
DreamOmni2 - модель редактирования и генерации мультимодальных изображений ИИ с открытым исходным кодом HKUST

Что такое DreamOmni2
DreamOmni2 - это мультимодальная модель редактирования и генерации изображений с открытым исходным кодом, созданная командой Цзяцзя в HKUST. Она может одновременно обрабатывать текстовые и графические команды и поддерживать несколько опорных изображений, предоставляя авторам более гибкие методы создания. Модель обучается с помощью трехэтапного процесса синтеза данных, который совместно обучает модель генерации/редактирования и модель визуального языка, эффективно сохраняя идентичность объекта изображения. DreamOmni2 отлично справляется с задачами мультимодального редактирования и генерации команд, превосходя текущие модели с открытым исходным кодом, а в некоторых аспектах сравниваясь с коммерческими моделями или превосходя их. Он может использоваться в различных сценариях, включая фотографирование продуктов, рабочий процесс дизайна, редактирование портретов и творческую живопись.
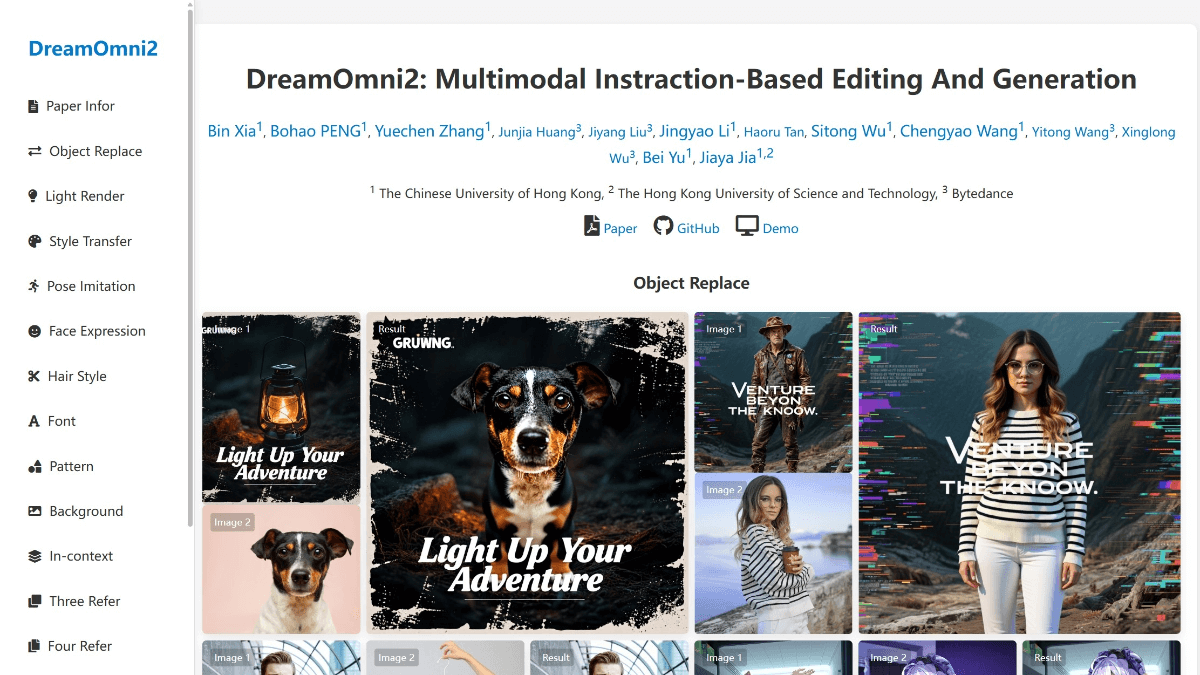
Особенности DreamOmni2
- мультимодальная обработка инструкций: Поддерживает текстовые и графические команды для работы как с конкретными объектами, так и с абстрактными понятиями, такими как материалы, текстуры, стили и т. д., предоставляя творцам более богатые возможности для самовыражения.
