
Бесплатные PDF-файлы по основам больших моделей из Чжэцзянского университета - с ссылкой на скачивание

Книга "Основы больших моделей" содержит глубокий анализ основных технологий и практических путей создания больших языковых моделей (LLM). Начиная с основ теории моделирования языка, он систематически объясняет принципы построения моделей на основе статистических, рекуррентных нейронных сетей (RNN) и архитектур трансформеров, уделяя особое внимание трем основным архитектурам больших языковых моделей (только кодер, кодер-декодер, только декодер) и репрезентативным моделям (например, BERT, T5, GPT). В книге описаны такие ключевые технологии, как проектирование Prompt, эффективная тонкая настройка параметров, редактирование модели и генерация улучшений поиска. В сочетании с богатыми примерами книга демонстрирует практику применения в различных сценариях, предоставляя читателям всестороннее и глубокое обучение и практическое руководство, помогая им освоить применение и оптимизацию технологий моделирования больших языков.

Основы языкового моделирования
- Моделирование языка на основе статистических методов: Глубокий анализ моделей n-грамм и статистики, лежащей в их основе, включая предположения Маркова и оценку большого правдоподобия.
- Моделирование языка на основе RNN: Подробное объяснение структурных особенностей рекуррентных нейронных сетей (РНС), распространенных проблем исчезновения и взрыва градиента при обучении, а также практических применений в моделировании языка.
- Моделирование языка на основе трансформаторов: Всесторонний анализ основных компонентов архитектуры Transformer, таких как механизм самовнимания, нейронные сети с прямой передачей (FFN), нормализация слоев и остаточная связность, и их эффективное применение в моделировании языка.
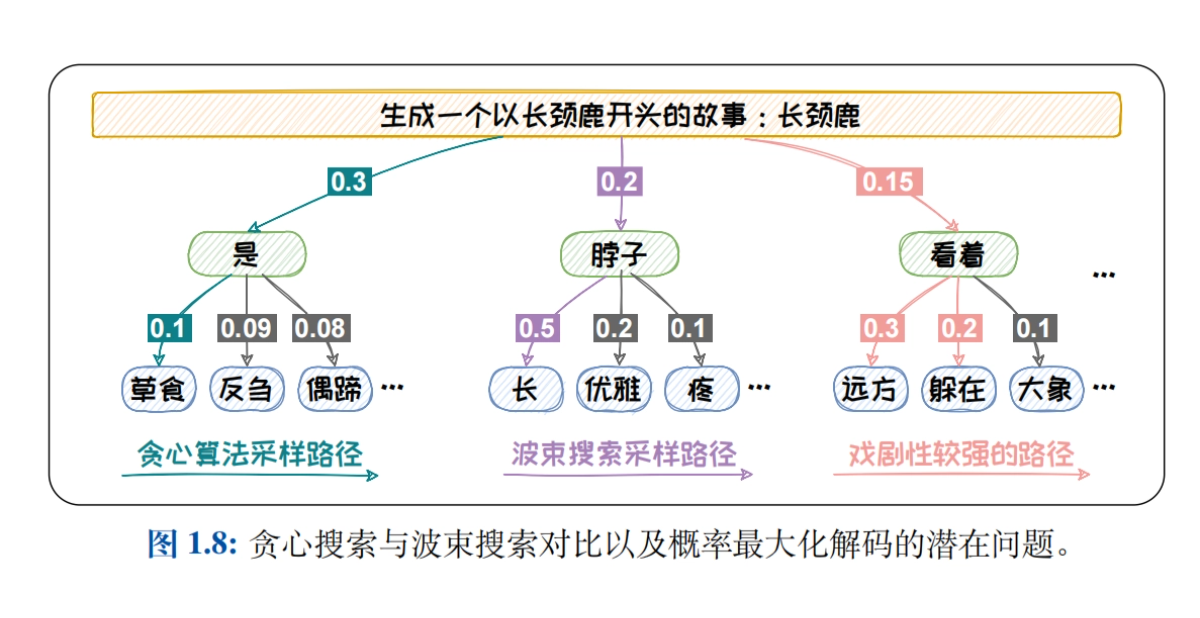
- Методы выборки для моделирования языкаСистематически представлены такие стратегии декодирования, как Greedy Search, Beam Search, Top-K Sampling, Top-P Sampling и Temperature mechanism, чтобы исследовать влияние различных стратегий на качество генерируемого текста.
