Evo2: биоинструмент с открытым исходным кодом для поддержки моделирования и проектирования генома

Общее введение
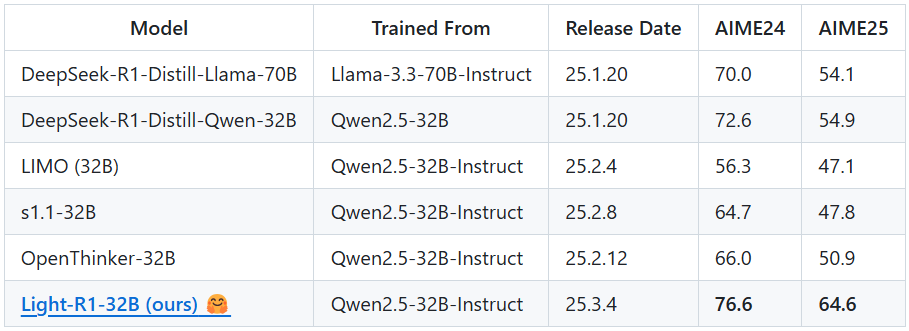
Arc Institute Evo 2 - это проект с открытым исходным кодом для моделирования и проектирования генома, разработанный Arc Institute, некоммерческой исследовательской организацией, расположенной в Пало-Альто, Калифорния, США, и запущенный в сотрудничестве с такими партнерами, как NVIDIA. Проект создает биологически обоснованные модели, способные работать с ДНК, РНК и белками с помощью передовых методов глубокого обучения для решения прогностических и генеративных задач в науках о жизни. evo 2 обучается на разнообразных геномных данных объемом более 9 триллионов нуклеотидов, имеет до 40 миллиардов параметров и поддерживает контекст длиной до 1 миллиона оснований. Код, обучающие данные и весовые коэффициенты модели полностью открыты, размещены на GitHub и призваны ускорить биоинженерные и медицинские исследования. Исследователи и разработчики могут использовать этот инструмент для изучения тайн генома и проектирования новых биологических последовательностей.

Список функций
- Поддерживает моделирование генома в различных областях жизни: позволяет предсказывать и проектировать геномы бактерий, архей и эукариот.
- Возможность работы с длинными последовательностями: обработка последовательностей ДНК длиной до 1 миллиона оснований для анализа очень длинных контекстов.
- Генерация и оптимизация ДНК: генерация новых последовательностей ДНК с аннотациями кодирующих областей на основе исходных последовательностей или видовых подсказок.
- Предсказание эффекта вариантов с нулевой выборкой: предсказание биологического влияния генетических вариантов без дополнительного обучения, например, анализ эффекта вариантов BRCA1.
- Наборы данных и модели с открытым исходным кодом: предоставление предварительно обученных моделей и наборов данных OpenGenome2 для поддержки вторичных разработок и исследований.
- Поддержка параллельных вычислений на нескольких GPU: фреймворк Vortex автоматически распределяет ресурсы нескольких GPU для повышения эффективности крупномасштабных вычислений.
- Интеграция с NVIDIA BioNeMo: бесшовный доступ к платформе биовычислений NVIDIA для расширения сценариев применения.
- Инструменты визуализации и интерпретации: в сочетании с интерпретирующим визуализатором Goodfire показывает биометрические особенности и модели, распознанные моделью.
Использование помощи
Процесс установки
Для локального использования Evo 2 необходимы определенные вычислительные ресурсы и конфигурация среды. Ниже приведены подробные шаги по установке:
1. Подготовка окружающей среды
- операционная система: рекомендуется Linux (например, Ubuntu) или macOS, пользователям Windows необходимо установить WSL2.
- требования к оборудованию: Не менее 1 GPU NVIDIA (для поддержки модели 40B рекомендуется несколько GPU) с минимум 16 ГБ видеопамяти (например, A100 или RTX 3090).
- зависимость от программного обеспечения: Убедитесь, что установлены Git, Python 3.8+, PyTorch (с поддержкой CUDA) и pip.
