
Advanced RAG: архитектура, технология, применение и перспективы развития

Генерация с расширением поиска (Retrieval-augmented generation, RAG) стала важным фреймворком в области ИИ, значительно повышающим точность и релевантность больших языковых моделей (LLM) при генерации ответов с использованием внешних источников знаний. Согласно Databricks Данные показывают, что 60% приложений LLM на предприятии используют Retrieval Augmented Generation (RAG), а 30% - многоступенчатый процесс. RAG привлек к себе много внимания, потому что он генерирует ответы, которые почти так же хороши, как и те, которые полагаются только на точную настройку модели. Повышенная точность 43%Он показывает, что RAG большой потенциал для повышения качества и надежности контента, создаваемого ИИ.
Однако традиционные подходы к RAG по-прежнему сталкиваются с рядом проблем, связанных с ответом на сложные запросы, пониманием нюансов контекста и обработкой множества типов данных. Эти ограничения послужили толчком к созданию усовершенствованных RAG, направленных на расширение возможностей ИИ в области поиска и генерации информации. В частности.количество компаний RAG был интегрирован в около 60% изделий, что демонстрирует его важность и эффективность в практическом применении.
Одним из главных прорывов в этой области стало появление мультимодальных RAG и графов знаний. Мультимодальные RAG расширяют возможности RAG по обработке не только текста, но и широкого спектра данных, включая изображения, аудио и видео. Это позволяет системам ИИ быть более комплексными и лучше понимать контекст при взаимодействии с пользователями. Графы знаний, с другой стороны, повышают согласованность и точность процесса поиска информации и генерируемого контента за счет структурированного представления знаний.Microsoft Research предполагает, что требуемый GraphRAG Токен Число уменьшилось с 26% до 97% по сравнению с другими методами, что свидетельствует о более высокой эффективности и снижении вычислительных затрат.
Эти достижения в технологии RAG привели к значительному росту производительности в различных бенчмарках и реальных приложениях. Например.карта знаний достигла точности 86,31% в тесте RobustQA, что значительно превосходит другие методы RAG. Кроме того, вСекеда и Аллеманг Последующие исследования показали, что объединение онтологий снижает количество ошибок 20%. Бизнес также извлек значительную выгоду из этих достижений.LinkedIn сообщила о сокращении времени решения проблем с поддержкой клиентов на 28,61 TP3T благодаря подходу RAG плюс Knowledge Graph.
В этой статье мы рассмотрим эволюцию передовых RAGs, изучим сложность мультимодальных RAGs и RAGs Knowledge Graph и их эффективность в улучшении поиска и генерации информации на основе ИИ. Мы также обсудим потенциал применения этих инноваций в различных отраслях и проблемы, возникающие при продвижении и применении этих технологий.
- [Что такое Retrieval Augmented Generation (RAG) и почему он важен для моделирования больших языков (LLM)?
- [Типы архитектуры RAG].
- [От базового RAG к продвинутому RAG: как преодолеть ограничения и расширить возможности]
- [Продвинутые компоненты системы RAG и процессы на предприятии]
- [Передовая технология RAG]
- [Расширенные приложения RAG и практические примеры].
- [Как построить диалоговые инструменты с помощью расширенного RAG?]
- [Как создать продвинутое приложение RAG?]
- [Восхождение графов знаний в Advanced RAG].
- [Advanced RAG: Enhanced generation of extended horizons through multimodal retrieval]
- [Как платформа для совместной работы GenAI от LeewayHertz, ZBrain, выделяется среди передовых систем RAG].
Advanced RAG: архитектура, технология, применение и перспективы развития PDF Download:
Advanced RAG: архитектура, технология, применение и перспективы развития
Что такое Retrieval Augmented Generation (RAG) и почему он важен для моделирования больших языков (LLM)?
Большие языковые модели (БЯМ) заняли центральное место в приложениях ИИ, на их мощь опираются все - от виртуальных ассистентов до сложных инструментов анализа данных. Но, несмотря на свои возможности, эти модели имеют ограничения в предоставлении актуальной и точной информации. Именно здесь мощным дополнением к LLM становится Retrieval Augmented Generation (RAG).
Что такое расширенное поколение (RAG)?
RAG (Retrieval Augmented Generation) - это передовая технология, которая расширяет генеративные возможности больших языковых моделей (LLM) за счет интеграции внешних источников знаний. LLM обучаются на больших наборах данных с миллиардами параметров и способны выполнять широкий спектр задач, таких как ответы на вопросы, лингвистический перевод и завершение текста. RAG идут на шаг дальше, обращаясь к авторитетным и специфическим для домена базам знаний, чтобы улучшить релевантность, точность и полезность генерируемого контента без необходимости повторного обучения модели. RAG делают еще один шаг вперед, обращаясь к авторитетным и специфическим для данной области базам знаний, чтобы повысить релевантность, точность и полезность генерируемого контента без необходимости переобучения модели. Этот экономичный и эффективный подход идеально подходит для компаний, стремящихся оптимизировать свои системы искусственного интеллекта.
Как RAG (Retrieval Augmented Generation) может помочь моделированию большого языка (LLM) решить основную проблему?
Большие языковые модели (БЯМ) играют ключевую роль в управлении интеллектуальными чат-ботами и другими приложениями для обработки естественного языка (NLP). Путем длительного обучения они пытаются давать точные ответы в различных контекстах. Однако сами LLM имеют ряд недостатков и сталкиваются с многочисленными проблемами:
- сообщение об ошибке: Неточные ответы могут быть получены при недостаточном знании LLM.
- Устаревшая информация: Обучающие данные статичны, поэтому ответы, генерируемые моделью, могут быть устаревшими.
- неавторитетный источник: Сгенерированные ответы могут иногда поступать из ненадежных источников, что влияет на достоверность.
- Путаница в терминологии: Непоследовательное использование одной и той же терминологии в разных источниках данных может легко привести к недоразумениям.
RAG решает эти проблемы, предоставляя LLM внешний авторитетный источник данных для повышения точности и оперативности ответов модели. Ниже объясняется, почему RAG так важен для развития LLM:
- Повышение точности и релевантностиRAG извлекает самую свежую и актуальную информацию из авторитетных источников, чтобы ответы модели были более точными и соответствовали текущему контексту, поскольку обучающие данные статичны.
- Преодолевая ограничения статических данныхДанные об обучении LLM иногда устаревают и не отражают последние исследования и новости. RAG дает LLM доступ к самым последним данным, сохраняя информацию актуальной и значимой.
- Повышение доверия пользователейLLM может генерировать так называемые "иллюзии" - уверенные, но неверные ответы, - а RAG повышает прозрачность и доверие пользователей, позволяя LLM ссылаться на источники и предоставлять проверяемую информацию.
- экономия средствRAG обеспечивает более экономичную альтернативу повторному обучению LLM с использованием новых данных, обеспечивая экономичную альтернативу повторному обучению всей модели с использованием внешних источников данных, что делает передовые методы ИИ более доступными.
- Улучшенный контроль и гибкость разработчиковRAG предоставляет разработчикам больше свободы для гибкого определения источников знаний, быстрой адаптации к изменениям требований и обеспечения надлежащей обработки конфиденциальной информации для поддержки широкого спектра приложений и повышения эффективности систем искусственного интеллекта.
- Предоставление индивидуальных ответовВ то время как традиционные LLM обычно дают слишком общие ответы, RAG объединяет LLM с внутренними базами данных организации, информацией о продуктах и руководствами пользователя, чтобы предоставить более конкретные и релевантные ответы, значительно улучшая опыт поддержки и взаимодействия с клиентами.
RAG (Retrieval Augmented Generation) позволяет LLM генерировать более точные, контекстные ответы в режиме реального времени благодаря интеграции с внешними базами знаний. RAG не только повышает эффективность, но и увеличивает доверие пользователей к системам искусственного интеллекта, что крайне важно для организаций, которые полагаются на ИИ: от обслуживания клиентов до анализа данных.
Типы архитектуры RAG
Retrieval Augmented Generation (RAG) представляет собой значительное достижение в технологии ИИ, объединяя языковые модели с внешними системами поиска знаний. Этот гибридный подход повышает способность ИИ генерировать ответы, получая подробную и релевантную информацию из больших внешних источников данных. Понимание различных типов архитектур RAG помогает нам лучше использовать их преимущества в соответствии с нашими конкретными потребностями. Ниже мы подробно рассмотрим три основные архитектуры RAG:
1. Наивный RAG
Наивный RAG - это самый простой метод генерации расширенного поиска. Его принцип прост: система извлекает из базы знаний релевантные фрагменты информации на основе запроса пользователя, а затем использует эти фрагменты информации в качестве контекста для создания ответа с помощью языкового моделирования.
Особенности:
- механизм поиска: Простой метод поиска используется для извлечения релевантных блоков документов из заранее созданного индекса, обычно путем сопоставления ключевых слов или базового семантического сходства.
- контекстная интеграцияНайденные документы объединяются с запросом пользователя и поступают в языковую модель для создания ответа. Это объединение обеспечивает более богатый контекст для модели, чтобы генерировать более релевантные ответы.
- технологический процесс: Система следует фиксированному процессу: извлечение, соединение, генерация. Модель не изменяет извлеченную информацию, а использует ее непосредственно для генерации ответов.
2. Расширенный RAG
Advanced RAG основан на Naive RAG и использует более продвинутые методы для повышения точности поиска и контекстной релевантности. Он преодолевает некоторые ограничения Naive RAG, сочетая в себе усовершенствованные механизмы для лучшей обработки и использования контекстной информации.
Особенности:
- Улучшенный поиск: Повышение качества и релевантности найденной информации с помощью расширенных стратегий поиска, таких как расширение запроса (добавление релевантных терминов к исходному запросу) и итеративный поиск (оптимизация документов на нескольких этапах).
- Оптимизация контекста: Избирательное фокусирование на наиболее значимых частях контекста с помощью таких техник, как механизм внимания, помогает языковой модели генерировать более точные и контекстуально более точные ответы.
- стратегия оптимизацииСтратегии оптимизации, такие как оценка релевантности и контекстное расширение, используются для обеспечения того, чтобы модель захватывала наиболее релевантную и качественную информацию для генерации ответов.
3. Модульный RAG
Modular RAG - это наиболее гибкая и настраиваемая архитектура RAG. Она разбивает процесс поиска и генерации на отдельные модули, позволяя оптимизировать и заменять их в соответствии с потребностями конкретных приложений.
Особенности:
- Модульная конструкция: Декомпозиция процесса RAG на различные модули, такие как расширение запроса, поиск, переупорядочивание и генерация. Каждый модуль может быть оптимизирован независимо и заменен по требованию.
- Гибкая настройка: Позволяет высокую степень кастомизации, когда разработчики могут пробовать различные конфигурации и методы на каждом этапе, чтобы найти наилучшее решение. Методология позволяет создавать индивидуальные решения для различных сценариев применения.
- Интеграция и адаптация: Архитектура способна интегрировать дополнительные функциональные возможности, такие как модуль памяти (для записи прошлых взаимодействий) или модуль поиска (для извлечения данных из поисковых систем или графов знаний). Такая адаптивность позволяет гибко подстраивать систему RAG под конкретные нужды.
Понимание этих типов и характеристик очень важно для выбора и внедрения наиболее подходящей архитектуры RAG.
От базового к продвинутому RAG: преодоление ограничений и расширение возможностей
Генерация с дополненным извлечением (RAG) используется в Обработка естественного языка (NLP) Он стал очень эффективным методом объединения поиска информации и создания текстов для получения более точных и контекстуальных результатов. Однако по мере развития технологии первоначальные "базовые" системы RAG выявили некоторые недостатки, что привело к появлению более совершенных версий. Эволюция базовой RAG в продвинутую RAG означает, что мы постепенно преодолеваем эти недостатки и значительно улучшаем общие возможности системы RAG.
