использовался только один. Если пользователи хотят выполнить тонкую настройку модели на локальном компьютере, им необходимо иметь как минимумВидеокарта RTX 3090 с 16 ГБ памяти..
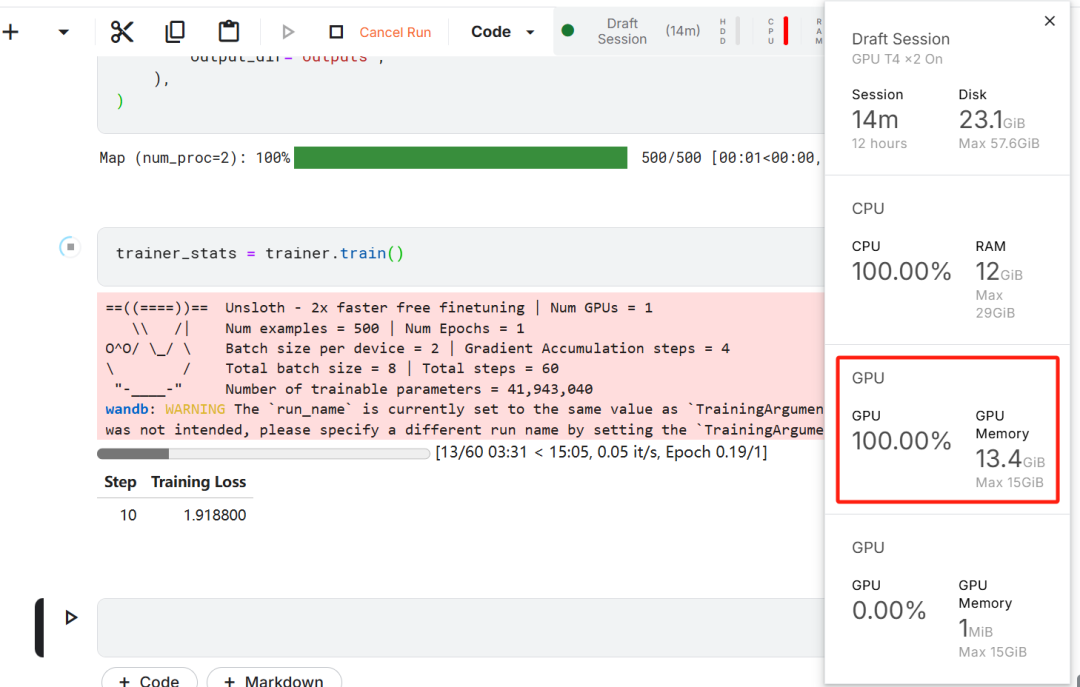
Сначала заведите новый блокнот Kaggle с объятиями пользователя жетон ответить пением Вес Токен & Biases добавляется в качестве ключа.
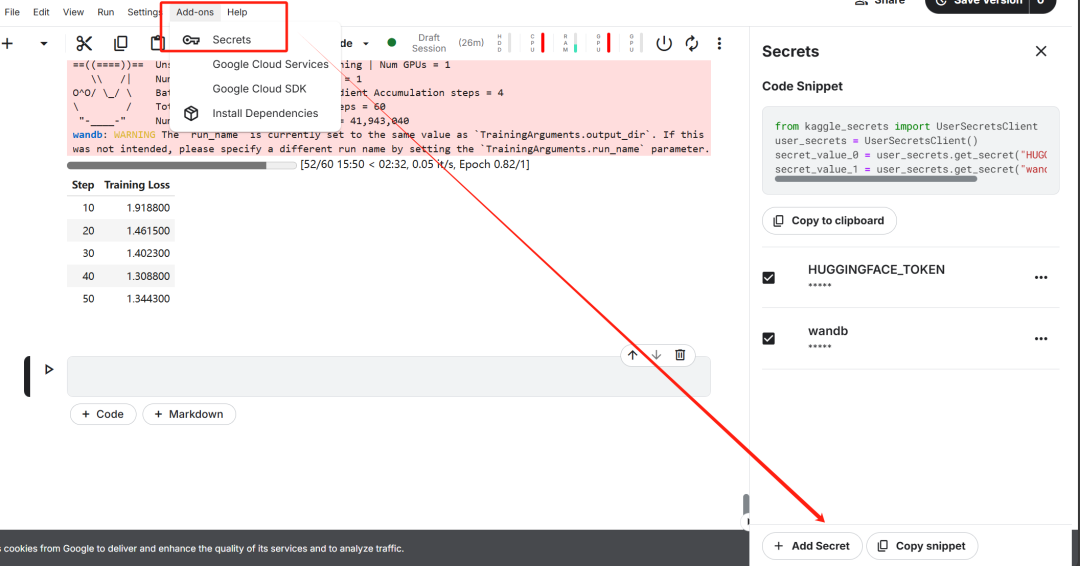
После завершения настройки ключа установите unsloth Пакет Python. Unsloth - это фреймворк с открытым исходным кодом, предназначенный для удвоения скорости тонкой настройки больших языковых моделей (LLM) и значительного повышения эффективности использования памяти.
