ER NeRF: Создание системы видеосинтеза для создания высокоточных говорящих голов

Общее введение
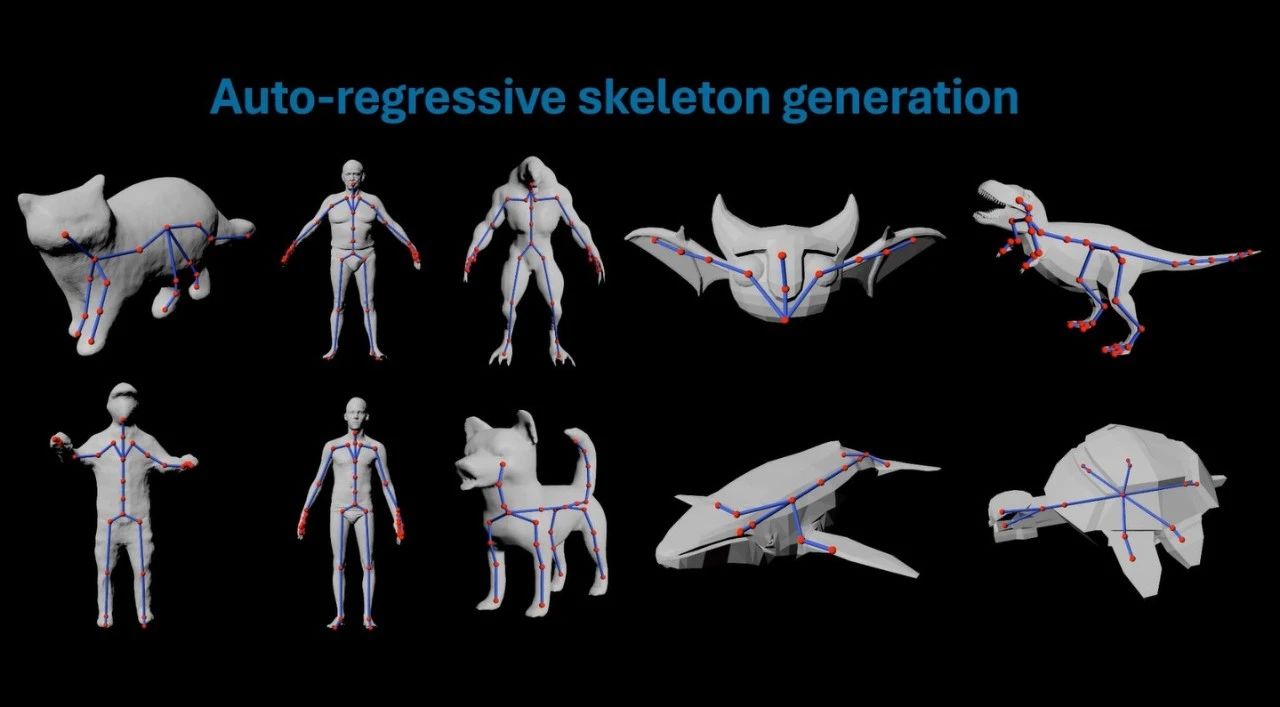
ER-NeRF (Efficient Region-Aware Neural Radiance Fields) - это система синтеза говорящих персонажей с открытым исходным кодом, представленная на ICCV 2023. В проекте используется технология Region-Aware Neural Radiance Fields для эффективного создания высокоточных видеороликов говорящих персонажей. Основными особенностями системы являются схема региональной обработки, которая отдельно моделирует голову и туловище персонажа, и инновационная техника декомпозиции аудиопространства, обеспечивающая более точную синхронизацию губ. Проект предоставляет полный код обучения и вывода, поддерживает пользовательские обучающие видеоролики и может использовать различные экстракторы звуковых признаков (например, DeepSpeech, Wav2Vec, HuBERT и т. д.) для обработки входного аудиосигнала. Система достигает значительного улучшения как визуального качества, так и вычислительной эффективности, обеспечивая важное техническое решение в области синтеза говорящих персонажей.
Новый проект: https://github.com/Fictionarry/TalkingGaussian

Список функций
- Высокоточное видеокомпозитирование говорящих голов
- Нейронный рендеринг поля излучения для восприятия области
- Поддерживает раздельное моделирование головы и туловища
- Точная синхронизация губ
- Поддержка извлечения нескольких аудиофункций (DeepSpeech/Wav2Vec/HuBERT)
- Индивидуальная поддержка видеообучения
- Создание анимации персонажей с помощью звука
- Плавное управление движением головы
- Поддержка движения мигания (функция AU45)
- Функция оптимизации с точной настройкой LPIPS
Использование помощи
1. конфигурация окружающей среды
Требования к операционной среде системы:
- Операционная система Ubuntu 18.04
- PyTorch версии 1.12
- CUDA 11.3
Этапы установки:
- Создайте среду conda:
conda create -n ernerf python=3.10
conda install pytorch==1.12.1 torchvision==0.13.1 cudatoolkit=11.3 -c pytorch
pip install -r requirements.txt
- Установите дополнительные зависимости:
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
pip install tensorflow-gpu==2.8.0
2. Подготовка моделей для предварительной обработки
Необходимо загрузить и подготовить следующие файлы моделей:
- Модель разбора лица
- Модель оценки положения головы 3DMM
- Basel Face Model 2009
3. Настройка процесса видеообучения
- Требования к подготовке видео:
- Формат: MP4
- Частота кадров: 25FPS
- Разрешение: рекомендуется 512x512
- Продолжительность: 1-5 минут
- Требуется, чтобы каждый кадр содержал говорящие символы
- Предварительная обработка данных:
python data_utils/process.py data/<ID>/<ID>.mp4
- Извлечение аудио признаков (один из трех):
- Извлечение признаков из DeepSpeech:
python data_utils/deepspeech_features/extract_ds_features.py --input data/<n>.wav
- Извлечение признаков из Wav2Vec:
python data_utils/wav2vec.py --wav data/<n>.wav --save_feats
- Извлечение признаков HuBERT (рекомендуется):
python data_utils/hubert.py --wav data/<n>.wav
4. Обучение модели
Обучение делится на две фазы: обучение головы и обучение туловища:
- Головная тренировка:
python main.py data/obama/ --workspace trial_obama/ -O --iters 100000
python main.py data/obama/ --workspace trial_obama/ -O --iters 125000 --finetune_lips --patch_size 32
- Тренировка торса:
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --head_ckpt <head>.pth --iters 200000
5. тестирование и вывод моделей
- Испытайте эффекты модели:
# 仅渲染头部
python main.py data/obama/ --workspace trial_obama/ -O --test
# 渲染头部和躯干
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test
- Рассуждения с целевым аудио:
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --test --test_train --aud <audio>.npy
Совет: Добавление параметра --smooth_path уменьшает дрожание головы, но может снизить точность ориентации.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...