



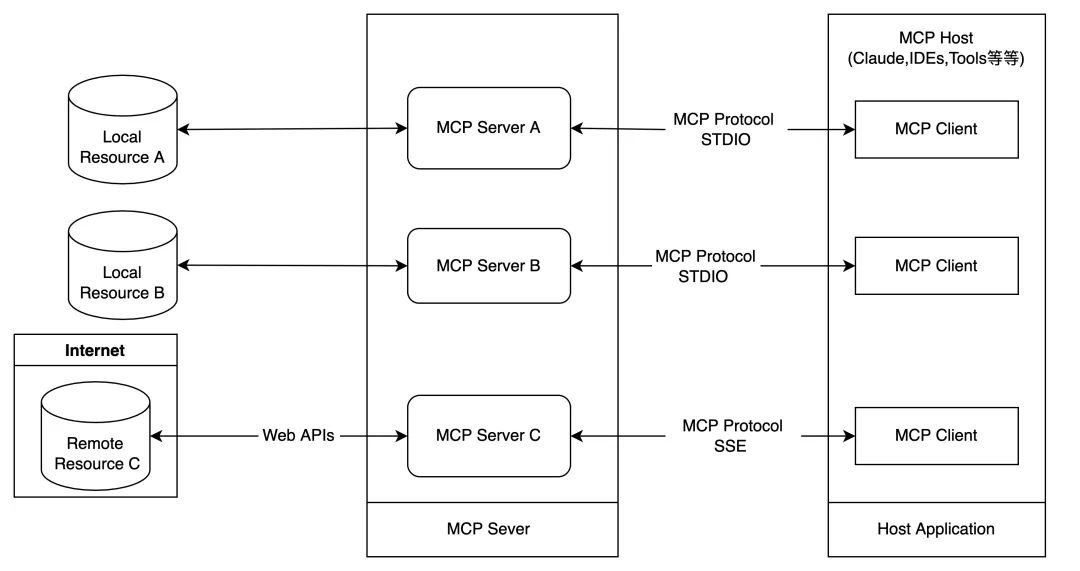
Разрешая путаницу o1, можно ли считать модели умозаключений, подобные DeepSeek-R1, мыслящими или нет?

Нашел интересную статью на сайте TheМысли разбегаются: о недостаточной продуманности o1-подобных LLM", тема - анализ модели рассуждения o1 типа Частое переключение путей мышления и отсутствие сосредоточенности в мышлении, называемое"Недоумение".Также приводятся методы смягчения последствий. Эта статья одновременно отвечает на вопрос, является ли модель вывода снова мыслящей или нет, и, надеемся, читатель найдет свой собственный ответ.
I. История вопроса:
В последние годы большие языковые модели (LLM), представленные в OpenAI моделью o1, продемонстрировали превосходные возможности в сложных задачах рассуждения, где они имитируют глубину человеческого мышления за счет увеличения объема вычислений, участвующих в процессе рассуждения. Однако существующие исследования ставят под сомнение глубину мышления LLM:Действительно ли эти модели глубоко мыслят?
Чтобы ответить на этот вопрос, авторы данной статьи предлагают"Недоумение".концепцию и систематически анализирует ее. Авторы утверждают, чтонедостаточно пищи для размышленийэто o1 класс LLM в решении сложных задач.Слишком ранний отказ от перспективных путей вывода приводит к недостаточной глубине проработки и в конечном итоге сказывается на производительности модели. Это явление особенно ярко проявляется в математических головоломках.
II. Методы рефлексии и исследования:
Чтобы глубже изучить феномен недомыслия, авторы провели следующее исследование:
1. Определение и наблюдение за явлением дефицита отражения
- Определение мышления: Авторы определяют "мышление" как промежуточный когнитивный шаг в процессе рассуждения модели и используют такие термины, как "альтернативно", как признак переключения мышления.
- Пример: На рисунке 2 авторы приводят пример результата модели, содержащей 25 шагов мышления, и сравнивают его с результатом чрезмерного мышления.
- Экспериментальная конструкция:
- Наборы для тестирования: Авторы выбрали три сложных набора тестов:
- MATH500. Содержит вопросы из школьных математических конкурсов, сложность которых варьируется от 1 до 5.
- Бриллиант GPQA. Содержит вопросы с множественным выбором для выпускников по физике, химии и биологии.
- AIME2024. Темы пригласительного математического конкурса США охватывают широкий спектр областей, включая алгебру, счет, геометрию, теорию чисел и вероятность.
- Выбор модели: Авторы выбрали две открытые модели класса o1 с заметными длинными цепочками размышлений: QwQ-32B-Preview и DeepSeek-R1-671B, и использовали DeepSeek-R1-Preview в качестве дополнения, чтобы показать развитие семейства моделей R1.
- Наборы для тестирования: Авторы выбрали три сложных набора тестов:
2. анализ проявлений неадекватного отражения
- Подумайте о частоте переключений и сложности задач:
- Авторы обнаружили, что количество генерируемых размышлений и количество генерируемых лексем увеличивается для всех моделей по мере увеличения сложности задачи (см. Рисунок 3).
- Это говорит о том, что ЛЛМ класса o1 способны динамически адаптировать процесс рассуждений для решения более сложных задач.

