
Выпущена Doubao-1.5-pro: новая мультимодальная базовая модель для предельного баланса

Doubao-1.5-pro
🌟 Профиль модели
Doubao-1.5-pro - это сильно разреженный Архитектура МОВ четырех квадрантах Prefill/Decode и Attention/FFN характеристики вычислений и доступа существенно различаются. Для четырех различных квадрантов мы используем гетерогенное оборудование в сочетании с различными стратегиями оптимизации низкой точности, чтобы значительно увеличить пропускную способность, обеспечивая низкую задержку, и снизить общую стоимость, принимая во внимание цели оптимизации TTFT и TPOT, достигая окончательного баланса между производительностью и эффективностью выводов.
- незначительный параметр активации: Превосходит производительность очень больших плотных моделей.
- Многосюжетная адаптация: Превосходство по многим показателям.
📊 Оценка производительности
Результаты работы Doubao-1.5-pro в нескольких бенчмарках
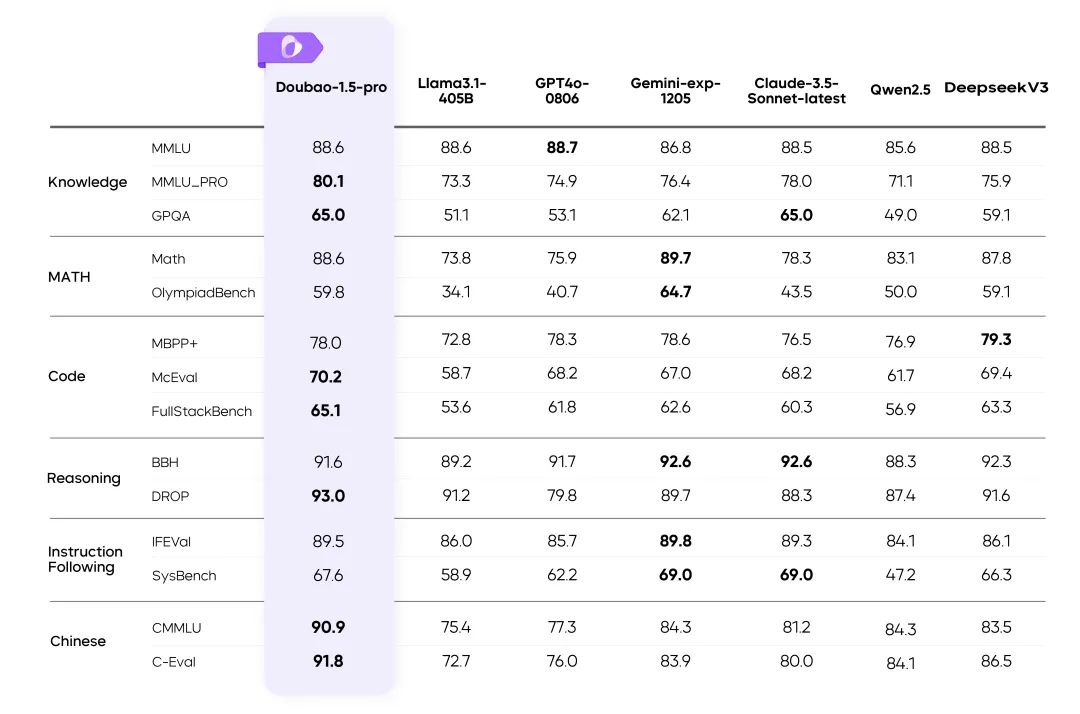
инструкции::
- Показатели для остальных моделей в таблице взяты из официальных результатов, а неопубликованные части сделаны внутренней оценочной платформой.
- GPT4o-0806 Отличные показатели в публичных обзорах языковых моделей, см.: simple-evals.
⚙️ Баланс между производительностью и рассудительностью
Эффективная архитектура MoE
- пользоваться Разреженная архитектура MoE Достижение двойной оптимизации эффективности обучения и рассуждений.