Ограничения базового RAG

Основа фреймворка RAG - это первая попытка объединить поиск и генерацию для НЛП. Хотя этот подход является инновационным, он все еще сталкивается с некоторыми ограничениями:
- Простые методы поиска: Большинство базовых систем RAG опираются на простое сопоставление ключевых слов - подход, который затрудняет понимание нюансов и контекста запроса и, следовательно, позволяет получить недостаточно или частично релевантную информацию.
- Трудности с пониманием контекста: Этим системам сложно правильно понять контекст пользовательского запроса. Например, система RAG может получить документы, содержащие ключевые слова запроса, но не может уловить истинное намерение или контекст пользователя, что не позволяет точно удовлетворить его потребности.
- Ограниченная способность обрабатывать сложные запросы: Базовые системы RAG плохо работают, когда сталкиваются со сложными или многоступенчатыми запросами. Их недостатки в понимании контекста и точности поиска затрудняют эффективное решение сложных задач.
- Статическая база знаний: Базовая система RAG опирается на статичную базу знаний и не имеет механизма динамического обновления; со временем информация может устареть, что повлияет на точность и актуальность ответа.
- Отсутствие итеративной оптимизации: В базовом RAG отсутствует механизм оптимизации на основе обратной связи, он не может улучшить производительность за счет итеративного обучения и со временем стагнирует.
Переход на продвинутый уровень RAG
С развитием технологий стали доступны более сложные решения, позволяющие устранить недостатки базовых систем RAG. Передовые системы RAG преодолевают эти проблемы несколькими способами:
- Более сложные алгоритмы поискаПередовые системы RAG используют такие сложные методы, как семантический поиск и контекстное понимание, которые позволяют выйти за рамки сопоставления ключевых слов и понять реальный смысл запроса, тем самым повышая релевантность полученных результатов.
- Расширенная контекстная интеграция: Эти системы учитывают контекст и весовые коэффициенты релевантности для интеграции результатов поиска, чтобы обеспечить не только точность информации, но и ее соответствие контексту, а также лучший ответ на запрос и намерения пользователя.
- Итеративная оптимизация и механизмы обратной связи::
Система Advanced RAG использует итеративный процесс оптимизации, который постоянно улучшает точность и релевантность с течением времени, учитывая отзывы пользователей. - Динамическое обновление знаний::
Передовая система RAG способна динамически обновлять базу знаний, постоянно внедряя новейшую информацию и обеспечивая постоянное отражение в системе последних тенденций и разработок. - Комплексное понимание контекста::
Используя более совершенные методы NLP, передовые системы RAG глубже понимают запрос и контекст и способны анализировать семантические нюансы, контекстные подсказки и намерения пользователя, чтобы генерировать более последовательные и релевантные ответы.
Улучшение системы RAG на компонентах
Эволюция от базового к продвинутому RAG означает, что система достигает значительных улучшений в каждом из четырех ключевых компонентов: хранении, поиске, улучшении и генерации.
- запас: Передовые системы RAG делают поиск информации более эффективным за счет хранения данных с помощью семантического индексирования, организованного по смыслу данных, а не по простым ключевым словам.
- получить (данные): Благодаря усовершенствованию семантического поиска и контекстного поиска система не только находит релевантные данные, но и понимает намерения и контекст пользователя.
- укреплять: Модуль усовершенствования системы Advanced RAG генерирует более персонализированные и точные ответы с помощью механизма динамического обучения и адаптации, который постоянно оптимизируется на основе взаимодействия с пользователем.
- создание: Модуль Generation использует сложное понимание контекста и итеративную оптимизацию для создания более последовательных и контекстных ответов.
Эволюция от базовых RAG к продвинутым RAG - это значительный скачок вперед. Благодаря использованию сложных методов поиска, расширенной контекстной интеграции и механизмов динамического обучения продвинутые системы RAG обеспечивают более точный и учитывающий контекст подход к поиску и генерации информации. Это улучшает качество взаимодействия с ИИ и закладывает основу для более тонкой и эффективной коммуникации.
Компоненты и рабочие процессы передовой системы RAG корпоративного уровня
В области корпоративных приложений растет потребность в системах, способных интеллектуально извлекать и генерировать необходимую информацию. Системы Retrieval Augmented Generation (RAG) стали мощными решениями, сочетающими точность поиска информации с генеративной способностью больших языковых моделей (LLM). Однако для создания продвинутой системы RAG, отвечающей сложным потребностям организации, ее архитектура должна быть тщательно продумана.
Основные компоненты архитектуры
Современная система Retrieval Augmentation Generation (RAG) требует наличия множества основных компонентов, которые работают вместе для обеспечения эффективности и результативности системы. Эти компоненты охватывают управление данными, обработку пользовательского ввода, поиск и генерацию информации, а также постоянное повышение производительности системы. Ниже приводится подробное описание этих ключевых компонентов:
- Подготовка и управление данными
Основой продвинутой системы RAG является подготовка и управление данными, которые включают в себя ряд ключевых компонентов:
- Расщепление и векторизация данных: Данные разбиваются на более удобные фрагменты и преобразуются в векторные представления, что очень важно для повышения эффективности и точности поиска.
- Создание метаданных и сводок: Создание метаданных и резюме позволяет быстро находить нужные сведения и сокращает время поиска.
- Очистка данных: Обеспечение чистоты, упорядоченности и отсутствия помех в данных - залог точности полученной информации.
- Работает со сложными форматами данных: Способность системы работать со сложными форматами данных обеспечивает эффективное использование различных типов данных в организации.
- Управление конфигурацией пользователя: Персонализация очень важна в корпоративной среде, а управление конфигурациями пользователей позволяет адаптировать ответы к индивидуальным потребностям, оптимизируя работу пользователей.
- Обработка пользовательского ввода
Модуль обработки пользовательского ввода играет важную роль в обеспечении эффективной работы системы с запросами:
- Аутентификация пользователей: Безопасность корпоративных систем очень важна, и механизмы аутентификации гарантируют, что только авторизованные пользователи могут использовать систему RAG.
- Оптимизатор запросов: Структура запроса пользователя может оказаться неподходящей для поиска, и оптимизатор оптимизирует запрос, чтобы повысить релевантность и точность поиска.
- Механизмы защиты входа: Механизмы защиты защищают систему от посторонних или вредоносных воздействий, обеспечивая надежность процесса поиска.
- Использование истории чата: Обращаясь к предыдущим диалогам, система лучше понимает и отвечает на текущий запрос, генерируя более точные и контекстуальные ответы.
- информационно-поисковая система
Информационно-поисковая система лежит в основе архитектуры RAG и отвечает за извлечение наиболее релевантной информации из предварительно обработанного индекса данных:
- Индексирование данных: Эффективная технология индексирования обеспечивает быстрый и точный поиск информации, а передовые методы индексирования позволяют обрабатывать большие объемы корпоративных данных.
- Настройка гиперпараметров: Параметры модели поиска настраиваются для оптимизации ее работы и обеспечения получения наиболее релевантных результатов.
- Переупорядочивание результатов: После поиска система упорядочивает результаты, чтобы наиболее релевантная информация отображалась первой, что повышает качество ответа.
- Встраивание оптимизации: Настраивая векторы встраивания, система может лучше сопоставить запрос с соответствующими данными, что повышает точность поиска.
- Гипотетические проблемы с технологией HyDE: Генерация гипотетических пар вопросов и ответов с помощью технологии HyDE (Hypothetical Document Embedding) позволяет лучше справляться с поиском информации, когда запрос и документ асимметричны.
- Генерация и обработка информации
При получении релевантной информации система должна генерировать последовательный и контекстуально релевантный ответ:
- Генерация ответов: Используя усовершенствованные большие языковые модели (LLM), модуль синтезирует полученную информацию в полный и точный ответ.
- Защита и аудит выходных данных: Чтобы убедиться в том, что созданные ответы соответствуют спецификациям, система использует различные правила для их проверки.
- Кэширование данных: Часто используемые данные или ответы кэшируются, что сокращает время поиска и повышает эффективность системы.
- Генерация персонализации: Система настраивает генерируемый контент в соответствии с потребностями и конфигурацией пользователя, чтобы обеспечить актуальность и точность ответа.
- Обратная связь и оптимизация системы
Передовые системы RAG должны быть способны к самообучению и совершенствованию, а механизмы обратной связи необходимы для постоянной оптимизации:
- Отзывы пользователей: Собирая и анализируя отзывы пользователей, система может выявлять области, требующие улучшения, и развиваться, чтобы лучше удовлетворять их потребности.
- Оптимизация данных: На основе отзывов пользователей и новых результатов данные в системе постоянно оптимизируются для обеспечения качества и актуальности информации.
- Генерируйте оценки качества: Система регулярно оценивает качество генерируемого контента для его постоянной оптимизации.
- Мониторинг системы: Постоянный мониторинг производительности системы, чтобы убедиться, что она работает эффективно и может реагировать на изменения спроса или изменения в структуре данных.
Интеграция с корпоративными системами
Для того чтобы передовая система RAG наилучшим образом работала в организационной среде, необходима бесшовная интеграция с существующими системами:
- Интеграция CRM и ERP-систем: Взаимодействие передовых систем RAG с системами управления взаимоотношениями с клиентами (CRM) и планирования ресурсов предприятия (ERP) обеспечивает эффективный доступ к ключевым бизнес-данным и их использование, повышая способность генерировать точные и контекстуально релевантные ответы.
- API и архитектура микросервисов: Использование гибких API и архитектуры микросервисов позволяет легко интегрировать систему RAG в существующее корпоративное программное обеспечение, обеспечивая модульную модернизацию и расширение.
Безопасность и соответствие нормативным требованиям
Безопасность и соответствие нормативным требованиям особенно важны в связи с конфиденциальностью корпоративных данных:
- Протоколы безопасности данных: Для защиты конфиденциальной информации и обеспечения соответствия нормам защиты данных, таким как GDPR, используются надежное шифрование данных и меры по безопасной обработке данных.
- Контроль доступа и аутентификация: Внедрите надежную аутентификацию пользователей и механизмы управления доступом на основе ролей, чтобы гарантировать, что только авторизованный персонал может получить доступ к системе или внести в нее изменения.
Масштабируемость и оптимизация производительности
Системы RAG корпоративного класса должны быть масштабируемыми и поддерживать высокую производительность при высоких нагрузках:
- Облачная нативная архитектура: Использование облачно-нативной архитектуры обеспечивает гибкость масштабирования ресурсов по требованию, гарантируя высокую доступность системы и оптимизацию производительности.
- Балансировка нагрузки и управление ресурсами: Эффективная балансировка нагрузки и стратегии управления ресурсами помогают системе обрабатывать большие объемы пользовательских запросов и данных, сохраняя при этом оптимальную производительность.
Анализ и отчетность
Передовые системы RAG также должны обладать мощными возможностями анализа и отчетности:
- Мониторинг производительности: Мониторинг производительности системы, взаимодействия с пользователями и состояния системы в режиме реального времени с помощью интеграции передовых средств аналитики имеет решающее значение для поддержания эффективности системы.
- Интеграция бизнес-аналитики: Интеграция с инструментами бизнес-аналитики позволяет получить ценные сведения, которые помогают принимать решения и определяют стратегию бизнеса.
Передовые системы RAG на уровне предприятия представляют собой сочетание передовых технологий искусственного интеллекта, надежных механизмов обработки данных, безопасной и масштабируемой инфраструктуры, а также возможностей бесшовной интеграции. Сочетание этих элементов позволяет организациям создавать RAG-системы, способные эффективно получать и генерировать информацию, являясь при этом основной частью корпоративной технологической системы. Такие системы не только приносят значительную пользу бизнесу, но и улучшают процессы принятия решений и повышают общую операционную эффективность.
