
Новые модели серии PP от Flying Paddles! Новая "пчела" для понимания изображений документов PP-DocBee!

Технология понимания изображений документов направлена на то, чтобы дать возможность компьютерам понимать содержание изображений документов так же хорошо, как это делает человек. В основном она включает в себя анализ, обработку и понимание изображений документов (например, бумажных договоров, страниц книг, счетов-фактур и т. д.), полученных путем сканирования или фотографирования, извлечение из них ценной информации, такой как текст, таблицы, диаграммы и т. д., и структурирование этой информации. На волне современной цифровой трансформации технология понимания изображений документов широко используется в бизнесе, научных кругах и повседневной жизни для повышения эффективности и точности обработки документов.
Ранее, в сочетании с Wenxin Big Model, FeiPaddle выпустила решение PP-ChatOCRv3 для слияния размерных моделей, которое сначала использует технологию OCR для извлечения текста из изображения, а затем вводит его в Wenxin Big Model для анализа викторины, что в конечном итоге значительно повышает эффективность разбора текста и изображения и извлечения информации. Схема очень точна при работе с текстом и таблицами, но способность понимать изображения и графики в документах нуждается в дальнейшем улучшении. Поэтому, чтобы лучше удовлетворить потребности пользователей в сложных и разнообразных задачах понимания изображений в документах, мы предлагаем новую схему PP-DocBee, которая основана на мультимодальной большой модели для достижения сквозного понимания изображений в документах. Она может эффективно применяться во всех видах сценариев, таких как понимание документов, вопросы и ответы и т. д. Особенно в сценариях понимания китайских документов, таких как финансовые отчеты, законы и правила, диссертации, руководства, контракты, исследовательские отчеты и т. д., ее эффективность очень высока.