- Основные моменты исследования: Определите оптимальное соотношение производительности и эффективности с помощью закона масштабирования разреженности.
Тренировка "Потеря и потеря".

Сравнение производительности моделей
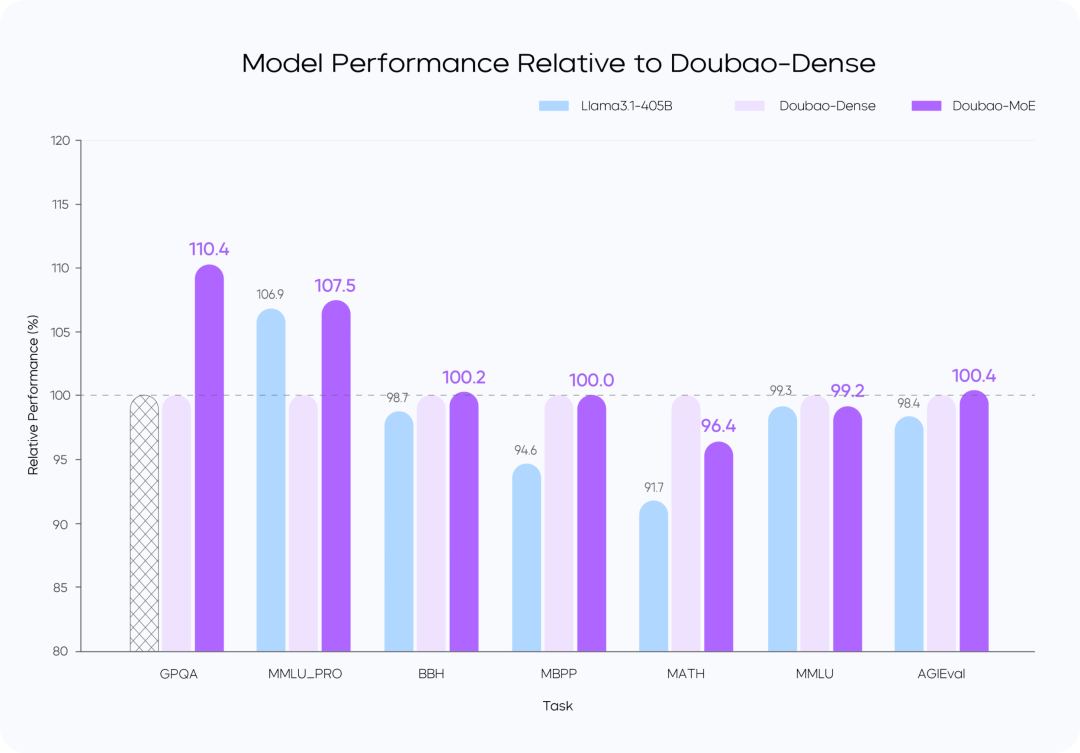
инструкции::
- Модель Doubao-MoE превосходит плотную модель с в 7 раз большим количеством активируемых параметров (Doubao-Dense).
- Дубао Плотное обучение модели более эффективно, чем Ллама 3.1-405BКачество данных и оптимизация гиперссылок имеют ключевое значение.