- Обзор языковых моделей: Представлены подробные описания внутренних (например, perplexity) и внешних (например, BLEU, ROUGE, BERTScore, G-EVAL) рубрик для анализа сильных сторон и ограничений каждой рубрики при оценке эффективности языковых моделей.
Архитектура модели большого языка
- Большие данные + большие модели → Новый интеллектНиже приводится подробный анализ влияния размера модели и размера данных на возможности модели, детальное объяснение законов масштабирования (таких как закон Каплана-Маккандлиша и закон Чинчилла), а также обсуждение того, как улучшить производительность модели путем оптимизации размера модели и данных.
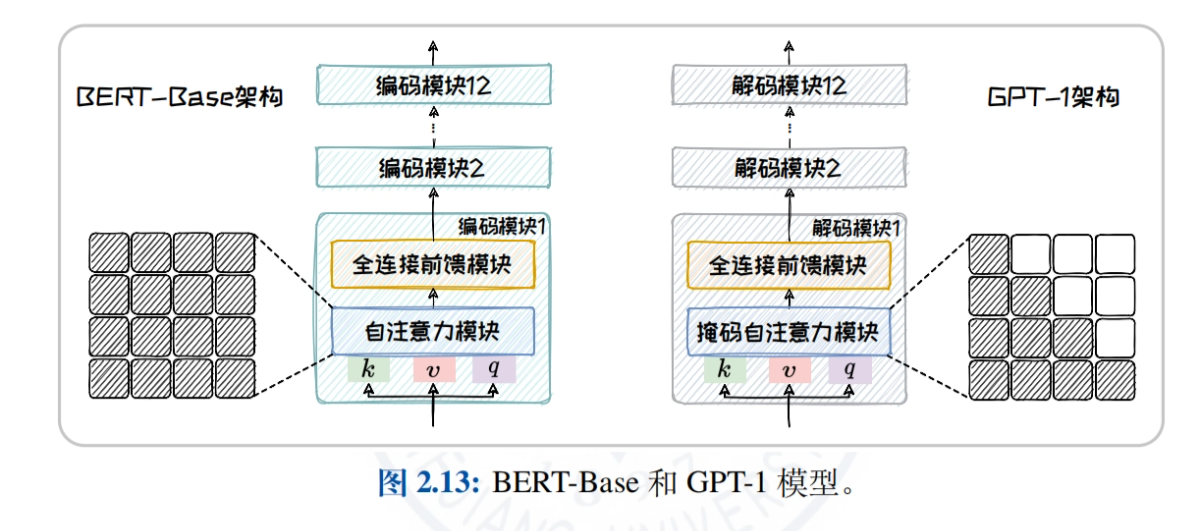
- Обзор архитектуры модели большого языка: Сравните и проанализируйте механизмы внимания и применимые задачи трех основных архитектур - только кодирующей, кодирующей-декодирующей и только декодирующей - чтобы помочь читателям понять особенности и преимущества различных архитектур.
- Архитектура только для кодирования: На примере BERT мы подробно объясняем структуру модели, задачи предварительного обучения (например, MLM, NSP) и производные модели (например, RoBERTa, ALBERT, ELECTRA), чтобы изучить применение модели в задачах понимания естественного языка.
- Архитектура кодера-декодераМодели T5 и BART используются в качестве примеров для представления единой структуры генерации текстов и различных задач предварительного обучения, а также для анализа производительности моделей в таких задачах, как машинный перевод и резюмирование текста.
- Архитектура только для декодера: Подробно описывается история развития и характеристики семейства GPT (от GPT-1 до GPT-4) и семейства LLaMA (LLaMA1/2/3), исследуются преимущества моделей для задач генерации текстов в открытом пространстве.
- Нетрансформаторная архитектура: Представление моделей пространства состояний (SSM), таких как RWKV, Mamba, и парадигмы обучения и тестирования (TTT), изучение потенциала неосновных архитектур для применения в конкретных сценариях.
Prompt Engineering
- Введение в проект Prompt: Дайте определение Prompt и Prompt Engineering, подробно объясните процесс деамбигуации и векторизации (Tokenization, Embedding), а также изучите, как генерировать высококачественный текст с помощью хорошо разработанной загрузочной модели Prompt.
- Контекстное обучение (ICL): Вводятся понятия обучения на нулевой выборке, на одной выборке и на нескольких выборках, изучаются стратегии выбора примеров (например, сходство и разнообразие) и анализируется, как контекстное обучение может быть использовано для улучшения адаптивности моделей к задачам.