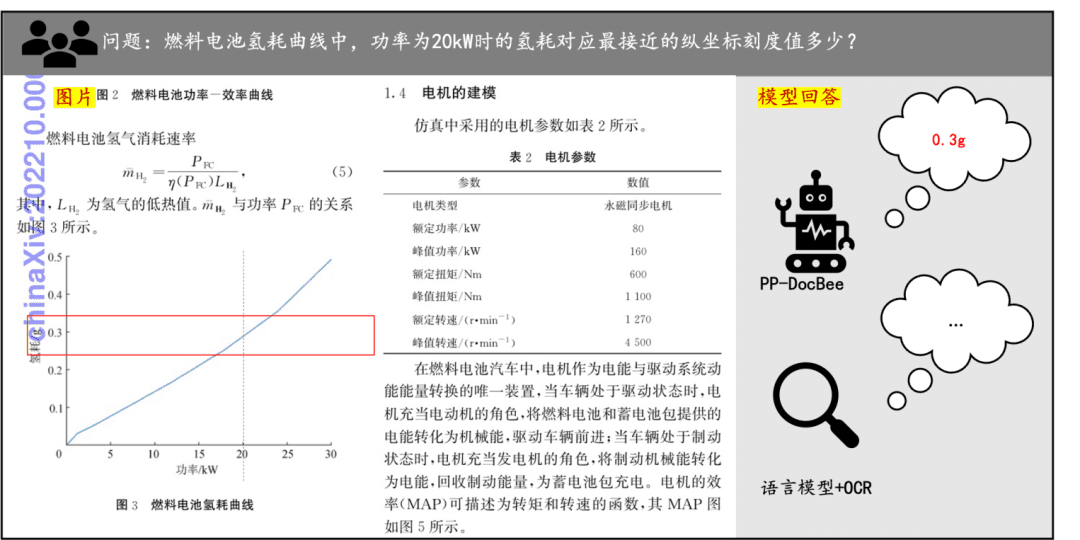
Пример понимания документов Небольшой обзор влияния PP-DocBee на понимание печатного текста, таблиц, графиков и других документов:
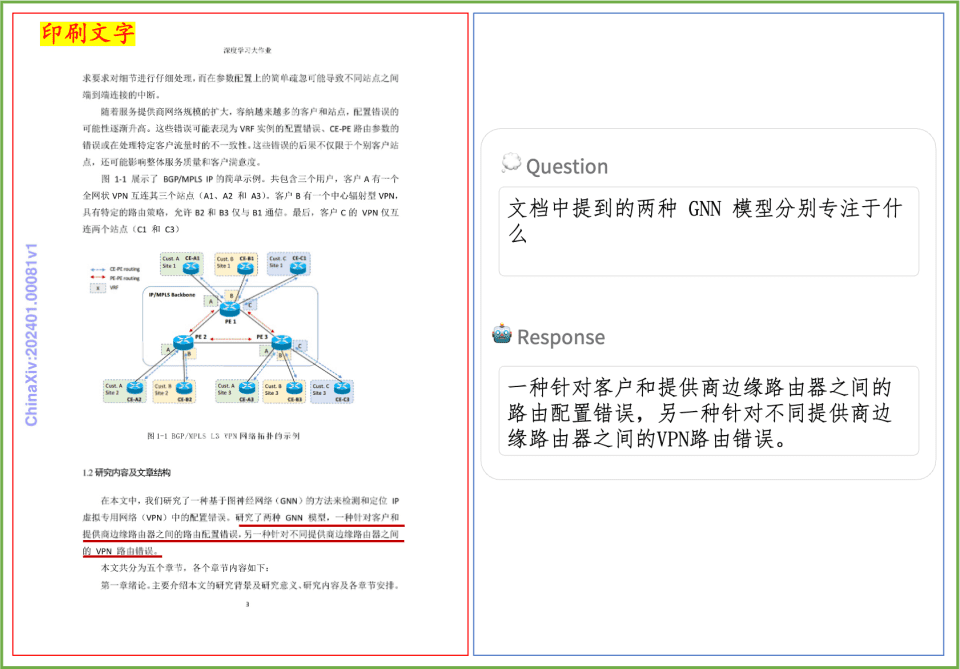

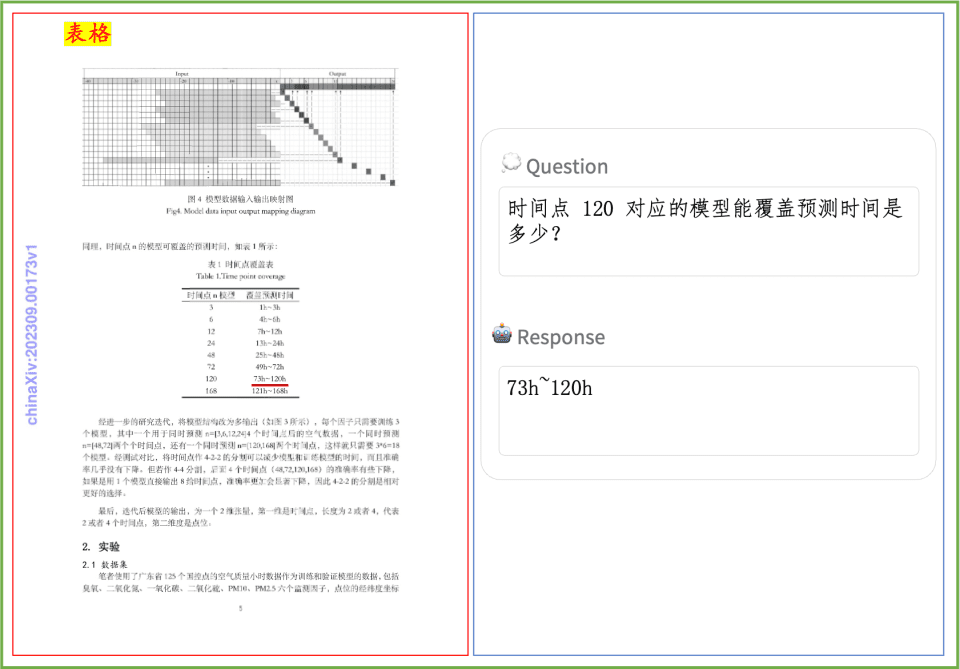
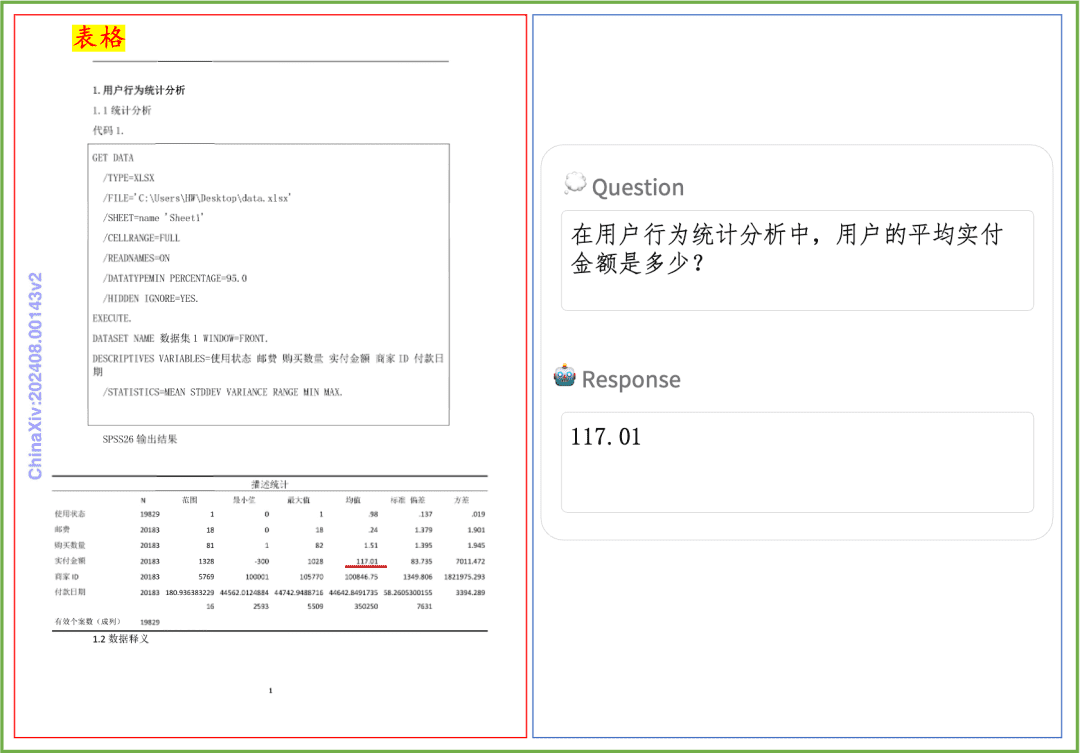

PP-DocBee в основном добился SOTA для моделей с одинаковым уровнем объема параметров в нескольких авторитетных списках рецензий на понимание английских документов в академических кругах.
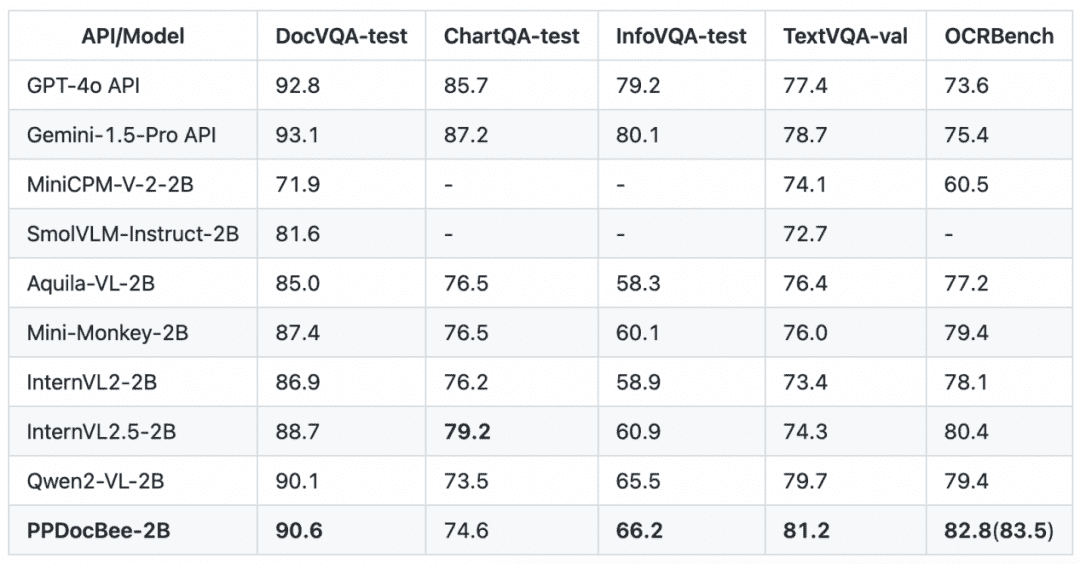
English Document Comprehension Review List Сравнение конкурентов
Примечание: метрики OCRBench нормированы к 100-балльной шкале, и метрики OCRBench PPDocBee-2B имеют 82,8 балла для сквозной оценки и 83,5 балла для оценки с помощью постобработки OCR. PP-DocBee также превосходит популярные в настоящее время модели с открытым и закрытым исходным кодом в категории метрик для внутренних китайских сценариев.