🚀 Высокопроизводительные рассуждения
Оптимизация вычислений и возможностей доступа
Doubao-1.5-pro демонстрирует хорошие результаты в четырех вычислительных квадрантах: Prefill, Decode, Attention и FFN.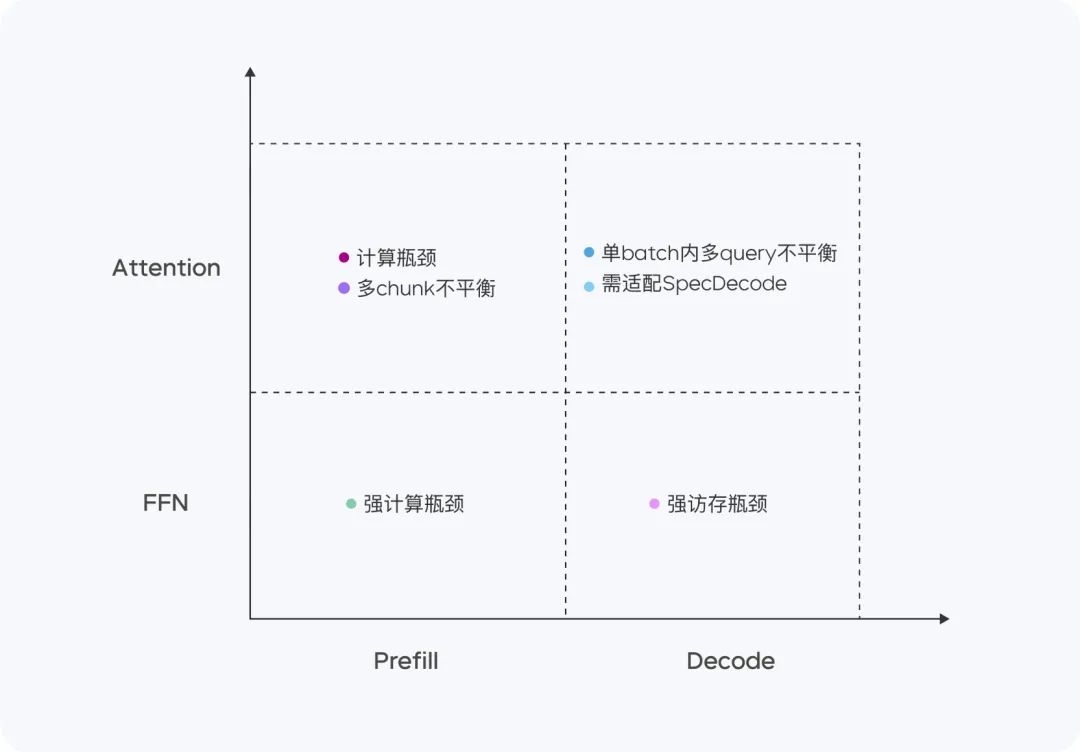
На этапе предварительного заполнения узкое место в связи и доступе неочевидно, но узкое место в вычислениях легко достижимо. Учитывая характеристики одностороннего внимания LLM, мы выполняем Chunk-PP Prefill Serving на нескольких устройствах с высоким коэффициентом доступа к вычислениям, так что коэффициент использования Tensor Core в онлайн-системе близок к 60%.
- Prefill Attention: расширяет 8-битную реализацию FlashAttention с открытым исходным кодом с помощью таких инструкций, как MMA/WGMMA, в сочетании с Per N жетоны Стратегия квантования последовательностей гарантирует, что эта фаза может выполняться без потерь на GPU различных архитектур. В то же время, моделируя потребление внимания фрагментами разной длины и комбинируя со стратегией динамического пакетирования перекрестных запросов, она обеспечивает межкарточную балансировку во время Chunk-PP Serving, эффективно устраняя пустую работу, вызванную дисбалансом нагрузки;
- Предварительное заполнение FFN: квантование W4A8 эффективно снижает накладные расходы на доступ к разреженным экспертам MoE и дает больше входов на этап FFN благодаря стратегии пакетной обработки перекрестных запросов, что улучшает MFU до 0,8.
На этапе декодирования вычислительное узкое место неочевидно, но требования к связи и памяти относительно высоки. Мы используем Serving, устройство с меньшими вычислениями и памятью, чтобы получить более высокий ROI, и в то же время мы используем очень дешевую выборку и стратегию спекулятивного декодирования, чтобы уменьшить метрику TPOT.
- Decode Attention: TP используется для оптимизации распространенного сценария больших различий в длине KV разных запросов в одной партии с помощью эвристического поиска и агрессивной стратегии разбиения длинных предложений; с точки зрения точности по-прежнему используется квантификация Per N tokens Per Sequence; кроме того, вычисление Attention во время случайной выборки оптимизировано так, чтобы KV Cache был доступен только один раз. Кроме того, мы оптимизируем вычисление внимания во время случайной выборки, чтобы обеспечить однократное обращение к KV-кешу.