%%capture
!pip install unsloth
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
Затем войдите в Hugging Face CLI. Этот шаг очень важен для последующей загрузки набора данных и выгрузки доработанной модели.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)
Затем войдите в систему Weights & Biases (wandb) и создайте новый проект, чтобы отслеживать ход эксперимента и корректировать прогресс.
import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune-DeepSeek-R1-Distill-Llama-8B on Medical COT Dataset',
job_type="training",
anonymous="allow"
)
2. Модели и загрузка токенизаторов
В данной работе была загружена версия Unsloth модели DeepSeek-R1-Distill-Llama-8B.
https://huggingface.co/unsloth/DeepSeek-R1-Distill-Llama-8B
Чтобы оптимизировать использование памяти и повысить производительность, модель была выбрана для загрузки в 4-битном квантованном виде.
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
token=hf_token,
)
3. праймер возможностей аргументации для модели с предварительной тонкой настройкой
Чтобы создать шаблон подсказки для модели, была определена системная подсказка, содержащая элементы для генерации вопросов и ответов. Эта подсказка призвана направлять модель через пошаговый процесс мышления и, в конечном итоге, генерировать логически строгие и точные ответы.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
В этом примере сообщение отправляется на prompt_style предоставляли медицинскую проблему и преобразовывали ее в токены, а затем эти жетоны передается в модель для генерации ответа.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
Суть вышеупомянутого медицинского вопроса заключается в следующем:
61-летняя женщина с давней историей непроизвольного подтекания мочи при таких действиях, как кашель или чихание, но без ночного подтекания. Она прошла гинекологический осмотр и тест Q-tip. Исходя из этих данных, какую информацию об объеме остаточной мочи и состоянии сокращения детрузора вероятнее всего покажет цистометрия?
Даже без тонкой настройки модель успешно генерирует цепочки мыслей и проводит строгие рассуждения, прежде чем дать окончательный ответ, причем весь процесс рассуждений заключен в <think></think> Tagged within.
Почему же доработка все еще необходима? Хотя модель демонстрирует подробный процесс рассуждений, его представление несколько затянуто и недостаточно лаконично. Кроме того, окончательные ответы представлены в виде маркированных списков, что отличается от структуры и стиля набора данных, который предполагается подвергнуть тонкой настройке.
4. Загрузка и предварительная обработка наборов данных
Шаблон подсказки был доработан с учетом потребностей обработки набора данных путем добавления в шаблон подсказки третьего места для колонки "Сложная цепь мыслей".
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""
Для создания колонки "текст" в наборе данных была написана функция Python. Содержимое столбца состоит из шаблона обучающей подсказки с заполненными местами для вопросов, цепочек мыслей и ответов, соответственно.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
Первые 500 образцов набора данных FreedomIntelligence/medical-o1-reasoning-SFT были загружены из Hugging Face Hub.
https://huggingface.co/datasets/FreedomIntelligence/medical-o1-reasoning-SFT?row=46
Впоследствии, используя formatting_prompts_func Функция отображает столбец "текст" набора данных.
