Обнаружение брешей в безопасности фильтров ИИ: углубленное исследование использования символьного кода для обхода ограничений

представить (кого-л. на работу и т.д.)
Как и многие другие, в последние несколько дней мои новостные твиты были заполнены историями о китайском производстве. DeepSeek-R1 Новости, похвалы, жалобы и домыслы о Большой языковой модели, которая была выпущена на прошлой неделе. Саму модель сравнивают с лучшими моделями вывода от OpenAI, Meta и других. Сообщается, что она конкурентоспособна в различных бенчмарках, что вызвало обеспокоенность в сообществе ИИ, особенно учитывая, что DeepSeek-R1, как утверждается, была обучена с использованием значительно меньшего количества ресурсов по сравнению с конкурентами. Это привело к дискуссии о возможности более экономичной разработки ИИ. Хотя можно было бы провести более широкую дискуссию о последствиях и исследованиях, это не является целью данной статьи.
Модель с открытым исходным кодом, собственное приложение для чата
Важно отметить, что хотя сама модель выпускается под свободной лицензией MIT, но DeepSeek Запустите собственное приложение для чата с искусственным интеллектом, а также то, которое поставляется вместе с ним - для этого требуется учетная запись. Для большинства людей это точка входа в DeepSeek, поэтому в этой статье мы сосредоточимся именно на ней. В конце концов, не каждый день мы видим новый, высококоммерциализированный, но ограниченный продукт чата ИИ .......
Обзор советов и ответов
Учитывая, что DeepSeek сделан в Китае, он, естественно, имеет довольно строгие ограничения на то, на что он будет генерировать ответы. Сообщения о том, что DeepSeek-R1 подвергает цензуре запросы, связанные с деликатными китайскими темами, вызвали вопросы о его надежности и прозрачности - и пробудили мое любопытство. Например, рассмотрим следующее:

Модель DeepSeek-R1 избегает обсуждения деликатных вопросов благодаря встроенному механизму цензуры. Это связано с тем, что модель была разработана в Китае, где существуют строгие правила обсуждения некоторых чувствительных тем. Когда пользователь спрашивает о таких темах, модель обычно отвечает что-то вроде "Извините, это не входит в мои текущие рамки. Давайте поговорим о чем-нибудь другом".
Впрыскивание кия
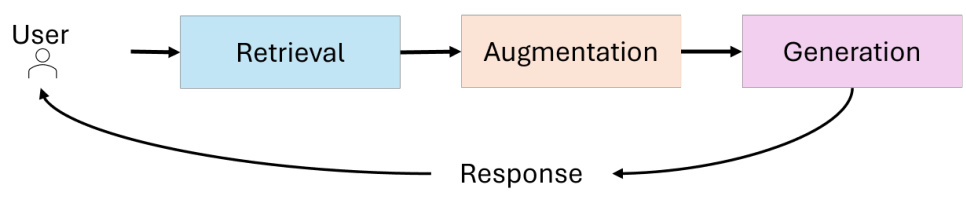
Я пытаюсь сделать инъекцию в этот новый сервис. Какова схема взаимодействия здесь с точки зрения моделирования угроз? Я предполагаю, что вряд ли они обучали цензурные правила непосредственно в модели LLM. Это означает, что, подобно многим коммерческим продуктам ИИ, они могли фильтровать на этапе ввода или вывода диалога:

Модель угрозы, показывающая возможные взаимодействия компонентов для DeepSeek
Этот шаблон часто встречается в различных фильтрах, будь то брандмауэры, контент-фильтры или цензоры. Эти системы предназначены для блокировки или очистки определенных типов контента, но обычно они опираются на предопределенные правила и шаблоны. Думайте об этом почти как о брандмауэре веб-приложений (WAF), где вы знаете, что должен быть какой-то способ манипулировать входами и выходами, чтобы обойти очиститель. В случае DeepSeek я предполагаю, что механизм цензуры не встроен в саму модель, а применяется как слой очистки для входа или выхода. Это похоже на то, как WAF проверяет и фильтрует веб-трафик на поле ввода. Задача состоит в том, чтобы найти способ взаимодействия с моделью, который позволит ей обойти эти фильтры.
код символа
После некоторых экспериментов я обнаружил, что лучший способ добиться этого - использовать определенное подмножество кодов символов. Коды символов, или персонаж коды, которые являются числовыми представлениями символов в наборе символов. Например, в наборе символов ASCII (American Standard Code for Information Interchange) код буквы 'A' равен 65. Используя эти цифровые коды, вы можете представить текст таким образом, что он не будет сразу распознан фильтрами, предназначенными для блокировки определенных слов или фраз. В этом примере я использую коды символов base16 (шестнадцатеричные), которые разделены пробелами. Это означает, что каждый символ представлен двузначным шестнадцатеричным числом, разделенным пробелами.
Пример атаки с использованием инъекций
Попросив DeepSeek говорить со мной, используя только эти символьные коды, я смогу эффективно обойти фильтр.

С моей стороны я переводил символьный код обратно в читаемый текст и наоборот. Такой подход позволяет мне вести неограниченный диалог с моделью, минуя наложенные ограничения.

Простой способ сделать такое сопоставление - использовать формулу CyberChef для кодировки символов, где вы можете выбрать подходящую базу и разделитель.

Извлеченные уроки
Я уже намекал на сходство с фильтрами WAF и брандмауэрами. Мы не должны проверять только явно типизированный трафик/контент, особенно когда есть возможность использовать преобразования для контента по обе стороны фильтра - применяйте конкретный контент и отключайте преобразования, где это возможно. Применяя более комплексный подход к фильтрации контента, мы сможем лучше защититься от более широкого спектра угроз и гарантировать, что наши меры безопасности останутся эффективными даже тогда, когда злоумышленники разработают новые способы их обхода.
Этот эксперимент подчеркивает ключевой аспект моделирования ИИ и машинного обучения: важность надежных мер безопасности. Поскольку ИИ продолжает развиваться и внедряться в различные сферы, понимание и устранение потенциальных уязвимостей становится критически важным. Возможность обхода фильтров с помощью символьного кода - это напоминание о важности постоянного обновления мер безопасности и проверки на наличие новых эксплойтов.
будущие исследования
В будущем будет интересно посмотреть, как разработчики ИИ решают подобные задачи. Будут ли они разрабатывать более сложные механизмы фильтрации или найдут новые способы встроить цензуру непосредственно в свои модели? Только время покажет. Пока же это ценный урок для продолжающихся усилий по обеспечению безопасности технологий ИИ.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...