- Цепь мыслей (CoT): Объясните три режима CoT: пошаговый (например, CoT, Zero-Shot CoT, Auto-CoT), мыслительный (например, ToT, GoT) и мозговой штурм (например, Self-Consistency), а также изучите, как улучшить обоснование моделей с помощью цепочки мыслей.
- ПодсказкиВ ней представлены такие техники, как стандартизация написания Prompt, рациональное обобщение вопросов, использование CoTs в нужное время и правильное использование психологических подсказок (например, ролевая игра, ситуативное замещение), которые помогут читателям улучшить дизайн Prompt.
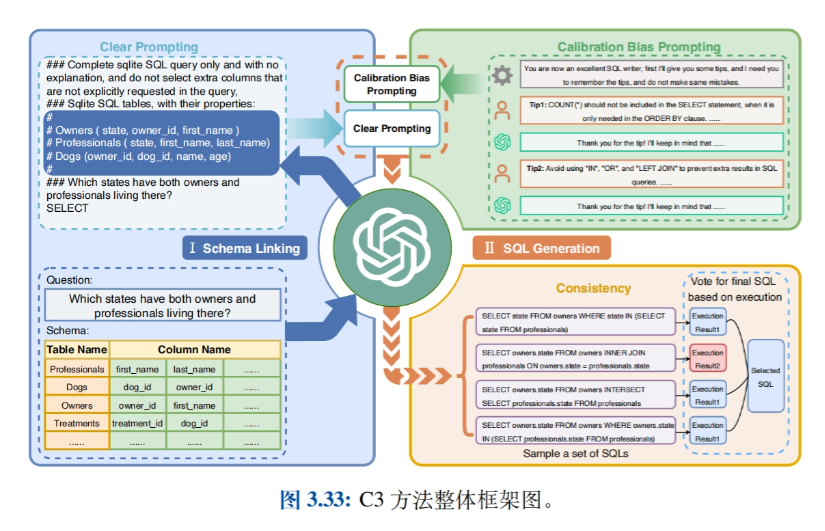
- Связанные приложения: Знакомство с такими приложениями, как Big Model-based Intelligentsia (Agents), Data Synthesis, Text-to-SQL, GPTS и т.д., а также изучение практических примеров использования Prompt Engineering в различных областях.
Эффективная тонкая настройка параметров
- Введение в эффективную тонкую настройку параметров: Представление двух доминирующих подходов к адаптации задач на нижнем уровне - контекстного обучения и точной настройки инструкций - приводит к созданию техники Parameter Efficient Fine-Tuning (PEFT), подробно описывающей значительные преимущества с точки зрения снижения затрат и эффективности.
- Методы присоединения параметров: Подробное описание методов эффективной тонкой настройки путем присоединения новых, более мелких обучаемых модулей к структуре модели, включая реализацию и преимущества добавляемых входов (например, Prompt-tuning), добавляемых моделей (например, Prefix-tuning и Adapter-tuning) и добавляемых выходов (например, Proxy-tuning).
- Метод выбора параметров: Представляем методы тонкой настройки только части параметров модели, которые делятся на методы, основанные на правилах (например, BitFit), и методы, основанные на обучении (например, Child-tuning), исследуя, как уменьшить вычислительную нагрузку и улучшить производительность модели за счет выборочного обновления параметров.
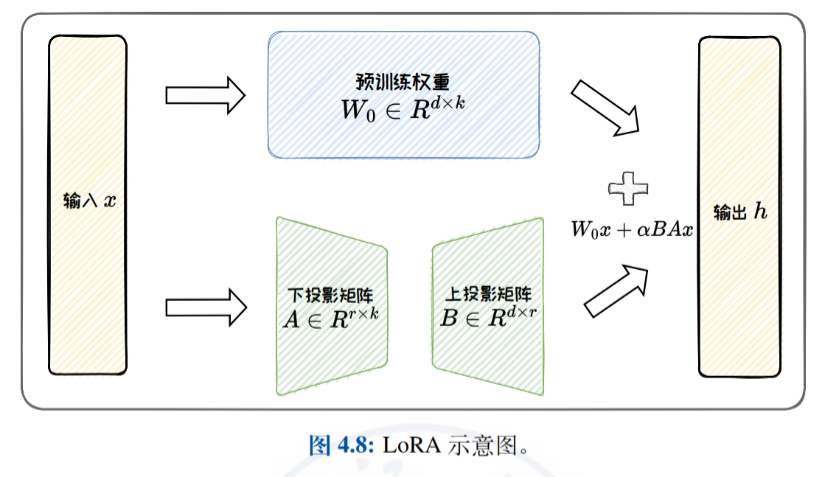
- Методы адаптации с низким рангом: Подробное введение в эффективную тонкую настройку путем аппроксимации исходной матрицы обновления весов матрицей с низким рангом, с акцентом на LoRA и ее вариантах (например, ReLoRA, AdaLoRA и DoRA), а также обсуждение параметрической эффективности LoRA и возможностей обобщения задач.