- Декодируйте FFN: поддерживайте W4A8 в количественном состоянии и развертывайте с помощью EP.
В целом, мы реализовали следующие оптимизации в системе PD separated Serving:
- Настроенный RPC Backend для передачи тензоров и оптимизированная эффективность передачи тензоров по сети TCP/RDMA за счет нулевого копирования, многопоточного параллелизма и т. д., что, в свою очередь, повышает эффективность передачи KV Cache при разделении PD.
- Он поддерживает гибкое распределение и динамическое расширение и сокращение кластеров Prefill и Decode, а также эластичное расширение HPA для каждой роли независимо, чтобы гарантировать, что Prefill и Decode не имеют избыточной арифметики, а распределение арифметики между двумя сторонами соответствует реальной структуре онлайн-трафика.
- В рамках вычислений на GPU и CPU предварительная и последующая обработка асинхронны, так что GPU рассуждает шаг N, когда CPU рано запускает N + 1 шаг ядра, чтобы GPU всегда был полон, весь каркас обработки действий GPU рассуждает с нулевыми накладными расходами. Кроме того, благодаря самостоятельно разработанному серверному кластерному решению и гибкой поддержке недорогих чипов, стоимость аппаратного обеспечения значительно ниже, чем у промышленных решений. Мы также значительно оптимизировали эффективность