- Размышления о переключении и реакции на ошибку:
- Во всех тестовых наборах ЛЛМ класса o1 чаще переключали мышление при генерации неправильных ответов (см. рис. 1 и 4).
- Это говорит о том, что, хотя модель направлена на динамическую адаптацию когнитивных процессов для решения задач, более частое переключение мышления не обязательно приводит к повышению точности.
3. Глубокое исследование природы дефицита мышления
- Оцените правильность мышления:
- Авторы использовали две модели на основе Llama и Qwen (DeepSeek-R1-Distill-Llama-70B и DeepSeek-R1-Distill-Qwen-32B) для оценки правильности каждого шага мышления.
- Результаты показывают, чтоЗначительная часть первых шагов мышления в ответе на ошибку верна, но не полностью изучена(см. рисунок 5).
- Это говорит о том, что модель, столкнувшись со сложной проблемойСклонность преждевременно отказываться от перспективных путей рассуждений, что приводит к отсутствию глубины мышления.
- Подумайте о распределении правильности:
- Авторы обнаружили, что более 701 ошибочного ответа TP3T содержал по крайней мере один правильный шаг мышления (см. Рисунок 6).
- Это еще раз подтверждает вышеизложенную точку зрения:o Модели класса 1 способны инициировать правильные пути рассуждений, но им может быть трудно продолжить эти пути до правильного вывода.
4. Количественная оценка отсутствия рефлексии: предложение новых показателей для оценки
- Размышления о заниженных показателях (UT):
- Эта метрика количественно оценивает степень недодуманности, измеряя эффективность маркера при генерации ответа на ошибку.
- В частности, метрика UT рассчитывает отклик на ошибку, при которомКоличество лексем, правильно осмысленных от начала к первой, как доля от общего количества лексем.
- Более высокие значения UT указывают на более высокий уровень заниженного мышленият.е. большая часть лексем, генерируемых моделью в ответ на ошибку, не вносит эффективного вклада в формирование правильного мышления.
5. Влияние недостаточного мышления на производительность модели:
- Авторы обнаружили, чтоФеномен недомыслия по-разному проявляется в разных наборах данных и задачах::
- На наборах данных MATH500-Hard и GPQA Diamond модель DeepSeek-R1-671B, хотя и была более точной, также имела более высокое значение UT, что говорит о более низком уровне мышления в ее реакции на ошибку.
- На тестовом наборе AIME2024 модель DeepSeek-R1-671B имеет не только более высокую точность, но и более низкое значение UT, что говорит о более целенаправленном и эффективном процессе вывода.
III. Важные выводы:
- Недостаток мышления является важным фактором плохой работы o1 LLM над сложными проблемами. Частое переключение мышления приводит к тому, что модель не может глубоко исследовать перспективные пути умозаключений, что в конечном итоге сказывается на ее точности.
- Феномен недостаточного мышления связан с трудностью задачи и способностью к моделированию. Более сложные проблемы усугубляют недодуманность, а более мощные модели не всегда уменьшают недодуманность.
- Недоумение отличается от переумения. Излишняя задумчивость - это когда модель тратит вычислительные ресурсы на решение простых задач, а недостаточная задумчивость - когда модель преждевременно отказывается от перспективных путей умозаключений при решении сложных задач.
- Индикатор заниженного мышления (UT) позволяет эффективно оценить степень заниженного мышления. Эта метрика дает новую перспективу для оценки эффективности рассуждений LLM класса o1.
IV. Стратегии реагирования:
Чтобы облегчить проблему неадекватного мышления, авторы предлагаютСтратегия декодирования со штрафом за переключение (TIP)::
- Основные идеи: В процессе декодирования к маркеру, связанному с переключателем мыслей, применяются штрафные санкции.Поощряйте модели к более глубокому изучению текущего мышления, прежде чем переходить к новому..
- Результаты: Стратегия TIP повышает точность модели QwQ-32B-Preview на всех тестовых наборах, доказывая ее эффективность в устранении проблемы недостаточного мышления.
V. Перспективы на будущее:
Авторы предлагают такие направления будущих исследований, как:
- Разработка адаптивных механизмов, позволяющих моделям самостоятельно регулировать переключение мышления.
- Дальнейшее повышение эффективности выводов LLM класса o1.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

Нет комментариев...