Передовая технология RAG
Передовые системы поиска с расширенным генерированием (RAG) включают в себя ряд технологических инструментов, предназначенных для повышения эффективности и точности на всех этапах обработки. Эти передовые системы RAG способны лучше управлять данными и предоставлять более точные, контекстные ответы благодаря применению передовых технологий на различных этапах процесса, от индексирования и преобразования запросов до поиска и генерации. Ниже приведены некоторые из передовых технологий, используемых для оптимизации каждого этапа процесса RAG:
1. Индекс
Индексирование - ключевой процесс, повышающий точность и эффективность систем больших языковых моделей (LLM). Индексирование - это не просто хранение данных; оно включает в себя систематическую организацию и оптимизацию данных для обеспечения легкого доступа к информации и ее понимания, сохраняя при этом важный контекст. Эффективное индексирование помогает точно и эффективно извлекать данные, позволяя LLM предоставлять релевантные и точные ответы. Некоторые из методов, используемых в процессе индексирования, включают:
Техника 1: Оптимизация текстовых блоков с помощью оптимизации блоков
Цель оптимизации блоков - настроить размер и структуру текстовых блоков таким образом, чтобы они не были слишком большими или слишком маленькими, сохраняя при этом контекст, что улучшает поиск.
Техника 2: Преобразование текста в векторы с помощью расширенных моделей встраивания
После создания блоков текста следующим шагом будет преобразование этих блоков в векторные представления. Этот процесс преобразует текст в числовые векторы, которые отражают его семантическое значение. Такие модели, как семейства вкраплений BGE-large или E5, эффективно отражают все нюансы текста. Эти векторные представления имеют решающее значение для последующего поиска и семантического сопоставления.
Техника 3: Улучшение семантического соответствия путем встраивания точной настройки
Цель тонкой настройки встраивания - улучшить семантическое понимание индексированных данных моделью встраивания, тем самым повысив точность соответствия между полученной информацией и запросом пользователя.
Техника 4: Повышение эффективности поиска с помощью нескольких представлений
Методы мультипредставления преобразуют документы в легкие поисковые единицы, такие как резюме, чтобы ускорить процесс поиска и повысить точность при работе с большими документами.
Техника 5: Использование иерархических индексов для организации данных
Иерархическое индексирование улучшает поиск, структурируя данные на нескольких уровнях, от детального до общего, с помощью таких моделей, как RAPTOR, которые предоставляют широкую и точную контекстную информацию.
Техника 6: Улучшенный поиск данных с помощью вложения метаданных
Методы добавления метаданных добавляют дополнительную информацию к каждому блоку данных для улучшения возможностей анализа и классификации, делая поиск данных более систематическим и контекстным.
2. преобразование запросов
Преобразование запросов направлено на оптимизацию пользовательского ввода и повышение качества поиска информации. Используя LLM, процесс преобразования позволяет сделать сложные или неоднозначные запросы более четкими и конкретными, что повышает общую эффективность и точность поиска.
Техника 1: Использование HyDE (Hypothetical Document Embedding) для улучшения ясности запросов
HyDE повышает релевантность и точность поиска информации, генерируя данные о гипотезах для повышения семантического сходства между вопросами и справочным контентом.
Техника 2: Упрощение сложных запросов с помощью многоступенчатых запросов
Многоступенчатые запросы разбивают сложные вопросы на более простые подвопросы, получают ответы на каждый подвопрос отдельно и объединяют результаты для получения более точного и полного ответа.
Техника 3: Усиление контекста с помощью подсказок обратного хода
Техника обратных подсказок генерирует более широкий общий запрос из сложного исходного запроса, так что контекст помогает создать основу для конкретного запроса, улучшая конечный ответ за счет объединения результатов исходного и более широкого запроса.
Техника 4: Улучшение поиска с помощью переписывания запросов
Техника переписывания запросов использует LLM для изменения формулировки исходного запроса с целью улучшения поиска. И LangChain, и LlamaIndex используют эту технику, причем LlamaIndex предлагает особенно мощную реализацию, которая значительно улучшает поиск.
3. маршрутизация запросов
Роль маршрутизации запросов заключается в оптимизации процесса поиска путем отправки запроса к наиболее подходящему источнику данных на основе характеристик запроса, гарантируя, что каждый запрос будет обработан наиболее подходящим компонентом системы.
Техника 1: Логическая маршрутизация
Логическая маршрутизация оптимизирует поиск, анализируя структуру запроса для выбора наиболее подходящего источника данных или индекса. Такой подход гарантирует, что запрос будет обработан тем источником данных, который лучше всего подходит для получения точного ответа.
Технология 2: семантическая маршрутизация
Семантическая маршрутизация направляет запрос к нужному источнику данных или индексу, анализируя семантический смысл запроса. Она повышает точность поиска за счет понимания контекста и смысла запроса, особенно для сложных и тонких вопросов.
4. Методы предварительного поиска и индексирования данных
Оптимизация предварительного поиска повышает качество и удобство поиска информации в индексе данных или базе знаний. Конкретные методы оптимизации зависят от природы, источника и объема данных. Например, увеличение плотности информации позволяет генерировать более точные ответы с меньшим количеством маркеров, что повышает удобство работы пользователя и снижает затраты. Однако методы оптимизации, которые работают в одной системе, могут не работать в других. Большие языковые модели (БЯМ) предоставляют инструменты для тестирования и настройки этих оптимизаций, позволяя применять индивидуальные подходы для улучшения поиска в различных областях и приложениях.
Техника 1: Использование LLM для повышения плотности информации
Основополагающим шагом в оптимизации системы RAG является повышение качества данных до их индексирования. Использование LLM для очистки, маркировки и обобщения данных позволяет повысить плотность информации, что приводит к более точным и эффективным результатам обработки данных.
Техника 2: Иерархический индексный поиск
Поиск с иерархическим индексированием упрощает процесс поиска за счет создания резюме документов в качестве первого уровня фильтров. Такой многоуровневый подход гарантирует, что на этапе поиска будут рассматриваться только наиболее релевантные данные, что повышает эффективность и точность поиска.
Техника 3: Улучшение симметрии поиска с помощью гипотетических пар вопросов и ответов
Чтобы устранить асимметрию между запросами и документами, эта техника использует LLM для создания гипотетических пар вопросов и ответов из документов. Встраивая эти пары вопросов и ответов в поиск, система может лучше соответствовать запросу пользователя, тем самым улучшая семантическое сходство и уменьшая ошибки поиска.
Техника 4: Дедупликация с помощью LLM
Дублирующаяся информация может быть как полезной, так и вредной для системы RAG. Использование LLM для устранения дублирования блоков данных оптимизирует индексацию данных, снижает уровень шума и повышает вероятность получения точных ответов.
Техника 5: Тестирование и оптимизация стратегий разбивки на части
Эффективная стратегия разбивки на куски имеет решающее значение для поиска. Проведя A/B-тестирование с различными размерами фрагментов и коэффициентами перекрытия, можно найти оптимальный баланс для конкретного случая использования. Это поможет сохранить достаточный контекст, не распыляя и не разбавляя соответствующую информацию слишком тонким слоем.
Техника 6: Использование индекса скользящего окна
Индексирование по скользящему окну позволяет не потерять важную контекстную информацию между сегментами за счет перекрытия блоков данных в процессе индексирования. Такой подход обеспечивает непрерывность данных и повышает релевантность и точность поиска информации.
Техника 7: Повышение детализации данных
Улучшение детализации данных достигается в основном за счет применения методов очистки данных, позволяющих удалить нерелевантную информацию и сохранить в индексе только наиболее точный и актуальный контент. Это повышает качество поиска и гарантирует, что будет рассматриваться только релевантная информация.
Техника 8: Добавление метаданных
Добавление метаданных, таких как дата, цель или раздел, может повысить точность поиска, позволяя системе эффективнее фокусироваться на наиболее релевантных данных и улучшать поиск в целом.
Техника 9: Оптимизация структуры индекса
Оптимизация структуры индексирования включает изменение размера фрагментов и использование нескольких стратегий индексирования, таких как поиск в окне предложения, для улучшения способа хранения и извлечения данных. Встраивая отдельные предложения, сохраняя при этом контекстное окно, этот подход обеспечивает более богатый и контекстуально точный поиск в процессе вывода.
5. методы поиска
На этапе поиска система собирает информацию, необходимую для ответа на запрос пользователя. Передовые поисковые технологии обеспечивают полноту и контекстность найденного контента, закладывая прочную основу для последующих этапов обработки.
Техника 1: Оптимизация поисковых запросов с помощью LLM
LLM оптимизируют поисковый запрос пользователя, чтобы он лучше соответствовал требованиям поисковой системы, будь то простой поиск или сложный диалоговый запрос. Такая оптимизация обеспечивает более целенаправленный и эффективный процесс поиска.
Техника 2: Устранение асимметрии запросов и документов с помощью HyDE
Генерируя гипотетические документы с ответами, техника HyDE улучшает семантическое сходство при поиске и решает проблему асимметрии между короткими запросами и длинными документами.
ТЕХНИКА 3: Реализация маршрутизации запросов или моделирование решений RAG
В системах, использующих несколько источников данных, маршрутизация запросов оптимизирует эффективность поиска, направляя поиск в соответствующую базу данных. Модель принятия решений RAG дополнительно оптимизирует этот процесс, определяя, когда требуется поиск, чтобы сэкономить ресурсы, когда большая языковая модель может ответить самостоятельно.
Техника 4: Глубокое исследование с помощью рекурсивных искателей
Рекурсивный поисковик выполняет дальнейшие запросы на основе предыдущего результата и подходит для глубокого изучения соответствующих данных с целью получения подробной или исчерпывающей информации.
Техника 5: Оптимизация выбора источника данных с помощью маршрутных ретриверов
Routing Retriever использует LLM для динамического выбора наиболее подходящего источника данных или инструмента запроса, чтобы повысить эффективность процесса поиска в зависимости от контекста запроса.
Техника 6: Автоматическое формирование запросов с помощью авторетривера
Авторетривер использует LLM для автоматической генерации фильтров метаданных или запросов, упрощая тем самым процесс запроса к базе данных и оптимизируя поиск информации.
Техника 7: Объединение результатов с помощью объединенного поисковика
Fusion Retriever объединяет результаты нескольких запросов и индексов, обеспечивая комплексное и не дублирующее друг друга представление информации, что гарантирует всесторонний поиск.
Техника 8: Агрегирование контекстов данных с помощью поисковиков автоматического слияния
Auto Merge Retriever объединяет несколько сегментов данных в один единый контекст, повышая релевантность и полноту информации за счет интеграции более мелких контекстов.
Техника 9: Тонкая настройка модели встраивания
Тонкая настройка модели встраивания, позволяющая сделать ее более специфичной для конкретной области, улучшает способность работать со специализированной терминологией. Такой подход повышает релевантность и точность найденной информации за счет более тесного согласования содержимого с конкретным доменом.
Техника 10: Реализация динамического встраивания
Динамические вкрапления выходят за рамки статических представлений, адаптируя векторы слов к контексту, обеспечивая более глубокое понимание языка. Такой подход, например модель OpenAI embeddings-ada-02, более точно улавливает контекстные значения и, следовательно, обеспечивает более точные результаты поиска.
Техника 11: Использование гибридного поиска
Гибридный поиск сочетает векторный поиск с традиционным подбором ключевых слов, обеспечивая как семантическое сходство, так и точное распознавание терминов. Такой подход особенно эффективен в сценариях, где требуется точное распознавание терминов, что обеспечивает полный и точный поиск.
6. методы пост-поиска
После того как соответствующий контент получен, этап пост-поиска фокусируется на том, как эффективно скомпоновать этот контент. Этот этап включает в себя предоставление точной и краткой контекстной информации большой языковой модели (LLM), гарантируя, что система имеет все детали, необходимые для создания последовательных и точных ответов. Качество этой интеграции напрямую определяет релевантность и ясность конечного результата.
Техника 1: Оптимизация результатов поиска с помощью переупорядочивания
После поиска модель переупорядочивает результаты поиска, размещая наиболее релевантные документы ближе к запросу, что повышает качество информации, предоставляемой LLM, и, соответственно, качество конечного ответа. Переупорядочивание не только сокращает количество документов, которые необходимо предоставить LLM, но и действует как фильтр для повышения точности обработки языка.