- Практика и применение: Представляет использование фреймворка HF-PEFT и связанных с ним методов, демонстрирует примеры использования методов PEFT в запросах к табличным данным и анализе табличных данных, а также доказывает эффективность PEFT в улучшении производительности больших задач, специфичных для модели.
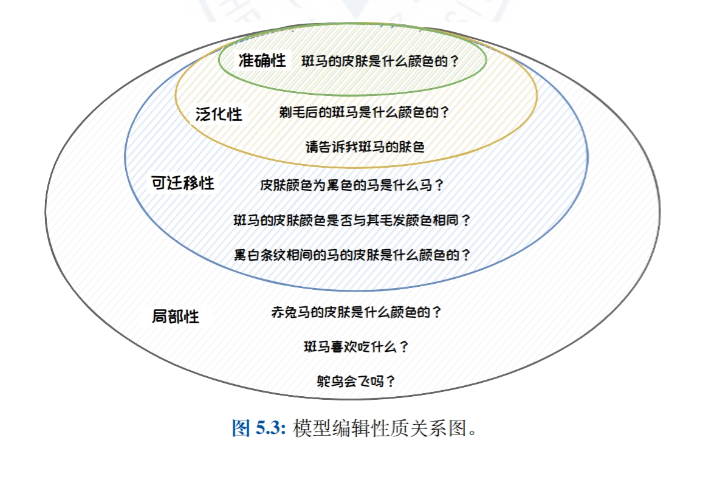
Редактирование модели
- Введение в редактирование моделей: Введение в идею, определение и природу редактирования моделей, подробное описание важности редактирования моделей для исправления ошибок смещения, токсичности и знаний в больших языковых моделях.
- Классический подход к редактированию моделей: Классифицировать методы редактирования моделей на методы внешнего расширения (например, методы кэширования знаний и дополнительных параметров) и методы внутренней модификации (например, методы метаобучения и позиционного редактирования), представив репрезентативные работы по каждому типу методов.
- Метод дополнительных параметров: T-Patcher: Подробно описывается метод T-Patcher, который позволяет точно контролировать выход модели путем присоединения к ней определенных параметров и подходит для сценариев, требующих быстрой и точной коррекции определенных точек знания в модели.
- Метод редактирования местоположения: РИМ: Подробное введение в метод ROME, который обеспечивает точный контроль над выходом модели путем нахождения и изменения определенных слоев или нейронов в модели, для сценариев, требующих глубокой модификации внутренней структуры знаний модели.
- Приложения для редактирования моделей: Представляет практическое применение редактирования моделей для точного обновления моделей, защиты права быть забытым и повышения безопасности моделей, а также демонстрирует потенциал применения технологии редактирования моделей в различных сценариях.
Поиск Расширенный генерация
- Профиль генерации улучшенного поиска: Представляет предпосылки и состав генерации с усилением поиска, подробно описывает важность и сценарии применения улучшения производительности модели за счет сочетания поиска и генерации в задачах обработки естественного языка.
- Извлечение улучшенной архитектуры генерации: Представляет классификацию архитектур RAG, архитектуры усовершенствования "черного ящика" и архитектуры усовершенствования "белого ящика", сравнивает и анализирует характеристики и применимые сценарии различных архитектур, а также помогает читателям выбрать подходящую архитектуру.
- поиск знаний: Подробное введение в построение базы знаний, расширение запросов, поиск и повышение эффективности поиска, изучение того, как повысить эффективность поиска и оптимизировать процесс поиска знаний путем реорганизации результатов поиска.
- Усиление генерации: Представляет, когда нужно улучшать, где нужно улучшать, несколько улучшений и методы снижения затрат, обсуждает стратегии применения генеративного улучшения для различных задач, а также повышает качество и эффективность созданного текста.
- Практика и применение: Представляет шаги по созданию простой системы RAG, показывает примеры использования RAG в типичных приложениях и помогает читателям понять и применить методы генерации с расширением поиска для улучшения производительности своих моделей в реальных задачах.
Адрес для скачивания справочных материалов
Отчет "Основы крупного моделирования" доступен для скачивания на сайте: https://url23.ctfile.com/f/65258023-8434020435-605e6e?p=8894 (код доступа: 8894).
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...