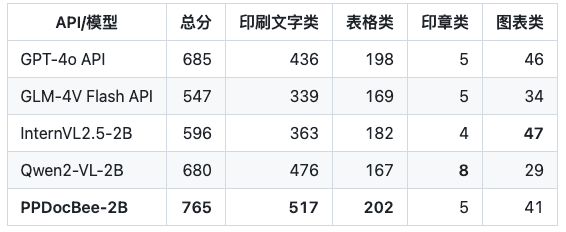
Бизнес китайского сценария Сравнение конкурентов
Примечание: Набор сценариев оценки китайского языка для внутреннего бизнеса включает в себя сценарии финансовых отчетов, законов и правил, научно-технических работ, руководств, гуманитарных работ, договоров, исследовательских работ и т.д., которые делятся на 4 основные категории: печатный текст, формы, печати и диаграммы.
Для дальнейшего улучшения производительности PP-DocBee мы добиваемся сокращения времени вывода на 51,51 TP3T и общего времени на 41,91 TP3T за счет оптимизации слияния операторов, как показано в следующей таблице.
| PP-DocBee | Среднее время прохождения маршрута (с) | Среднее время предварительной обработки (с) | Среднее время, затраченное на рассуждения (с) |
| версия по умолчанию | 1.60 | 0.29 | 1.30 |
| Высокопроизводительное издание | 0.93 | 0.29 | 0.63 |
Примечание: Высокопроизводительная версия имеет практически такое же количество выходных лексем, как и версия по умолчанию с таким же количеством входных лексем. Благодаря высокопроизводительной оптимизации с помощью летающего весла PP-DocBee отвечает быстрее, сохраняя при этом качество ответов. Подробную информацию об этой высокопроизводительной версии можно найти по адресу: https://github.com/PaddlePaddle/PaddleMIX/tree/develop/deploy/ppdocbee.
Мы также предоставляем онлайн-среду для сообщества Flying Paddle Star River, где вы можете быстро ознакомиться с возможностями PP-DocBee через Центр приложений сообщества Flying Paddle Star River (https://aistudio.baidu.com/application/detail/60135).
Кроме того, мы также обеспечиваем локальное развертывание gradio, развертывание сервиса OpenAI, а также подробные инструкции, пользователи и энтузиасты могут посетить домашнюю страницу проекта: https://github.com/PaddlePaddle/PaddleMIX/tree/develop/paddlemix/. examples/ppdocbee
Введение в программу PP-DocBee
Структура модели PP-DocBee показана на следующем рисунке, в ней используется архитектура ViT+MLP+LLM. Идеи оптимизации для сценариев понимания документов включаютСтратегии синтеза данных, предварительная обработка данных, методы обучения и помощь в постобработке OCRВ итоге модель способна как на общее понимание документов, так и на сильный синтаксический разбор документов в китайских сценариях.