Техника 2: Оптимизация результатов поиска путем сжатия с помощью контекстных подсказок
LLM может фильтровать и сжимать полученную информацию перед созданием окончательной подсказки. Сжатие помогает LLM сосредоточиться на важной информации, уменьшая избыточную фоновую информацию и удаляя посторонние шумы. Такая оптимизация повышает качество ответа, фокусируя его на важных деталях. Такие фреймворки, как LLMLingua, еще больше улучшают этот процесс, удаляя лишние лексемы, делая подсказки более краткими и эффективными.
Техника 3: Оценка и фильтрация найденных документов путем коррекции RAG
Перед вводом материалов в LLM документы необходимо отобрать и отфильтровать, чтобы удалить неактуальные или менее точные документы. Этот метод гарантирует, что будет использована только высококачественная, релевантная информация, что повышает точность и надежность ответа. Корректирующий RAG использует такую модель, как T5-Large, для оценки релевантности найденных документов и отфильтровывает те, что ниже установленного порога, гарантируя, что только ценная информация будет задействована в создании окончательного ответа.
7. генеративные технологии
На этапе генерации полученная информация оценивается и упорядочивается, чтобы выявить наиболее важное содержание. Передовые технологии на этом этапе предполагают выбор тех ключевых деталей, которые повышают релевантность и надежность ответа. Этот процесс гарантирует, что сгенерированный контент не только отвечает на запрос, но и содержательно подкреплен полученными данными.
Техника 1: Уменьшение шума с помощью советов по цепочке мыслей
Подсказки в виде цепочки мыслей помогают LLM справиться с зашумленной или нерелевантной фоновой информацией, повышая вероятность создания точного ответа даже при наличии помех в данных.
ТЕХНИКА 2: Самоанализ системы с помощью самоРАГ
Самооценка включает в себя обучение модели использованию рефлексивных маркеров во время генерации, чтобы она могла оценивать и улучшать свой собственный результат в режиме реального времени, выбирая лучший ответ на основе фактичности и качества.
Техника 3: Игнорирование посторонних фонов с помощью тонкой настройки
Система RAG была специально настроена таким образом, чтобы повысить способность LLM игнорировать посторонний фон, гарантируя, что только релевантная информация повлияет на окончательный ответ.
Техника 4: Повышение устойчивости LLM к нерелевантному фону с помощью рассуждений на естественном языке
Интеграция моделей вывода на естественном языке (NLI) помогает отфильтровать нерелевантную контекстную информацию, сравнивая полученный контекст с генерируемым ответом, гарантируя, что только релевантная информация влияет на конечный результат.
Техника 5: Управление получением данных с помощью FLARE
FLARE (Flexible Language Modelling Adaptation for Retrieval Enhancement) - это подход, основанный на инженерии подсказок, который гарантирует, что LLM извлекает данные только тогда, когда это необходимо. Он постоянно адаптирует запрос и проверяет наличие ключевых слов с низкой вероятностью, которые вызывают поиск релевантных документов, чтобы повысить точность ответа.
Техника 6: Улучшение качества ответа с помощью ITER-RETGEN
ITER-RETGEN (Iterative Retrieval-Generation) улучшает качество ответа путем итеративного выполнения процесса генерации. Каждая итерация использует предыдущий результат в качестве контекста для получения более релевантной информации, таким образом постоянно улучшая качество и релевантность конечного ответа.
Техника 7: Прояснение вопросов с помощью ToC (дерево прояснения)
ToC рекурсивно генерирует конкретные вопросы, чтобы прояснить двусмысленность исходного запроса. Этот подход совершенствует процесс "вопрос-ответ", постоянно оценивая и уточняя исходный вопрос, что приводит к получению более подробного и точного окончательного ответа.
8. Оценка
В передовых технологиях Retrieval Augmented Generation (RAG) процесс оценки имеет решающее значение для обеспечения точности и релевантности найденной и синтезированной информации запросу пользователя. Процесс оценки состоит из двух ключевых компонентов: оценки качества и требуемых возможностей.
Оценка качества сосредоточена на измерении точности и релевантности контента:
- Фон Актуальность. Оцените применимость полученной или сгенерированной информации в конкретном контексте запроса. Убедитесь, что ответ точен и соответствует потребностям пользователя.
- Верность ответа. Проверьте, что созданные ответы точно отражают полученные данные и не содержат ошибок или вводящей в заблуждение информации. Это необходимо для поддержания надежности результатов работы системы.
- Актуальность ответа. Оцените, насколько прямо и эффективно сгенерированный ответ отвечает на запрос пользователя, и убедитесь, что ответ полезен и соответствует сути вопроса.
Требуемые возможности - это те, которыми должна обладать система для получения высококачественных результатов:
- Устойчивость к шуму. Измерьте способность системы фильтровать посторонние или зашумленные данные, чтобы эти помехи не влияли на качество конечного ответа.
- Негативный отказ. Проверьте эффективность системы в распознавании и исключении ошибочной или нерелевантной информации из генерируемых результатов.
- Интеграция информации. Оцените способность системы интегрировать множество частей релевантной информации в последовательный, всеобъемлющий ответ, который дает пользователю полный ответ.
- Контрфактическая устойчивость. Проверьте работу системы при работе с гипотетическими или контрфактическими сценариями, чтобы убедиться, что ответы остаются точными и надежными даже при работе со спекулятивными вопросами.
Вместе эти компоненты оценки гарантируют, что система Advanced RAG дает точный и релевантный ответ, надежный, достоверный и адаптированный к конкретным потребностям пользователя.
Дополнительные технологии
Чат-движок: расширение диалога в системе RAG
Интеграция чата в продвинутую систему Retrieval Augmented Generation (RAG) повышает способность системы обрабатывать последующие вопросы и сохранять контекст диалога, подобно традиционной технологии чатботов. Различные реализации предлагают разные уровни сложности:
- Контекстная система чата: Этот подход направляет ответ Большой языковой модели (LLM), извлекая контекст, относящийся к запросу пользователя, включая предыдущие чаты. Это гарантирует, что диалог будет связным и контекстуально подходящим.
- Концентрация плюс контекстные режимы: Это более продвинутый подход, который сводит журналы чата и последние сообщения каждого взаимодействия в оптимизированный запрос. Этот уточненный запрос берет соответствующий контекст и объединяет его с исходным сообщением пользователя, чтобы предоставить его LLM для создания более точного и контекстуального ответа.
Эти реализации помогают улучшить согласованность и релевантность диалога в системе RAG и обеспечивают различные уровни сложности в зависимости от потребностей.
Цитирование ссылок: следите за точностью источников
Обеспечение точности ссылок очень важно, особенно когда в создании ответов участвует несколько источников. Этого можно добиться несколькими способами:
- Прямая маркировка источника: Постановка задачи в подсказке языковой модели (LLM) требует, чтобы источник был непосредственно обозначен в генерируемом ответе. Такой подход позволяет четко обозначить первоисточник.
- Техника нечеткого сопоставления: Методы нечеткого сопоставления, подобные тем, что используются в LlamaIndex, применяются для совмещения частей сгенерированного контента с блоками текста в исходном индексе. Нечеткое сопоставление повышает точность контента и гарантирует, что он отражает исходную информацию.
Применяя эти стратегии, можно значительно повысить точность и надежность ссылок, гарантируя, что полученные ответы будут достоверными и обоснованными.
Агенты в дополненной генерации поиска (RAG)
Агенты играют важную роль в повышении производительности систем Retrieval Augmented Generation (RAG), предоставляя дополнительные инструменты и функциональность Большой языковой модели (LLM) для расширения ее возможностей. Изначально представленные в API LLM, эти агенты позволяют LLM использовать преимущества внешних функций кода, API и даже других LLM для расширения их функциональности.
Одним из важных применений агентов является поиск по нескольким документам. Например, недавние ассистенты OpenAI демонстрируют достижения в этой области. Эти ассистенты дополняют традиционные LLM, интегрируя такие функции, как журналы чатов, хранилища знаний, интерфейсы загрузки документов и API вызовов функций, которые преобразуют естественный язык в выполнимые команды.
Использование агентов также распространяется на управление несколькими документами, когда каждый документ обрабатывается специальным агентом, например, резюме и викторины. Центральный агент высокого уровня контролирует этих агентов по конкретным документам, направляя запросы и консолидируя ответы. Такая система поддерживает сложные сравнения и анализ нескольких документов, демонстрируя передовые методы RAG.
Ответ на Синтезатор: создание окончательного ответа
Последним шагом в процессе RAG является синтез полученного контекста и первоначального запроса пользователя в ответ. Помимо прямого объединения контекста с запросом и его обработки через LLM, существуют и более тонкие подходы:
- Итеративная оптимизация: Разделение полученного контекста на более мелкие части оптимизирует ответ за счет многократного взаимодействия с LLM.
- Контекстное резюме: Сжатие большого объема контекста в рамках подсказок LLM гарантирует, что ответы останутся целенаправленными и актуальными.
- Генерация нескольких ответов: Сгенерируйте несколько ответов от разных сегментов контекста, а затем объедините их в единый ответ.
Эти методы повышают качество и точность ответов системы RAG, демонстрируя потенциал передовых методов синтеза ответов.
Использование этих передовых технологий RAG может значительно повысить производительность и надежность системы. Оптимизируя процесс на каждом этапе, от предварительной обработки данных до генерации ответа, компании могут создавать более точные, эффективные и мощные приложения искусственного интеллекта.
Расширенные приложения и кейсы RAG
Передовые системы Retrieval Augmented Generation (RAG) используются в самых разных областях для улучшения анализа данных, принятия решений и взаимодействия с пользователями благодаря мощным возможностям обработки и генерации данных. От маркетинговых исследований до поддержки клиентов и создания контента - передовые системы RAG продемонстрировали значительные преимущества во многих областях. Конкретные примеры применения этих систем в различных областях описаны ниже:
1. Исследование рынка и конкурентный анализ
- интеграция данных: Система RAG способна интегрировать и анализировать данные из различных источников, таких как социальные сети, новостные статьи и отраслевые отчеты.
- Определение тенденций: Обрабатывая большие объемы данных, система RAG способна выявлять зарождающиеся тенденции на рынке и изменения в поведении потребителей.
- Информация о конкурентах: Система предоставляет подробные стратегии и анализ деятельности конкурентов, помогая компаниям проводить самооценку и сравнительный анализ.
- практические выводыБизнес может использовать эти отчеты для стратегического планирования и принятия решений.
2. Поддержка и взаимодействие с клиентами
- Ответы с учетом контекста: Система RAG извлекает необходимую информацию из базы знаний, чтобы предоставить клиентам точные и контекстуальные ответы.
- Снижение рабочей нагрузки: Автоматизация общих проблем снимает нагрузку с команды ручной поддержки, позволяя им решать более сложные задачи.
- Индивидуальное обслуживание: Система настраивает ответы и взаимодействие в соответствии с индивидуальными потребностями, анализируя историю и предпочтения клиентов.
- Повышение интерактивности: Высококачественные службы поддержки повышают удовлетворенность клиентов и укрепляют отношения с ними.
3. Соблюдение нормативных требований и управление рисками
- Анализ нормативно-правовой базы: Система RAG сканирует и интерпретирует юридические документы и нормативные инструкции для обеспечения соответствия.
- выявление рисков: Система быстро выявляет потенциальные риски соответствия нормативным требованиям, сравнивая внутренние политики с внешними нормативными актами.
- Рекомендации по соблюдению: Предоставление практических советов, которые помогут компаниям устранить пробелы в нормативно-правовом регулировании и снизить правовые риски.
- Эффективная отчетность: Генерируйте отчеты и сводки о соответствии, которые легко поддаются аудиту и проверке.
4. Разработка продуктов и инновации
- Анализ отзывов клиентов: Система RAG анализирует отзывы клиентов, чтобы выявить общие проблемы и болевые точки.
- Анализ рынка: Отслеживать новые тенденции и потребности клиентов, чтобы направлять разработку продуктов.
- Инновационные предложения: Предоставление потенциальных возможностей продукта и рекомендаций по улучшению на основе анализа данных.