2. Клонирование репозитория кода
Откройте терминал и выполните следующую команду, чтобы получить исходный код Evo 2:
git clone --recurse-submodules git@github.com:ArcInstitute/evo2.git
cd evo2
Внимание:--recurse-submodules Убедитесь, что все подмодули также загружены.
3. Установка зависимостей
Запустите его в корневом каталоге проекта:
pip install .
Если у вас возникли проблемы, попробуйте установить из Vortex (подробности см. в README на GitHub). После завершения установки запустите тесты для проверки:
python -m evo2.test
Если вывод не сообщает об ошибках, значит, установка прошла успешно.
4. загрузка предварительно обученных моделей
Evo 2 доступен в различных версиях модели (например, параметры 1B, 7B, 40B), которые можно загрузить с Hugging Face или GitHub Releases. Пример:
wget https://huggingface.co/arcinstitute/evo2_7b/resolve/main/evo2_7b_base.pt
Поместите файлы модели в локальный каталог для последующей загрузки.
Как использовать
После установки основные функции Evo 2 могут быть вызваны с помощью скриптов Python. Ниже приведен подробный порядок действий для основных функций:
Функция 1: создание последовательности ДНК
Evo 2 может генерировать последовательность продолжения из входного фрагмента ДНК. Процедура выглядит следующим образом:
- Модели для погрузки::
from evo2 import Evo2 model = Evo2('evo2_7b') # 使用 7B 参数模型 - Введите подсказки и создайте::
prompt = ["ACGT"] # 输入初始 DNA 序列 output = model.generate(prompt_seqs=prompt, n_tokens=400, temperature=1.0, top_k=4) print(output.sequences[0]) # 输出生成的 400 个核苷酸序列 - Интерпретация результатов: Сгенерированные последовательности могут быть использованы для последующих биологических анализов, при этом параметр температуры контролирует стохастичность, а top_k ограничивает диапазон выборки.
Функция 2: Прогнозирование эффектов вариантов нулевой выборки
В качестве примера для предсказания биологического влияния вариантов использовался ген BRCA1:
- Подготовьте данные: Внесите эталонные и вариантные последовательности в список.
- Оперативные прогнозы::
ref_seqs = ["ATCG..."] # 参考序列 var_seqs = ["ATGG..."] # 变体序列 ref_scores = model.score_sequences(ref_seqs) var_scores = model.score_sequences(var_seqs) print(f"Reference likelihood: {ref_scores}, Variant likelihood: {var_scores}") - анализ: Сравните различия в баллах, чтобы оценить потенциальное влияние вариантов на функцию.
Функция 3: Обработка длинных последовательностей
Для очень длинных последовательностей Evo 2 поддерживает загрузку и вычисления с разбивкой по частям:
- Загрузка больших моделей::
model = Evo2('evo2_40b') # 需要多 GPU 支持 - Работа с длинными последовательностями::
long_seq = "ATCG..." * 100000 # 模拟 100 万碱基序列 output = model.generate([long_seq], n_tokens=1000) print(output.sequences[0]) - предостережение: В настоящее время прямое распространение длинных последовательностей может быть медленным, поэтому рекомендуется оптимизировать конфигурацию оборудования или использовать метод подсказки учителя (подсказка учителя).
Функция 4: Наборы данных и вторичная разработка
- Получение набора данных: Загрузите набор данных OpenGenome2 (в формате FASTA или JSONL) с сайта Hugging Face.
- Индивидуальное обучение: Изменение архитектуры модели или точная настройка параметров на основе концепции Savanna для конкретных исследовательских нужд.
Советы по эксплуатации и меры предосторожности
- Конфигурация с несколькими графическими процессорами: Если вы используете модель 40B, вам необходимо убедиться, что Vortex правильно распознает несколько графических процессоров, используя
nvidia-smiПроверьте распределение ресурсов. - оптимизация производительности: Обработка длинных последовательностей уменьшает
temperatureзначения, чтобы уменьшить вычислительную нагрузку. - Поддержка общества: Вопросы могут быть направлены на форум GitHub Issues, где команда Arc Institute и сообщество готовы помочь.
Эти шаги позволят вам быстро и эффективно работать с Evo 2, независимо от того, создаете ли вы последовательности ДНК или анализируете генетические варианты.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...