- Возможность построения диаграмм с несколькими ссылками: Возможность объединения нескольких эталонных изображений для редактирования и создания обеспечивает творцам большую гибкость для удовлетворения сложных и разнообразных творческих потребностей.
- Обобщение данных и обучение: Используется трехэтапный процесс синтеза данных, включающий методы смешивания признаков, редактирования и извлечения моделей для создания обучающих данных, а также схемы кодирования индексов и смещения позиционного кодирования, позволяющие избежать путаницы пикселей в нескольких входных изображениях и улучшить эффект обучения и качество генерации модели.
- совместное обучение: Совместное обучение генеративной/редактирующей модели с моделью визуального языка (VLM) для лучшей обработки сложных команд позволяет модели более точно понимать и выполнять мультимодальные команды пользователя.
- Поддержание последовательности идентификации: В процессе редактирования можно эффективно поддерживать идентичность характеристик объекта изображения, чтобы обеспечить согласованность между отредактированным изображением и оригинальным объектом, а также избежать потери или смешения характеристик объекта, вызванных редактированием.
- Преимущества производительности: В задачах редактирования и генерации мультимодальных команд DreamOmni2 значительно превосходит существующие модели SOTA с открытым исходным кодом, а в некоторых аспектах даже превосходит коммерческие модели, предоставляя пользователям более качественные результаты редактирования и генерации изображений.
- Открытый исходный код и простота использованияКод, веса моделей и наборы обучающих данных находятся в свободном доступе на GitHub и Hugging Face и поддерживают локальный запуск, что позволяет пользователям выполнять локальные выводы на CUDA-совместимых GPU с достаточным объемом видеопамяти, снижая порог использования и повышая доступность моделей.
Основные преимущества DreamOmni2
- Понимание мультимодального обучения: Способность обрабатывать текстовые и графические команды, понимать и точно выполнять сложные задачи редактирования, такие как изменение материалов, текстур, стилей и других абстрактных понятий.
- Поддержка диаграмм с несколькими ссылками: Можно комбинировать с несколькими эталонными изображениями для редактирования и создания, обеспечивая творцам большую гибкость для удовлетворения различных творческих потребностей.
- Поддержание последовательности идентификации: В процессе редактирования эффективно сохраняются идентичные характеристики объекта изображения, чтобы обеспечить высокое соответствие отредактированного изображения оригинальному объекту и избежать потери или смешения характеристик объекта.
- Совместный механизм обучения: Совместное обучение генеративных/редактирующих моделей с моделями визуального языка улучшает понимание и выполнение сложных команд и генерирует изображения, которые лучше соответствуют намерениям пользователя.
- превосходная производительность: Значительно превосходит существующие модели с открытым исходным кодом, а в некоторых отношениях даже превосходит коммерческие модели, в задачах редактирования и генерации мультимодальных команд, обеспечивая высокое качество редактирования и генерации изображений.
Что такое официальный сайт DreamOmni2
- Веб-сайт проекта:: https://pbihao.github.io/projects/DreamOmni2/index.html
- Репозиторий Github:: https://github.com/dvlab-research/DreamOmni2
- Технический документ arXiv:: https://arxiv.org/pdf/2510.06679
- Адрес опыта:: https://huggingface.co/spaces/wcy1122/DreamOmni2-Gen
Для кого предназначен DreamOmni2?
- Креативный дизайнер: Он позволяет быстро реализовать дизайнерские идеи, создать несколько стилей эскизов и повысить эффективность работы.
- Операторы: Используется для постобработки фотографий товаров, чтобы усилить визуальный эффект продуктов и удовлетворить потребности различных клиентов.
- художники: Создавайте быстрые рисунки и картины, изучая различные стили и идеи для вдохновения.
- рекламное агентство: Быстрое создание рекламных материалов, отвечающих требованиям различных рекламных тем и стилей.
- Индивидуальные создатели: Легко воплощайте творческие идеи и создавайте индивидуальные изображения для удовлетворения индивидуальных творческих потребностей.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...