- конкурентное позиционирование: Помогать компаниям разрабатывать продукты, которые отвечают потребностям рынка и выделяются на фоне конкурентов.
5. Финансовый анализ и прогнозирование
- интеграция данных: Система RAG объединяет финансовые данные, рыночные условия и экономические показатели для всестороннего анализа.
- Анализ тенденций: Выявление закономерностей и тенденций на финансовых рынках для помощи в прогнозировании и принятии инвестиционных решений.
- инвестиционный совет: Предоставление практических рекомендаций по инвестиционным возможностям и факторам риска.
- стратегическое планирование: Поддержка принятия стратегических финансовых решений с помощью точных прогнозов и рекомендаций, основанных на данных.
6. Семантический поиск и эффективное извлечение информации
- понимание контекста: Система RAG выполняет семантический поиск, понимая контекст и смысл пользовательских запросов.
- Соответствующие результаты:: Повышение эффективности поиска за счет извлечения наиболее релевантной и точной информации из больших объемов данных.
- экономить время:: Оптимизация процесса поиска данных и сокращение времени, затрачиваемого на поиск информации.
- Повышение точности: Обеспечивает более точные результаты поиска по сравнению с традиционными методами поиска по ключевым словам.
7. Повышение эффективности создания контента
- Интеграция трендов: Система RAG использует самые последние данные, чтобы обеспечить соответствие создаваемого контента текущим тенденциям рынка и интересам аудитории.
- Автоматическое создание контента:: Автоматическое генерирование идей и проектов контента на основе тем и целевой аудитории.
- Расширение участия: Генерируйте более интересный и релевантный контент для улучшения взаимодействия с пользователями.
- своевременное обновление:: Следить за тем, чтобы содержание отражало последние события и изменения на рынке и оставалось актуальным.
8. краткое содержание текста
- Основные моменты: Система RAG позволяет эффективно обобщать длинные документы, выделяя ключевые моменты и важные выводы.
- экономить время: Сэкономьте время на чтении благодаря кратким резюме отчетов для занятых руководителей и менеджеров.
- сосредоточиться на:: Выделите ключевые сообщения, чтобы помочь лицам, принимающим решения, быстро понять основные моменты.
- Повышение эффективности принятия решений:: Предоставление актуальной информации в легкой для понимания форме для повышения эффективности принятия решений.
9. Продвинутая система вопросов и ответов
- Точные ответы: Система RAG извлекает данные из широкого спектра источников информации для получения точных ответов на сложные вопросы.
- Расширение доступа:: Расширение доступа к информации в различных областях, таких как здравоохранение или финансы.
- контекстно-зависимый:: Предоставление целевых ответов, основанных на конкретных потребностях и вопросах пользователя.
- Сложные вопросы:: Решение сложных вопросов путем интеграции многочисленных источников информации.
10. Диалоговые агенты и чат-боты
- контекстная информация: Система RAG улучшает взаимодействие между чат-ботами и виртуальными помощниками, предоставляя соответствующую контекстную информацию.
- Повышение точности:: Убедитесь, что ответы агентов по диалогу точны и информативны.
- поддержка пользователей:: Улучшение качества обслуживания пользователей за счет создания интеллектуального и отзывчивого диалогового интерфейса.
- Интерактивная природа:: Получение релевантных данных в режиме реального времени, чтобы сделать взаимодействие более естественным и увлекательным.
11. поиск информации
- Расширенный поиск: Повышение точности поисковых систем благодаря возможностям RAG по поиску и генерации информации.
- Генерация информационных фрагментов: Генерируйте эффективные фрагменты информации для повышения удобства пользователей.
- Улучшенные результаты поиска:: Обогащение результатов поиска ответами, сгенерированными системой RAG, для улучшения разрешения запросов.
- система знаний: Используйте данные компании для ответов на внутренние вопросы, например о политике в области управления персоналом или о соблюдении нормативных требований, чтобы облегчить доступ к информации.
12. Персональные рекомендации
- Анализ данных о клиентах: Генерируйте персональные рекомендации по товарам, анализируя прошлые покупки и отзывы.
- Улучшение впечатления от покупок:: Улучшение качества покупок путем рекомендации товаров на основе личных предпочтений.
- увеличивать доход: Рекомендовать соответствующие продукты, основываясь на поведении клиентов, чтобы увеличить продажи.
- подбор места на рынке:: Соотнесите рекомендуемый контент с текущими тенденциями рынка, чтобы удовлетворить меняющиеся потребности клиентов.
13. завершение текста
- контекстное дополнение:: Система RAG завершает части текста в соответствии с контекстом.
- повышение эффективности:: Обеспечение точных завершений для упрощения задач, таких как написание электронных писем или кода.
- Повышение производительности:: Сократите время, необходимое для выполнения задач по написанию и кодированию, и повысьте производительность.
- Соблюдение последовательности:: Убедитесь, что дополнения к тексту соответствуют существующему содержанию и тону.
14. Анализ данных
- Полная интеграция данных:: Система RAG объединяет данные из внутренних баз данных, рыночных отчетов и внешних источников, обеспечивая всесторонний обзор и глубокий анализ.
- точный прогноз:: Повышение точности прогнозов путем анализа последних данных, тенденций и исторической информации.
- Insight Discovery:: Анализ обширных массивов данных для выявления и оценки новых возможностей и предоставления ценных сведений для роста и совершенствования.
- Рекомендации, основанные на данных:: Предоставление рекомендаций, основанных на данных, путем анализа обширных массивов данных для поддержки принятия стратегических решений и повышения общего качества принимаемых решений.
15. задача перевода
- поиск перевода:: Получение релевантных переводов из баз данных для решения переводческих задач.
- Генерация контекста:: Генерирование последовательных переводов на основе контекста и со ссылкой на полученный корпус.
- Повышение точности:: Использование данных из нескольких источников для повышения точности переводов.
- повышение эффективности: Оптимизация процесса перевода за счет автоматизации и создания контекстно-зависимых текстов.
16. Анализ отзывов клиентов
- комплексный анализ:: Анализ отзывов из различных источников, чтобы получить полное представление о настроениях и проблемах клиентов.
- проницательность: Предоставляйте подробные сведения, раскрывающие повторяющиеся темы и болевые точки клиентов.
- интеграция данных: Интегрировать отзывы из внутренних баз данных, социальных сетей и отзывов для всестороннего анализа.
- Информативное принятие решений:: Принимайте более быстрые и разумные решения на основе отзывов клиентов для улучшения продуктов и услуг.
Эти приложения демонстрируют широкий спектр возможностей передовых систем RAG, показывая их способность повышать эффективность, точность и проницательность. Будь то улучшение поддержки клиентов, проведение маркетинговых исследований или оптимизация анализа данных, передовые системы RAG предоставляют бесценные решения, способствующие принятию стратегических решений и повышению операционной эффективности.
Создание инструментов диалога с помощью расширенного RAG
Инструменты диалогового искусственного интеллекта играют важнейшую роль в современном взаимодействии с пользователями, обеспечивая яркую и быструю обратную связь на различных платформах. Мы можем поднять возможности этих инструментов на совершенно новый уровень, интегрировав в них передовую систему Retrieval Augmented Generation (RAG), которая сочетает мощный поиск информации с передовыми методами генерации, чтобы диалоги были одновременно информативными и поддерживали естественный поток общения. Будучи встроенной в инструмент искусственного интеллекта для ведения диалога, система RAG предоставляет пользователям точные и богатые контекстом ответы, сохраняя при этом естественный ритм диалога. В этом разделе рассматривается, как RAG может быть использована для создания продвинутых диалоговых инструментов, выделяются ключевые элементы, на которых следует сосредоточиться при создании таких систем, а также то, как сделать их эффективными и практичными в реальных приложениях.
Разработка процесса диалога
Сердцем любого диалогового инструмента является его диалоговый поток - то есть этапы, на которых система обрабатывает пользовательский ввод и генерирует ответы. Для продвинутых инструментов, основанных на RAG, необходимо тщательно планировать диалоговый поток, чтобы использовать все преимущества поисковых возможностей системы RAG и генерации языковых моделей. Как правило, этот поток состоит из нескольких ключевых этапов:
Оценка и рефрейминг проблем::
- Сначала система оценивает вопрос, заданный пользователем, и определяет, нужно ли его переформатировать, чтобы обеспечить контекст, необходимый для точного ответа. Если вопрос слишком расплывчатый или в нем отсутствуют ключевые детали, система может переформатировать его в отдельный запрос, обеспечив включение всей необходимой информации.
Проверка релевантности и маршрутизация::
- После того как вопрос правильно отформатирован, система ищет соответствующие данные в векторном хранилище (базе данных, содержащей индексированную информацию). Если соответствующая информация найдена, вопрос передается приложению RAG, которое извлекает необходимую информацию для создания ответа.
- Если в хранилище векторов нет релевантной информации, система должна решить, продолжать ли использовать ответ, сгенерированный только языковой моделью, или запросить у системы RAG сообщение о том, что удовлетворительный ответ не может быть предоставлен.
Генерирование ответа::
- В зависимости от решений, принятых на предыдущем этапе, система либо использует полученные данные для генерации подробных ответов, либо опирается на знания языковой модели и историю диалога, чтобы ответить пользователю. Такой подход гарантирует, что инструмент способен решать реальные проблемы и в то же время позволяет вести диалоги в более непринужденной, открытой форме.
Оптимизация процессов диалога с использованием механизмов принятия решений
Важным аспектом при создании продвинутых диалоговых инструментов RAG является реализация механизмов принятия решений, которые управляют ходом диалога. Эти механизмы помогают системе разумно решать, когда следует получить информацию, когда полагаться на генеративные возможности, а когда сообщить пользователю об отсутствии нужных данных. Благодаря этим решениям инструмент может стать более гибким и адаптироваться к различным сценариям диалога.
- Решение 1: изобретать или продолжать?
Сначала система решает, можно ли обработать вопрос пользователя как есть или его нужно переформулировать. Этот шаг гарантирует, что система поймет намерения пользователя и получит весь необходимый контекст для эффективного поиска или генерации информации, прежде чем генерировать ответ. - Решение 2: Извлечь или сгенерировать?
В случае необходимости ремоделирования система определяет, есть ли соответствующая информация в векторном хранилище. Если релевантные данные найдены, система использует RAG для поиска и генерации ответа. Если нет, система должна решить, стоит ли полагаться только на языковую модель для генерации ответа. - Решение 3: информировать или взаимодействовать?
Если ни векторное хранилище, ни языковая модель не могут дать удовлетворительного ответа, система сообщает пользователю об отсутствии необходимой информации, тем самым сохраняя прозрачность и достоверность диалога.
Как разработать эффективные подсказки для разговорных RAG
Подсказки играют ключевую роль в управлении разговорным поведением языковых моделей. Разработка эффективных подсказок требует четкого понимания контекстной информации, целей взаимодействия, а также желаемого стиля и тона. Пример:
- справочная информация: Предоставьте соответствующую контекстуальную информацию, чтобы языковая модель улавливала необходимый контекст при создании или адаптации вопросов.
- Советы, ориентированные на достижение цели: Уточните цель каждой подсказки, например, чтобы составить вопрос, выбрать процесс поиска или сгенерировать ответ.
- Стиль и тон: Укажите желаемый стиль (например, официальный, непринужденный) и тон (например, информативный, сочувственный), чтобы гарантировать, что вывод языковой модели соответствует ожиданиям пользователей.
Создание диалоговых инструментов с использованием передовых методов RAG требует комплексной стратегии, сочетающей сильные стороны поиска и генерации. Тщательно продумывая диалоговые потоки, внедряя интеллектуальные механизмы принятия решений и разрабатывая эффективные подсказки, разработчики могут создавать инструменты ИИ, которые обеспечивают как точные и богатые контекстом ответы, так и естественное, осмысленное взаимодействие с пользователями.
Как создавать продвинутые приложения RAG?