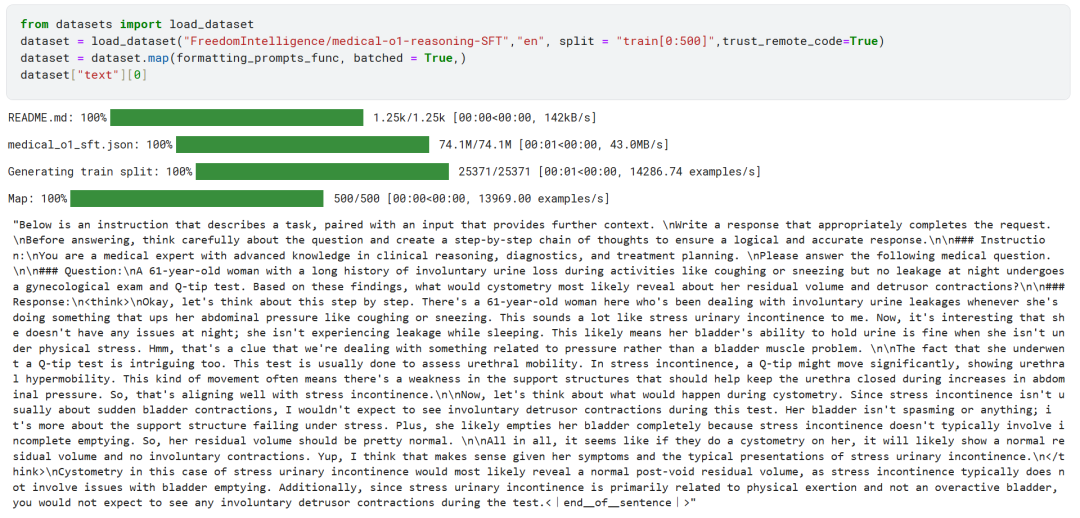
Как вы можете видеть выше, в колонку "текст" успешно интегрированы системные подсказки, инструкции, цепочки мыслей и окончательные ответы.
5. конфигурация модели
Модель конфигурируется с помощью техники Low-Rank Adapter путем установки целевого модуля.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)
Затем были настроены параметры обучения и тренер (Trainer). Модель, токенизатор, набор данных и другие ключевые параметры обучения были предоставлены тренеру для оптимизации процесса тонкой настройки модели.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
6. обучение моделей
trainer_stats = trainer.train()
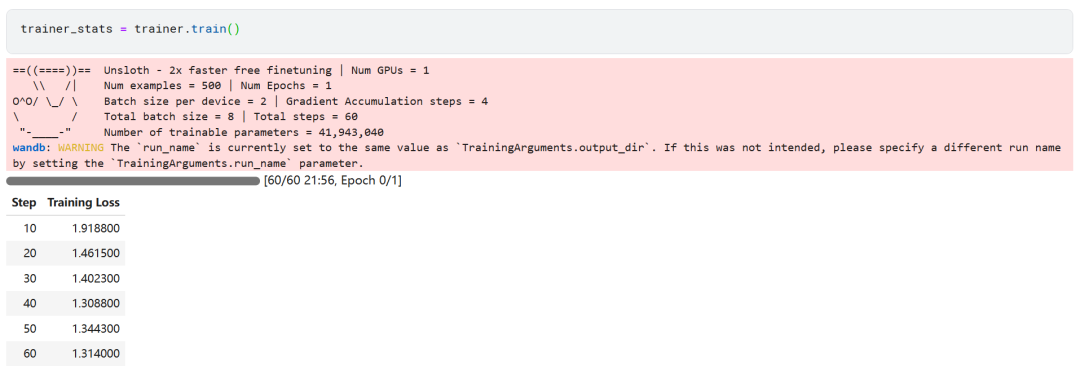
Процесс обучения модели занял 22 минуты. Потери при обучении (loss) постепенно уменьшаются, что является положительным признаком улучшения работы модели.
Пользователи могут посетить веб-сайт Weights & Biases, чтобы ознакомиться с полным отчетом об оценке модели.
