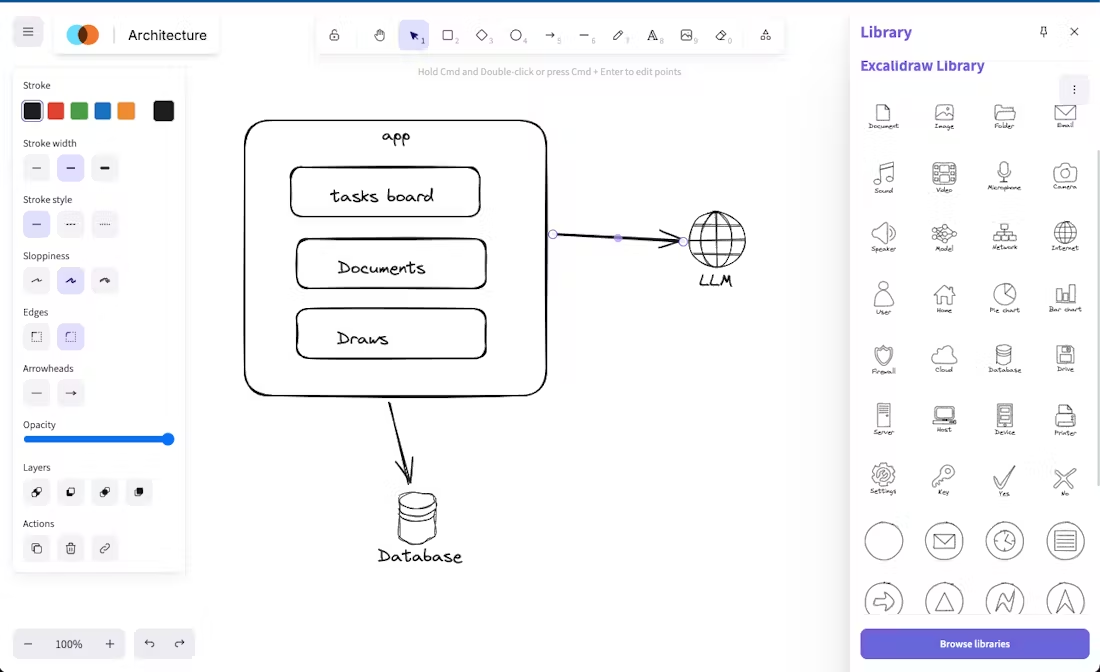
HunyuanOCR - экспертная модель Tencent с открытым исходным кодом для оптического распознавания символов

Что такое HunyuanOCR
HunyuanOCR - высокопроизводительная модель оптического распознавания символов с открытым исходным кодом, созданная гибридной командой Tencent и насчитывающая всего 1 миллиард ссылок. Разработанная на основе гибридной мультимодальной архитектуры, использующей сквозной дизайн, модель способна эффективно справляться с задачами обнаружения, распознавания и разбора текста в документе. Модель набрала 94,1 балла в тесте на распознавание сложных документов, превзойдя такие мейнстримовые продукты, как Google Gemini3-Pro, и поддерживает перевод на 14 малых языков. Легкие функции подходят для распознавания билетов, извлечения субтитров из видео и других сцен, открытый исходный код для GitHub и платформы Hugging Face.

Особенности HunyuanOCR
- Эффективная облегченная архитектураТолько подсчет параметров 1B, основанный на гибридной нативной мультимодальной архитектуре, значительно снижает стоимость развертывания и подходит для широкого спектра аппаратных сред.
- Возможность сквозной обработки данныхВесь процесс от ввода изображения до вывода результата может быть обработан из конца в конец, а оптимальный результат может быть достигнут с помощью одной инструкции и одного вывода, что более эффективно и удобно, чем традиционные решения.
- Поддержка нескольких языковПоддержка более 100 языков, охватывающая как моноязычные, так и многоязычные гибридные документы, адаптирующиеся к глобализированным сценариям применения.
- Полная возможность распознавания текста: Охватывает классические задачи OCR, такие как обнаружение и распознавание текста, сложный синтаксический анализ документов, извлечение информации из открытого поля, извлечение субтитров из видео и т.д. с широкими возможностями.
- Превосходная производительность: Достижение уровня SOTA в ряде основных возможностей, таких как сложный синтаксический анализ документов, обнаружение и распознавание многосюжетных текстов и т. д., с ведущей производительностью.
- простой в использованииЛаконичный интерфейс и богатый код примеров, поддержка различных фреймворков (таких как vLLM, Transformers), простота запуска и интеграции.
Основные преимущества HunyuanOCR
- Легкий и эффективныйПодсчет параметров 1B основан на высокоэффективном архитектурном дизайне, который значительно снижает стоимость развертывания при сохранении высокой производительности.
- сквозное проектирование: сквозная обработка от входного изображения до выходного результата без сложного каскадирования, что повышает эффективность и точность.
- Поддержка нескольких языковПоддержка более 100 языков, охватывающая как моноязычные, так и многоязычные гибридные документы, адаптирующиеся к глобализированным сценариям применения.
- превосходная производительность: Он достигает уровня SOTA в таких задачах, как сложный синтаксический разбор документов, обнаружение и распознавание многосюжетных текстов, и значительно опережает аналогичные модели.
- простой в использованииПредоставляем лаконичный API и богатый пример кода, поддерживаем различные основные фреймворки, легко интегрируем и развертываем.
- Широкий спектр сценариев примененияОн подходит для обработки документов, извлечения полей билетов, извлечения субтитров видео, перевода фотографий и многих других сценариев.
Что такое официальный сайт HunyuanOCR
- Веб-сайт проекта:: https://hunyuan.tencent.com/vision/zh?tabIndex=0
- Репозиторий Github:: https://github.com/Tencent-Hunyuan/HunyuanOCR
- Библиотека моделей обнимающихся лиц:: https://huggingface.co/tencent/HunyuanOCR
- Технический отчет:: https://github.com/Tencent-Hunyuan/HunyuanOCR/blob/main/HunyuanOCR_Technical_Report.pdf
- Опыт работы в Интернете:: https://huggingface.co/spaces/tencent/HunyuanOCR
Для кого предназначен HunyuanOCR
- разработчики: Эффективные и легкие OCR-решения необходимы для разработки программного обеспечения и приложений для обработки документов, распознавания изображений, многоязычного перевода и других функций.
- бизнес-пользователь: Автоматизированные инструменты извлечения и перевода текста необходимы в таких областях, как управление документами, обработка билетов и создание контента, чтобы повысить производительность и качество.
- научный сотрудник: Мультимодальные исследования в таких областях, как обработка естественного языка и компьютерное зрение, требуют мощных инструментов OCR для обработки изображений и текстовых данных.
- педагог: Необходимость быстрого извлечения и перевода текстового контента из литературы и учебных материалов для преподавания и исследований, а также для поддержки многоязычного обучения и исследований.
- создатель контента: При производстве видео и создании графики необходимо извлекать текстовую информацию из изображений или выполнять многоязычный перевод, чтобы обогатить создаваемый контент.
- постоянный пользователь: Необходимость быстрого перевода или извлечения текстовой информации из изображений в путешествиях, учебе, офисе и других сценариях для повышения эффективности жизни и работы.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...