Структура модели PP-DocBee
В частности, PP-DocBee включает следующие основные усовершенствования:
1. стратегия синтеза данных
Чтобы решить проблемы недостаточной способности китайского языка и нехватки данных о сцене, мы разработали интеллектуальное решение для производства данных о типах документов, создали различные связи для генерации данных для каждого из трех основных типов наборов данных, таких как Doc, Table, Chart и т. д., и приняли многочисленные стратегии: сочетание малой модели OCR и большой модели LLM, производство данных об изображениях на основе механизма рендеринга, индивидуальное производство данных для каждого типа документа. шаблоны подсказок и т. д., что привело к повышению качества вопросов и ответов и контролируемой стоимости генерации. Подробности показаны на рисунке ниже:
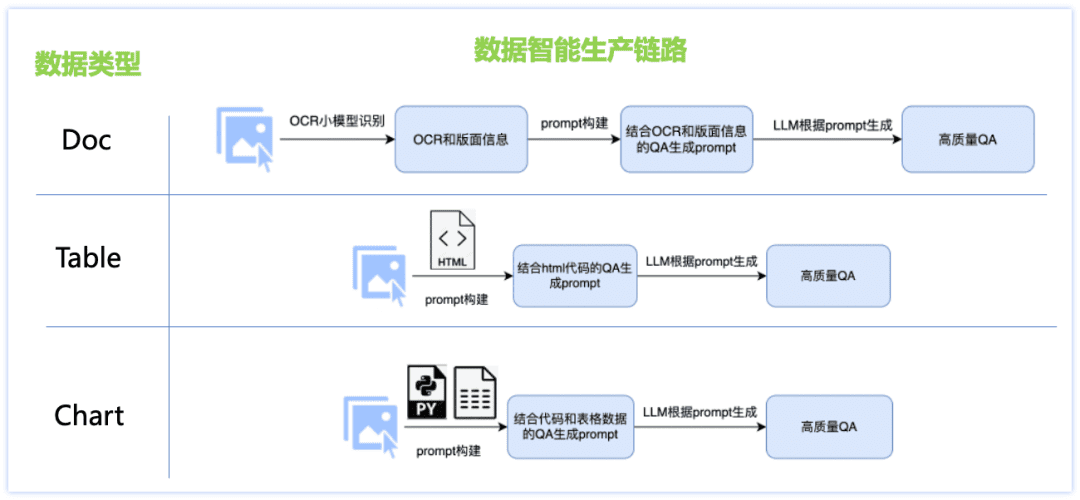
Данные класса Doc:
Picture: собирайте и упорядочивайте документы, финансовые отчеты, исследовательские работы и другие pdf-файлы, а также используйте инструменты анализа pdf для получения массивных изображений одностраничных документов;
Q&A: Малая модель ocr извлекает подробную информацию о расположении изображений, компенсируя тем самым недостатки визуального восприятия большой модели, и в то же время использует мощную способность большой языковой модели к пониманию текста для исправления неточностей распознавания отдельных символов малой модели ocr, а их сочетание позволяет получить более качественный и контролируемый Q&A.
Данные класса таблицы:
Изображение: на основе изображения таблицы, содержащего текстовую информацию html, измените значение, тему и другую информацию в тексте с помощью большой языковой модели и получите богатое содержанием высококачественное изображение таблицы с помощью инструмента рендеринга таблицы.
Вопросы и ответы: текст в формате html, соответствующий изображению таблицы, используется в качестве вспомогательной информации GT для обеспечения точности ответов, а разработка тонко настроенных подсказок позволяет создавать высококачественные вопросы и ответы с помощью большой языковой модели.
Данные класса диаграмм:
Изображение: на основе проверенных толпой высококачественных исходных данных графика (изображение-код-таблица) произвольно измените значения графика, оси, легенды, темы и другую тонкую информацию в коде с помощью большой языковой модели, получите исходный код с разнообразным содержанием, а затем отрендерите его с помощью инструмента рендеринга графика (Matplotlib, Seaborn, Vega-Liteи т.д.) для получения высококачественных графических изображений;
Вопросы и ответы: код, соответствующий изображению диаграммы и данным таблицы, используется в качестве вспомогательной информации GT для обеспечения точности ответа, соответствующие типы вопросов разработаны для различных типов диаграмм, а тонко настроенная подсказка предназначена для создания высококачественных вопросов и ответов с помощью большой языковой модели. Благодаря вышеописанной схеме интеллектуального производства данных о типах документов мы получаем огромное количество синтетических данных и фильтруем некоторые из них в качестве одних из обучающих данных PP-DocBee (распределение данных показано на рисунке ниже), что эффективно улучшает возможности модели.