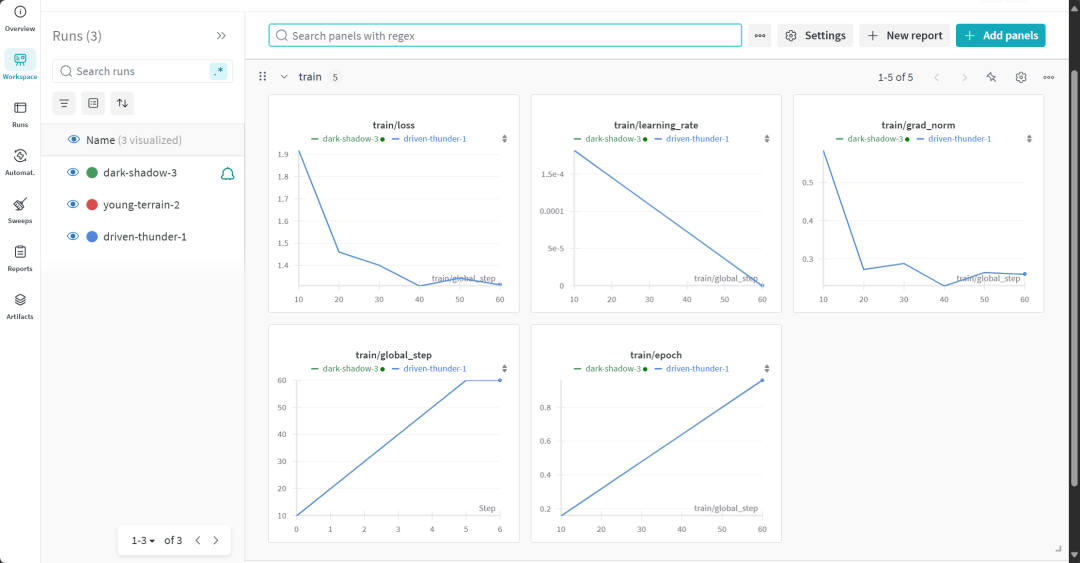
7. оценка способности к рассуждениям для модели с точной настройкой
Для сравнительного анализа модели с тонкой настройкой были заданы те же вопросы, что и до тонкой настройки, чтобы проследить за изменениями в работе модели.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
Результаты эксперимента показывают, что качество вывода модели, прошедшей тонкую настройку, значительно улучшилось, а ответы стали более точными. Цепочка мыслей была представлена более лаконично, а окончательный ответ был более прямым и четко сформулированным всего в одном абзаце, что свидетельствует об успешности тонкой настройки модели.

8. локальное хранение моделей
Теперь сохраните адаптер, полную модель и токенизатор локально, чтобы использовать их в других проектах.
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method="merged_16bit")
9. Модель загружена на Hugging Face Hub
Адаптер, токенизатор и полная модель также были размещены на Hugging Face Hub, чтобы сообщество ИИ могло использовать все преимущества этой отточенной модели и легко интегрировать ее в свои системы.
new_model_online = "realyinchen/DeepSeek-R1-Medical-COT"
model.push_to_hub(new_model_online)
tokenizer.push_to_hub(new_model_online)
model.push_to_hub_merged(new_model_online, tokenizer, save_method="merged_16bit")
резюме
Область искусственного интеллекта (ИИ) претерпевает быстрые изменения. Рост сообщества разработчиков с открытым исходным кодом бросает серьезный вызов ландшафту ИИ, в котором последние три года доминировали проприетарные модели. Большие языковые модели (Large Language Models, LLM) с открытым исходным кодом становятся все более быстрыми и эффективными, что делает их тонкую настройку более простой, чем когда-либо, с меньшими вычислительными ресурсами и памятью.
В этой статье представлен подробный обзор DeepSeek R1 модель умозаключений и подробно описывает, как ее облегченная версия может быть доработана для применения в медицинских сценариях вопросов и ответов. Тонкая настройка модели вывода не только обеспечивает значительное повышение производительности, но и делает ее практичной для использования в таких ключевых областях, как медицина, экстренные службы и здравоохранение.
В ответ на выпуск DeepSeek R1 компания OpenAI также быстро представила два важных инструмента: более совершенную модель вывода, o3, и Оператор Агент искусственного интеллекта. Последний опирается на новый Агент использования компьютера (CUA, the Компьютер Модель Use Agent), демонстрирующая способность к автономной навигации по веб-сайтам и выполнению сложных задач.
Исходный код:
https://www.kaggle.com/code/realyinchen/deepseek-r1-medical-cot
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...