пакетной передачи данных благодаря специализированным сетевым картам и самостоятельно разработанным сетевым протоколам. На арифметическом уровне мы добились эффективного перекрытия (Overlap) между вычислениями и коммуникациями, что обеспечивает стабильность и эффективность многокомпьютерных распределенных вычислений.
🎯 Маркировка данных: никаких коротких путей
- Создайте эффективную систему производства данных, которая объединит Команда по маркировке ответить пением Моделирование техники самоподнятияКачество данных было значительно улучшено.
🖼️ Мультимодальные возможности
Визуальная мультимодальность: сложные сцены становятся простыми
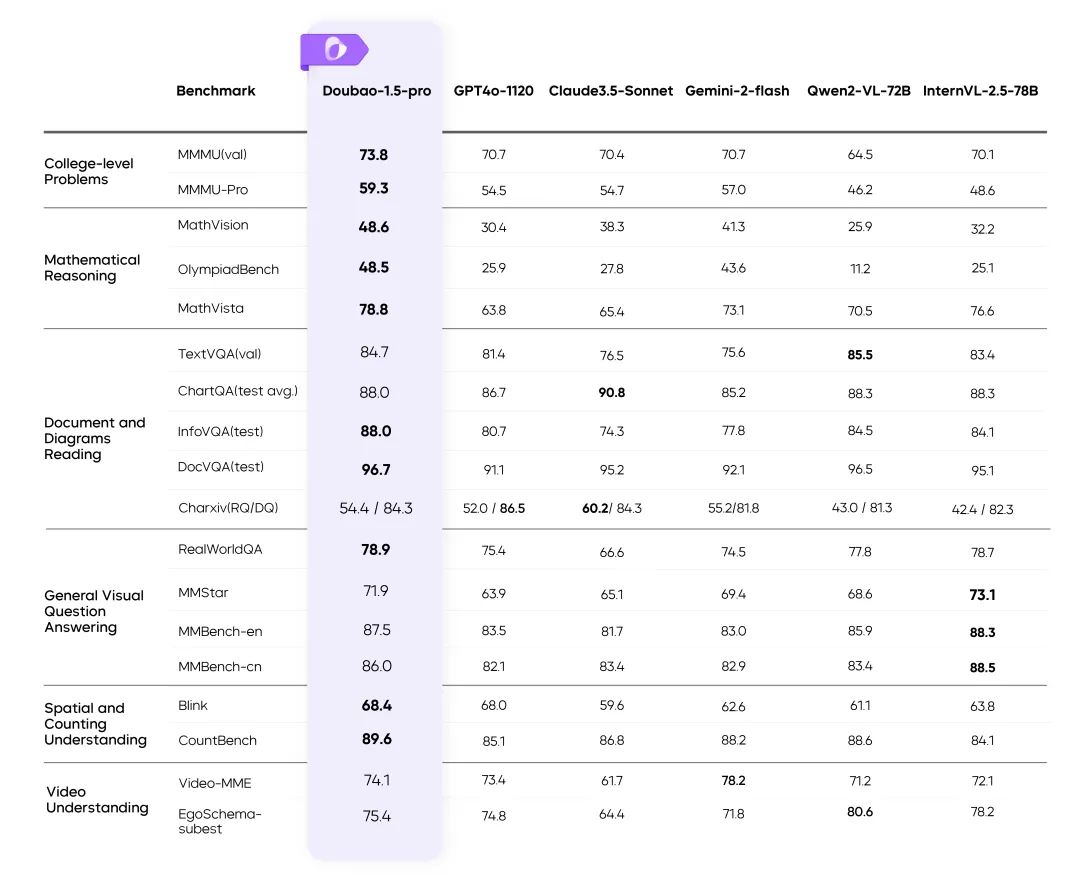
Обучение с динамическим разрешением: повышение пропускной способности 60%
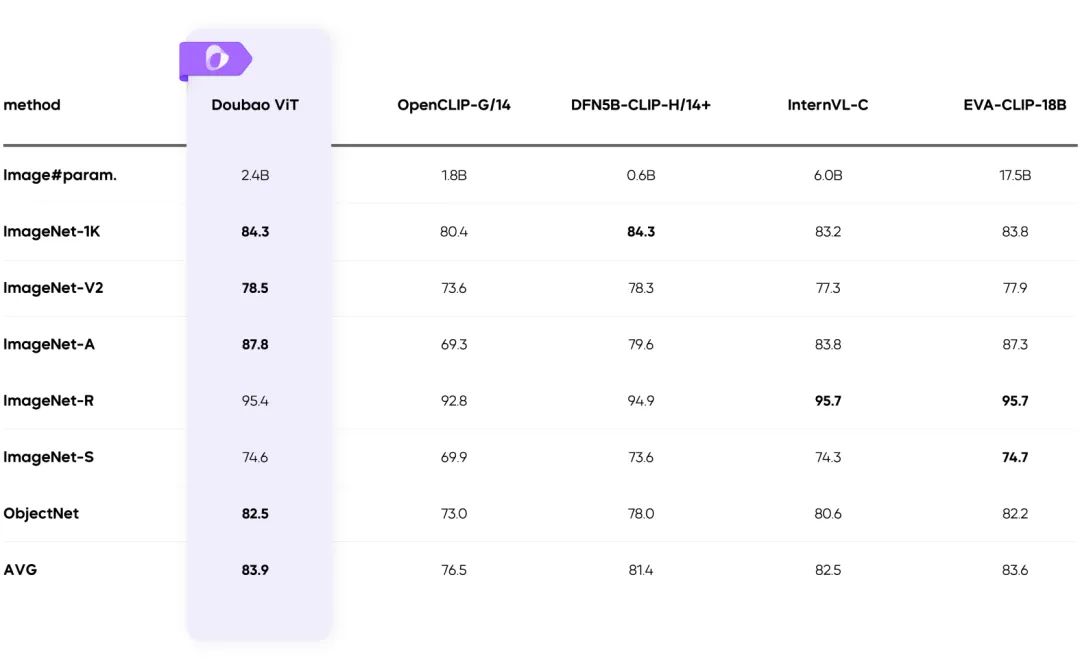
- Решает проблему неравномерной нагрузки на визуальный кодер и значительно повышает его эффективность.
✅ Резюме
Doubao-1.5-pro находит оптимальный баланс между высокой производительностью и низкой стоимостью выводов и совершает прорыв в мультимодальных сценариях:
- Инновационный дизайн разреженной архитектуры.
- Высококачественные учебные данные и системы оптимизации.
- Новый стандарт в области мультимодальных технологий.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...