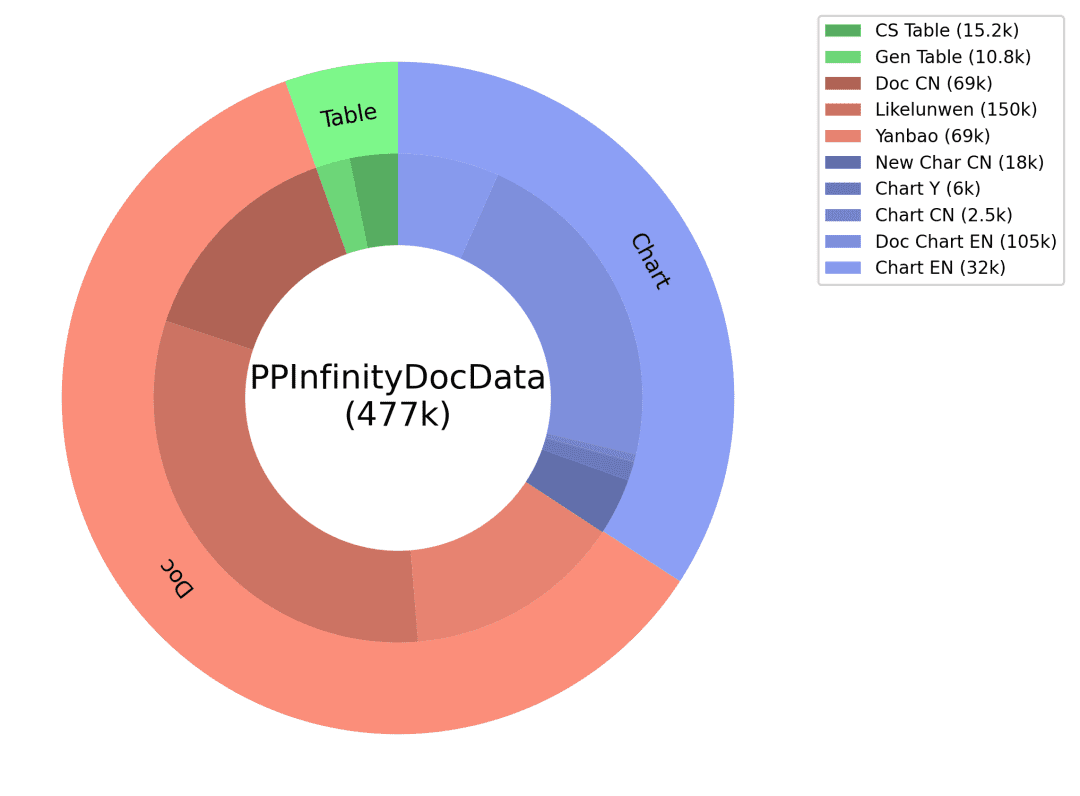
Синтетическое распределение данных
2. предварительная обработка данных
Применяются две стратегии: первая - установить больший порог изменения размера во время обучения, чтобы увеличить общее распределение разрешения набора данных, а вторая - установить равное увеличение в 1,1-1,3 раза для большинства обычных изображений во время вывода, сохраняя первоначальную стратегию предварительной обработки данных неизменной для изображений с малым разрешением. Эти две стратегии позволили получить более адекватные и полные визуальные характеристики, что улучшило итоговое понимание.
3. методы обучения
В основном это смесь различных классов данных для понимания документов, а также механизм сопоставления данных. Различные наборы данных включают в себя общий класс VQA, класс OCR, класс диаграмм, класс документов с большим количеством текста, класс математических и сложных рассуждений, класс синтетических данных, данные обычного текста и т. д. Механизм сопоставления данных заключается в установке коэффициентов выборки для данных из разных источников в разных классах и межклассовой выборке, чтобы увеличить вес выборки данных с большими достижениями в нескольких классах, а также сбалансировать количественные различия между различными типами наборов данных.
4.Помощь в постобработке OCR
В основном через OCR инструмент или модель заранее, чтобы получить OCR распознавания текста результаты, а затем в качестве вспомогательного априорной информации, предоставленной в картине викторины вопросы, а затем дать PP-DocBee модель рассуждения, может быть в тексте не так много и ясно картина имеет некоторое влияние на улучшение.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...