Конечно, хорошо начать с создания базового приложения Retrieval Augmented Generation (RAG), но чтобы реализовать весь потенциал RAG в более сложных сценариях, необходимо выйти за рамки основ. В этом разделе описывается, как создать продвинутое приложение RAG, которое улучшает процесс поиска, повышает точность ответа и реализует такие продвинутые техники, как переписывание запросов и многоступенчатый поиск.
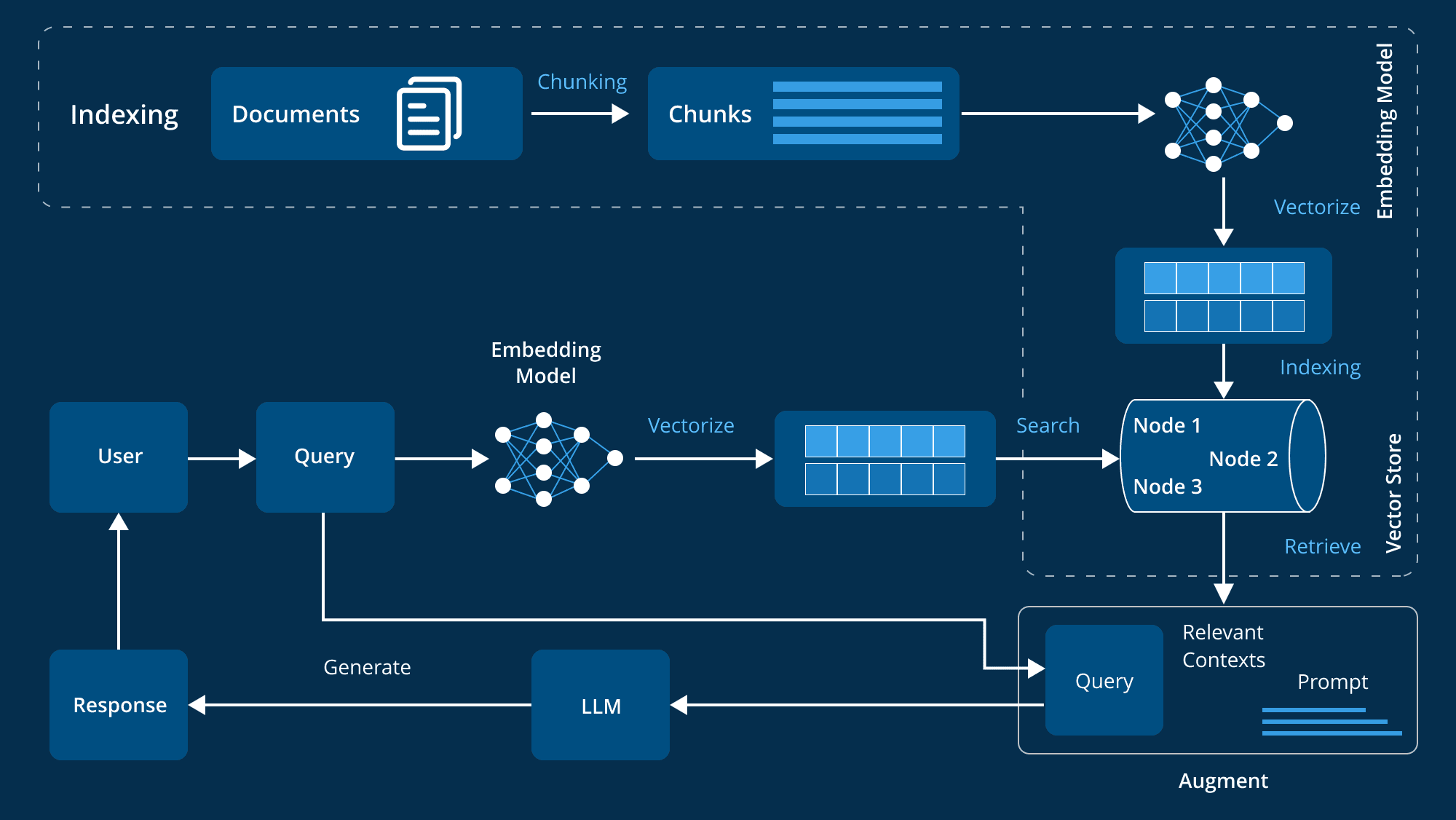
Прежде чем перейти к продвинутым техникам, кратко рассмотрим базовую функциональность приложения RAG, которое объединяет возможности языковой модели (LLM) и внешней базы знаний для ответа на запросы пользователя. Этот процесс обычно состоит из двух этапов:
- получить (данные): Приложение ищет фрагменты текста из векторных баз данных или других баз знаний, которые соответствуют запросу пользователя.
- читать: Полученный текст передается в LLM для создания ответа на основе этих контекстов.
Такой подход "ищи и читай" обеспечивает LLM справочной информацией, необходимой для предоставления более точных ответов на запросы, требующие специальных знаний.
Построить продвинутое приложение RAG можно следующим образом:
Шаг 1: Используйте передовые методы для улучшения поиска
Этап поиска имеет решающее значение для качества конечного ответа. В базовом приложении RAG процесс поиска относительно прост, но в расширенном приложении RAG вы можете использовать следующие усовершенствования:
1. Многоступенчатый поиск
Многоступенчатый поиск помогает найти наиболее релевантные контексты путем многоступенчатого уточнения поиска. Обычно он включает в себя:
- Первоначальный широкий поиск: Начните с широкого поиска по целому ряду потенциально релевантных документов.
- Уточните поиск: Более точный поиск на основе предварительных результатов, суженный до наиболее релевантных сегментов.
Этот метод повышает точность найденной информации, что, в свою очередь, позволяет получить более точные ответы.
2. Переписывание запросов
Переписывание запросов преобразует запрос пользователя в формат, который с большей вероятностью даст релевантные результаты при поиске. Этого можно добиться несколькими способами:
- Переписывание с нулевой выборкой: Переписывайте запросы без конкретных примеров, полагаясь на лингвистическое понимание модели.
- Образец меньше переписывать: Приведены примеры, помогающие моделям переписывать похожие запросы для повышения точности.
- Рерайтеры на заказ: Уточните модель, предназначенную для переписывания запросов, чтобы лучше обрабатывать запросы, специфичные для конкретной области.
Эти переписанные запросы лучше соответствуют языку и структуре документов в базе знаний, что повышает точность поиска.
3. Декомпозиция подзапросов
Для сложных запросов, включающих несколько вопросов или аспектов, декомпозиция запроса на несколько подзапросов может улучшить поиск. Каждый подзапрос фокусируется на определенном аспекте исходного вопроса, так что система может получить соответствующий контекст для каждой части и объединить ответы.
Шаг 2: Улучшение генерации ответов
После того как вы улучшили процесс поиска, следующим шагом будет оптимизация того, как Большая языковая модель генерирует ответы:
1. Советы по отступлению
При столкновении со сложными или многоуровневыми вопросами может оказаться полезным создание дополнительных, более широких запросов. Эти "запасные" подсказки помогут получить более широкий спектр контекстной информации, что позволит Большой языковой модели генерировать более полные ответы.
2. встраивание гипотетического документа (HyDE)
HyDE - это современная технология, которая позволяет уловить смысл запроса путем создания гипотетических документов на основе запроса пользователя, а затем использовать эти документы для поиска соответствующих реальных документов в базе знаний. Этот подход особенно удобен для использования, когда запрос не имеет семантического сходства с соответствующим контекстом.
Шаг 3: Интеграция контуров обратной связи
Чтобы постоянно улучшать работу приложений RAG, важно интегрировать в систему контуры обратной связи:
1. отзывы пользователей
Включите механизм, позволяющий пользователям оценивать релевантность и точность ответов. Эта обратная связь может быть использована для корректировки процесса поиска и генерации.
2. Расширенное обучение
Используя методы обучения с подкреплением, модели обучаются на основе отзывов пользователей и других показателей эффективности. Это позволяет системе учиться на своих ошибках и со временем повышать точность и релевантность.
Шаг 4: Расширение и оптимизация
По мере развития приложений RAG масштабирование и оптимизация производительности становятся все более важными:
1. распределенный поиск
Для того чтобы справиться с крупными базами знаний, применяются распределенные поисковые системы, которые могут обрабатывать поисковые задачи параллельно на нескольких узлах, тем самым уменьшая задержки и увеличивая скорость обработки.
2. стратегия кэширования
Реализация стратегии кэширования для хранения часто используемых контекстных блоков снижает необходимость повторного поиска и ускоряет время отклика.
3. Оптимизация модели
Оптимизация больших языковых моделей и других моделей, используемых в приложении, для снижения вычислительной нагрузки при сохранении точности. Здесь очень полезны такие техники, как дистилляция моделей и квантификация.
Создание продвинутого приложения RAG требует глубокого понимания механизмов поиска и моделей генерации, а также умения внедрять и оптимизировать сложные технологии. Выполнив описанные выше шаги, вы сможете создать продвинутую систему RAG, которая превзойдет ожидания пользователей и обеспечит высококачественные, контекстуально точные ответы для различных сценариев применения.
Возвышение графиков знаний в продвинутых RAG
Роль графов знаний в системах расширенного поиска (RAG) становится особенно важной, поскольку организации все больше полагаются на искусственный интеллект при решении сложных задач, основанных на данных.По данным компании Gartner. Граф знаний - одна из передовых технологий, которая обещает в будущем разрушить несколько рынков.Gartner'sНовые технологии, влияющие на радиолокацию отмечает, что графы знаний являются основными вспомогательными инструментами для передовых приложений ИИ, они обеспечивают основу для управления данными, возможности рассуждений и надежность результатов ИИ. Это привело к широкому использованию графов знаний в различных отраслях, таких как здравоохранение, финансы и розничная торговля.
Что такое Граф знаний?
Граф знаний - это структурированное представление информации, в котором сущности (узлы) и отношения между ними (ребра) определены в явном виде. Эти сущности могут быть конкретными объектами (например, людьми и местами) или абстрактными понятиями. Отношения между сущностями помогают построить сеть знаний, которая делает поиск данных, рассуждения и выводы более когнитивными для человека. Граф знаний не просто хранит данные, он отражает богатые и тонкие взаимосвязи внутри области, что делает его мощным инструментом в приложениях ИИ.
Расширение и планирование запросов с помощью графов знаний
Расширение запросов - это решение проблемы неясных вопросов в системе RAG. Цель состоит в том, чтобы добавить необходимый контекст к запросу, чтобы даже неясные вопросы могли быть точно интерпретированы. Например, в финансовой сфере такие вопросы, как "Каковы текущие проблемы при внедрении финансового регулирования?" Такие вопросы, как "Каковы текущие проблемы при внедрении финансового регулирования?", могут быть расширены за счет включения в них конкретных сущностей, таких как "соблюдение требований AML" или "процесс KYC", чтобы сосредоточить процесс поиска на наиболее релевантной информации.
В юридической сфере вопросы типа "Какие риски связаны с договорами?" можно дополнить, добавив конкретные типы договоров, например "трудовой договор" или "договор об оказании услуг", на основе контекста, предоставляемого графом знаний.
Планирование запросов, с другой стороны, разбивает сложные запросы на управляемые части, создавая подвопросы. Это гарантирует, что система RAG сможет получить и интегрировать наиболее релевантную информацию для предоставления исчерпывающего ответа. Например, чтобы ответить на вопрос "Как новые стандарты финансовой отчетности повлияют на компанию?" система может сначала получить данные об отдельных стандартах отчетности, сроках внедрения и историческом влиянии на различные области.
В области медицины вопрос типа "Каковы последние достижения в области медицинского оборудования?" может быть разбит на подвопросы, изучающие достижения в конкретных областях, таких как "имплантируемые устройства", "диагностические устройства" или "хирургические инструменты", что гарантирует, что система получит подробную и релевантную информацию из каждой подкатегории. подробную и релевантную информацию из каждой подкатегории.
Благодаря усовершенствованию и планированию запросов Knowledge Graph помогает оптимизировать и структурировать запросы для повышения точности и релевантности поиска информации, что в конечном итоге обеспечивает более точные и полезные ответы в таких сложных областях, как финансы, право и здравоохранение.
Роль графов знаний в RAG
В системах генерации с расширенным поиском (RAG) графы знаний улучшают процесс поиска и генерации, предоставляя структурированные и богатые контекстом данные. Традиционные системы RAG опираются на неструктурированный текст и векторные базы данных, что может привести к неточному или неполному поиску информации. Благодаря интеграции графов знаний системы RAG могут:
- Улучшенное понимание запросов: Графы знаний помогают системе лучше понять контекст и взаимосвязи запроса и, таким образом, получить релевантные данные более точно.
- Усовершенствованная генерация ответов: Структурированные данные, предоставляемые Knowledge Graph, могут генерировать более последовательные, контекстуально релевантные ответы, снижая риск ошибок ИИ.
- Реализация сложных рассуждений: Графы знаний поддерживают многоходовые рассуждения, в которых система может выводить новые знания или соединять разрозненную информацию, проходя через множество связей.
Ключевые компоненты графа знаний
Граф знаний состоит из следующих основных компонентов:
- Узлы: Представляет различные сущности или понятия в области знаний, такие как люди, места или вещи.
- Бок: Опишите отношения между узлами, показывая, как эти сущности взаимосвязаны.
- Атрибуты: Дополнительная информация или метаданные, связанные с узлами и ребрами, которые обеспечивают больший контекст или детализацию.
- Триада: Основные строительные блоки графа знаний, содержащие тему, предикат и объект (например, "Эйнштейн" [тема] "открытие" [предикат] "относительность" [объект ]), эти тройки создают базовую основу для описания отношений между сущностями.
Методология Knowledge Graph-RAG
Методология KG-RAG состоит из трех основных этапов:
- KG Construction: Этот этап заключается в преобразовании неструктурированных текстовых данных в структурированный граф знаний, обеспечивающий упорядоченность и релевантность данных.
- Извлечено: Используя новый алгоритм поиска, названный "Цепочка исследования" (CoE), система осуществляет поиск данных через граф знаний.
- Генерация ответов: Наконец, полученная информация используется для создания связных и контекстуализированных ответов, сочетая структурированные данные Графа знаний с возможностями большой языковой модели.
Эта методология подчеркивает важную роль структурированных знаний в улучшении процесса поиска и генерации информации в системах RAG.
Преимущества графиков знаний в RAG
Включение Knowledge Graph в систему RAG дает несколько существенных преимуществ:
- Структурированное представление знаний: Графы знаний организуют информацию таким образом, чтобы отразить сложные взаимосвязи между объектами, что делает поиск и использование данных более эффективным.
- Контекстное понимание: Графы знаний предоставляют более богатую контекстную информацию, отражая взаимосвязи между объектами, что позволяет системе RAG генерировать более релевантные и согласованные ответы.
- Умение рассуждать: Сопоставление знаний помогает системе получать новые знания, анализируя связи между сущностями, чтобы генерировать более полные и точные ответы.
- Интеграция знаний: Графы знаний могут объединять информацию из разных источников, обеспечивая более полное представление о данных и помогая принимать более эффективные решения.
- Интерпретируемость и прозрачность: Структурированность графа знаний делает путь рассуждений ясным и понятным, облегчает объяснение процесса формирования выводов и повышает доверие к системе.
Интеграция КГ с LLM-RAG
Использование графов знаний в сочетании с моделированием большого языка (LLM) в системах RAG расширяет общие возможности представления знаний и рассуждений. Такая комбинация позволяет динамически объединять знания, обеспечивая актуальность и релевантность информации на момент вывода, что позволяет генерировать более точные и глубокие ответы. LLM может использовать как структурированные, так и неструктурированные данные для получения более качественных результатов.
Использование графиков знаний в викторинах "Цепочка мыслей
Составление карт знаний находит все большее применение в викторинах с цепочкой мыслей, особенно если они используются в сочетании с моделированием большого языка (LLM). Этот подход работает путем разбиения сложных вопросов на подвопросы, извлечения релевантной информации и ее синтеза для формирования окончательного ответа. Графы знаний предоставляют структурированную информацию в этом процессе, повышая способность LLM к рассуждению.
Например, агент LLM может сначала использовать граф знаний для определения релевантных сущностей в запросе, затем получить дополнительную информацию из разных источников и, наконец, сгенерировать исчерпывающий ответ, отражающий взаимосвязанные знания в графе.
Практическое применение графов знаний
В прошлом графы знаний использовались в основном в областях с интенсивным использованием данных, таких как аналитика больших данных и корпоративные поисковые системы, где их роль заключалась в поддержании согласованности и единообразия между различными хранилищами данных. Однако с развитием систем RAG, управляемых большими языковыми моделями, графы знаний нашли новые сценарии применения. Теперь они служат структурированным дополнением к вероятностным большим языковым моделям, помогая уменьшить количество ложной информации, обеспечить больший контекст, а также выступают в качестве механизма запоминания и персонализации в системах ИИ.
Представляем вам GraphRAG
GraphRAG - это современная методология поиска, объединяющая графы знаний и векторные базы данных в архитектуре RAG (Retrieval Augmented Generation). Эта гибридная модель использует сильные стороны обеих систем для создания более точных, контекстуально обоснованных и простых для понимания решений в области искусственного интеллекта.Компания Gartner заявила. Растущее значение графов знаний для совершенствования продуктовой стратегии и создания новых сценариев применения ИИ.
Возможности GraphRAG включают:
- Повышенная точность: Объединяя структурированные и неструктурированные данные, GraphRAG способен дать более точные и исчерпывающие ответы.
- Масштабируемость: Такой подход упрощает разработку и обслуживание приложений RAG и обеспечивает лучшую масштабируемость.
- Интерпретируемость: GraphRAG обеспечивает четкие пути вывода, которые повышают прозрачность системы, делая результаты работы ИИ более понятными и достоверными.
Преимущества GraphRAG
GraphRAG имеет ряд существенных преимуществ перед традиционными методами RAG:
- Более качественные ответы: Интеграция Графа знаний повысила точность и релевантность ответов, генерируемых искусственным интеллектом, а недавние контрольные показатели показали трехкратное повышение точности.
- Экономическая эффективность: GraphRAG более экономичен, требует меньше вычислительных ресурсов и данных для обучения и является привлекательным вариантом для организаций, стремящихся оптимизировать свои инвестиции в ИИ.
- Улучшенная масштабируемость: Такой подход поддерживает крупномасштабные приложения ИИ, позволяя организациям легко обрабатывать более сложные запросы и большие массивы данных.
- Улучшенная интерпретируемость: Структурированный подход GraphRAG обеспечивает более четкие пути вывода, делая процесс принятия решений ИИ более прозрачным и легким для отладки.
- Раскрытие скрытых связей: Графы знаний могут выявить взаимосвязи, которые остаются незамеченными в больших массивах данных, обеспечивая более глубокое понимание и повышая качество процесса принятия решений.
Общие архитектуры GraphRAG
Появилось несколько архитектур GraphRAG, позволяющих эффективно интегрировать графы знаний в системы RAG:
- Графы знаний с семантической кластеризацией: Эта архитектура повышает релевантность и точность поиска данных за счет кластеризации релевантной информации перед генерацией ответов.
- Интеграция графов знаний с векторными базами данных: Эта архитектура объединяет две системы, чтобы обеспечить более богатый контекст для более крупной языковой модели, что приводит к генерации более полных и контекстуально подходящих ответов.
- Система вопросов и ответов, дополненная графом знаний: В этой архитектуре граф знаний добавляет фактическую информацию к ответам, сгенерированным большой языковой моделью после векторного поиска, чтобы обеспечить точность и полноту ответов.
- Гибридный поиск с использованием графов: Этот подход сочетает в себе векторный поиск, поиск по ключевым словам и графовые запросы, обеспечивая мощную и гибкую систему поиска, которая повышает способность больших языковых моделей генерировать релевантные ответы.
Новые модели для GraphRAG
По мере того как GraphRAG продолжает развиваться, начинают вырисовываться некоторые закономерности:
- Расширение запросов: Оптимизация и улучшение запросов с помощью графов знаний для обеспечения получения наиболее релевантной информации.
- Усиление ответа: Повысьте точность и полноту ответов, генерируемых Большой языковой моделью, добавив соответствующие факты.
- Контроль ответов: Используйте графы знаний для проверки точности генерируемого ИИ контента и снижения риска получения неверной или ложной информации.
Эти паттерны демонстрируют, как GraphRAG меняет подход к обработке сложных запросов и генерации ответов системами искусственного интеллекта.
Приложения GraphRAG
- Юридические исследования: Способность GraphRAG ориентироваться в сложной паутине законов, судебной практики и прецедентов предоставляет специалистам в области права мощный инструмент для поиска релевантной юридической информации и потенциальных связей.
- Здравоохранение: В здравоохранении GraphRAG помогает понять сложные взаимосвязи между медицинскими знаниями, историей болезни и вариантами лечения, что повышает точность диагностики и индивидуальность планирования лечения.
- Финансовый анализ: GraphRAG помогает анализировать сложные финансовые сети и зависимости, давая представление о тенденциях рынка, управлении рисками и инвестиционных стратегиях с помощью взаимосвязанных данных из графа знаний.
- Анализ социальных сетей: GraphRAG позволяет исследовать сложные социальные структуры и взаимодействия, помогая исследователям и аналитикам понять закономерности взаимоотношений и влияния в социальных сетях.
- Управление знаниями: GraphRAG расширяет корпоративную базу знаний, фиксируя и используя взаимосвязи и иерархии в организациях, улучшая процессы принятия решений и способствуя инновациям в бизнесе.
По мере развития искусственного интеллекта все более важным становится включение графов знаний в системы генерации дополнений к поисковым запросам. Графы знаний представляют собой мощную основу для организации и соединения данных, что позволяет создавать более точные, контекстуальные и легко интерпретируемые решения в области ИИ. Появление GraphRAG демонстрирует преимущества сочетания графов знаний с традиционными векторными методами, обеспечивая более комплексный и эффективный подход к поиску информации и генерации ответов.
Advanced RAG: Расширение горизонтов за счет усовершенствованной генерации с мультимодальным поиском
Достижения в области искусственного интеллекта сопровождаются прорывами, которые продолжают расширять границы машинного понимания и генерации. В то время как традиционные системы Retrieval Augmented Generation (RAG) были ориентированы в основном на текстовые данные, появление мультимодальных RAG знаменует собой важный технологический скачок. Эта инновационная технология позволяет ИИ обрабатывать и интегрировать различные формы данных - текст, изображения, аудио- и видеоматериалы - для создания насыщенных содержанием и контекстом результатов. Благодаря использованию мультимодальных данных эти передовые системы ИИ становятся более гибкими, чувствительными к контексту и способными обеспечить более глубокое понимание и более точные ответы. В этом разделе рассматриваются основные концепции, механизмы работы и потенциальные области применения мультимодального RAG, подчеркивается его важность для следующего поколения взаимодействия ИИ.
Понимание мультимодального RAG
Мультимодальный RAG - это усовершенствованное расширение классического фреймворка RAG, которое объединяет механизмы поиска и генеративного ИИ для нескольких типов данных. В то время как традиционные системы RAG получают информацию путем запроса к текстовым базам данных, мультимодальный RAG расширяет эту возможность, интегрируя текст, изображения, аудио и видео в процесс поиска и генерации. Такое расширение позволяет моделям ИИ использовать более широкий спектр исходных данных для получения более полных и глубоких результатов.
Как работает мультимодальный RAG?
Рабочий процесс мультимодального RAG заключается в кодировании различных типов данных в структурированный формат, обычно в виде векторов, чтобы модель искусственного интеллекта могла их обрабатывать. Эти векторы хранятся в общем пространстве встраивания, содержащем данные из разных модальностей. Когда делается запрос, модель извлекает соответствующую информацию из этих модальностей, обеспечивая тем самым более богатый и точный ответ. Например, для запроса об историческом событии система может получить текстовые описания, соответствующие изображения, аудиоклипы с комментариями экспертов и видеоматериалы, которые в совокупности формируют более подробный и информативный ответ.
Методы реализации мультимодальных RAG
Существует несколько подходов к реализации мультимодального RAG, каждый из которых имеет свои уникальные преимущества и проблемы:
- Единая мультимодальная модель:
В этом подходе используется единая модель, обученная кодировать различные типы данных - например, текст, изображения, аудио - в общее векторное пространство. Затем модель может легко извлекать и генерировать данные разных типов. Хотя такой подход упрощает процесс за счет использования единой модели, он требует сложного обучения для обеспечения точного кодирования и извлечения мультимодальных данных. - Базовый модал на основе текста:
При таком подходе нетекстовые данные перед кодированием и хранением преобразуются в текстовые описания. Этот подход использует преимущества современных текстовых моделей. Однако в процессе преобразования может происходить потеря информации, поскольку нюансы изображения или звука могут быть не полностью представлены в тексте. - Несколько кодирующих устройств:
Этот подход использует различные модели для кодирования различных типов данных, каждый из которых обрабатывается своей собственной специализированной моделью. Процесс поиска объединяет эти результаты. Хотя такой подход позволяет более специализированно кодировать и точнее извлекать данные, он повышает сложность системы и требует тщательного управления множеством моделей и их взаимодействием.
Архитектура мультимодальной системы RAG
Архитектура мультимодального RAG опирается на основы традиционных RAG, но при этом учитывает сложность работы с несколькими типами данных. Основная архитектура включает следующие ключевые компоненты:
- Модально-специфические датчики:
Каждая модальность данных, например текст, изображение или аудио, обрабатывается специализированным кодировщиком. Эти кодировщики преобразуют исходные данные в единое пространство встраивания, что позволяет сравнивать и извлекать данные всех модальностей стандартным образом. - Общее встроенное пространство:
Ключевым компонентом мультимодальной RAG является общее пространство встраивания, в котором хранятся закодированные векторы из разных модальностей. Это пространство позволяет проводить кросс-модальные сравнения и поиск, позволяя модели распознавать релевантную информацию в различных типах данных. - Ретривер:
Компонент Retriever отвечает за запрос к общему пространству встраивания для поиска наиболее релевантных точек данных в разных модальностях. Он может извлекать информацию на основе различных критериев, таких как релевантность входному запросу или сходство с другими точками данных в пространстве. - Генератор:
После получения необходимой информации компонент генератора интегрирует эти данные в ответ модели ИИ. Как правило, генератор представляет собой сложную языковую модель, способную объединить информацию из нескольких модальностей в последовательный и контекстуально точный ответ. - Механизмы интеграции:
Механизм слияния отвечает за объединение полученных мультимодальных данных в единое представление для использования генератором. Этот процесс может включать в себя выбор наиболее релевантных модальностей или синтез информации из разных источников для создания комплексного ответа.
Существует несколько ключевых стратегий, которые необходимо использовать для управления информацией различных модальностей в системе RAG:
- Равномерно вписаны в пространство:
Кодирование всех типов данных в общее пространство встраивания позволяет системе эффективно выполнять кросс-модальные поисковые операции. В то же время это пространство встраивания обеспечивает основу для интеграции и согласования данных из разных источников. - Механизмы кросс-модального внимания:
Использование механизма кросс-модального внимания гарантирует, что модель сможет сосредоточиться на наиболее релевантной информации в полученных данных, независимо от того, из какой модальности они получены. Это помогает сбалансировать важность каждого типа данных в окончательном ответе. - Постобработка с учетом особенностей модальности:
После завершения поиска может потребоваться специальная постобработка данных для каждой модальности, например, изменение размера изображений или нормализация звука, чтобы обеспечить оптимальную интеграцию и генерацию данных.
Мультимодальный RAG в чатботах
Мультимодальные RAG значительно расширяют возможности чат-ботов, позволяя им предоставлять более богатый и контекстуальный интерактивный опыт. Традиционные чат-боты полагаются в основном на текст, что ограничивает их способность реагировать на информацию, связанную со зрением или звуком. Мультимодальные RAG позволяют чат-ботам получать и интегрировать информацию из изображений, видео- и аудиоклипов, обеспечивая более полный и интересный пользовательский опыт.
Например, с помощью мультимодального RAG's Чатбот для поддержки клиентов В ответ на запрос пользователя могут быть показаны обучающие видеоролики, изображения продуктов или аудиогиды, что позволяет получить более интерактивную и практичную помощь. Это особенно важно в таких сферах, как розничная торговля, здравоохранение и образование, где общение часто должно быть подкреплено несколькими формами информации.
Расширение мультимодальных приложений RAG
Внедрение мультимодальной функциональности открывает новые возможности в самых разных отраслях:
- Здравоохранение:
Мультимодальные RAG могут объединять текстовые медицинские записи, радиологические изображения, результаты лабораторных исследований и аудиоописания пациентов для повышения точности и полноты диагностических систем. - Финансы:
В сфере финансовых услуг мультимодальный RAG способен обрабатывать и анализировать сложные документы, содержащие таблицы, графики и пояснительный текст, чтобы улучшить процесс принятия решений. - Образование:
Образовательные платформы могут использовать мультимодальный RAG для объединения текста, видеолекций, иллюстраций и интерактивных симуляторов в целостную учебную историю, обеспечивая более богатый опыт обучения.
Мультимодальный RAG - это важное технологическое достижение, которое способно изменить способ взаимодействия систем искусственного интеллекта с пользователями и реагирования на них. Благодаря включению нескольких типов данных в процесс поиска и генерации информации мультимодальные системы RAG способны предоставлять более богатые, точные и контекстуальные результаты, открывая новые возможности в различных отраслях. Ожидается, что по мере развития технологии ее применение будет расширяться, чтобы еще больше повысить способность ИИ обрабатывать сложную мультимодальную информацию.
Чем координационная платформа GenAI компании LeewayHertz, ZBrain, выделяется среди передовых систем RAG.
Вам интересно узнать о расширенном RAG, мультимодальном RAG и графах знаний? Представьте, что эти мощные функции объединены в единую платформу, которая позволяет легко создавать передовые приложения для искусственного интеллекта. Это и есть ZBrain.
ZBrainРазработанная компанией LeewayHertz, ZBrain - это комплексная платформа оркестрации, призванная упростить и ускорить разработку и масштабирование решений корпоративного уровня в области искусственного интеллекта. Благодаря удобной среде с низким уровнем кодирования ZBrain позволяет организациям быстро создавать, развертывать и масштабировать специализированные приложения генеративного ИИ (GenAI) с минимальными усилиями по кодированию. Платформа революционизирует процесс разработки корпоративного ИИ, позволяя организациям использовать собственные данные для создания высокоточных приложений ИИ. Являясь центральным центром управления, ZBrain легко интегрируется с существующими технологическими стеками для повышения эффективности разработки приложений GenAI. Приложения, созданные на базе ZBrain, отлично справляются с задачами обработки естественного языка (NLP), такими как создание отчетов, перевод, анализ данных, классификация и обобщение текстов. Используя частные и контекстные данные, ZBrain обеспечивает высокую релевантность и персонализацию ответов для удовлетворения конкретных потребностей бизнеса.
Как взаимодействовать с передовыми системами Retrieval Augmentation Generation (RAG)
- Интеграция различных источников данных: ZBrain интегрирует различные источники данных, включая частные, публичные и потоки в режиме реального времени, во всех форматах данных (структурированных, полуструктурированных и неструктурированных), чтобы повысить точность и релевантность ответов ИИ.
- Оптимизация на уровне блоков: Платформа обеспечивает получение точных и специализированных результатов, разбивая информацию на управляемые фрагменты и применяя наиболее эффективные стратегии поиска.
- Автоматическое обнаружение стратегий поиска: Передовые алгоритмы ZBrain автоматически определяют и применяют оптимальные стратегии поиска, сокращая количество ручных действий на основе данных и контекста и повышая точность извлечения данных.
- Защитные меры и борьба с галлюцинациями: ZBrain оснащен системами защиты и фантомного контроля для предотвращения генерации неточной или вводящей в заблуждение информации, что обеспечивает высокую точность и надежность.
мультимодальные возможности
- Работает с несколькими форматами данных. ZBrain отлично справляется с различными форматами данных, такими как текст, изображения, видео и аудио, предоставляя исчерпывающий и подробный ответ.
- Интеграция и анализ различных типов данных. Платформа способна интегрировать и анализировать различные типы данных для получения более глубоких выводов и релевантных ответов.
- Улучшенная обработка запросов. ZBrain эффективно управляет и извлекает информацию из различных модальностей данных, повышая точность и углубляя понимание сложных проблем.
карта знаний
- Структурированная структура данных. ZBrain организует данные в структурированную сеть, которая повышает точность поиска и обеспечивает более глубокое понимание благодаря соединению связанных понятий.
- Более глубокое понимание данных. Взаимосвязанная природа Knowledge Graph позволяет ZBrain предоставлять ответы с учетом нюансов и контекста, которые приводят к более богатым и содержательным выводам.
- Расширенные возможности данных. ZBrain поддерживает расширение данных на уровне блоков или файлов, обновление метаинформации и создание онтологий для улучшения представления, организации и поиска данных.
Преимущества использования ZBrain для разработки корпоративных ИИ-решений
ZBrain предлагает множество преимуществ для разработки корпоративных ИИ-решений, в том числе:
- масштабируемость
ZBrain позволяет легко масштабировать решения ИИ для работы с растущими объемами данных и сценариями использования без ущерба для производительности. - Эффективная интеграция
Платформа легко интегрируется с существующими технологическими стеками, сокращая время и затраты на развертывание и ускоряя внедрение ИИ. - персонализация
ZBrain поддерживает разработку высокоиндивидуальных приложений искусственного интеллекта, которые отвечают конкретным потребностям бизнеса и соответствуют организационным целям. - Эффективность использования ресурсов
Его низкокодовый характер снижает потребность в большом количестве разработчиков и подходит для организаций с небольшими техническими командами. - Комплексные решения
От разработки до развертывания ZBrain охватывает весь жизненный цикл приложений искусственного интеллекта, что делает его комплексным решением. - Нейтральное облачное развертывание
ZBrain нейтрален к облакам, что позволяет развертывать приложения на различных облачных платформах, обеспечивая гибкость для адаптации к различным организационным потребностям и предпочтениям инфраструктуры.
Передовая система RAG, мультимодальная поддержка и надежная интеграция графа знаний делают ZBrain мощной платформой, обеспечивающей повышенную точность, эффективность и проницательность в широком спектре приложений.
сноска
Достижения в области поисково-усовершенствованной генерации (RAG) значительно расширили ее возможности, что позволило преодолеть прежние ограничения и открыть новый потенциал в области поиска и генерации информации с помощью ИИ. Благодаря использованию сложных механизмов поиска, усовершенствованная RAG может получить доступ к большим объемам данных, чтобы гарантировать точность и контекстную релевантность генерируемых ответов. Это открывает путь к созданию более динамичных и интерактивных приложений ИИ, делая RAG важным инструментом в таких областях, как обслуживание клиентов, исследования, управление знаниями и создание контента. Применение этих передовых технологий RAG дает организациям возможность повысить качество обслуживания пользователей, оптимизировать процессы и решать сложные задачи с большей точностью и эффективностью.
Появление Multimodal RAG и Knowledge Graph RAG еще больше расширяет возможности этого фреймворка, способствуя его широкому внедрению в различных отраслях. Multimodal RAG объединяет текстовые, визуальные и другие формы данных, позволяя Large Language Model (LLM) генерировать более полные и учитывающие контекст ответы, тем самым улучшая пользовательский опыт и предоставляя более богатую и нюансированную информацию. А Knowledge Graph RAG использует взаимосвязанные структуры данных для получения и генерации семантически насыщенного контента, что значительно повышает точность и глубину информации. Эти достижения в технологии RAG предвещают новую волну инноваций в области ИИ, обеспечивая более интеллектуальные и гибкие решения сложных задач поиска информации.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...