
Понятная статья Дистилляция знаний (Distillation): пусть у "маленькой модели" будет и "большая мудрость".

Дистилляция знаний - это метод машинного обучения, целью которого является передача знаний от большой предварительно обученной модели (т.е. "модели учителя") к меньшей "модели ученика". Методы дистилляции могут помочь нам разработать более легкие генеративные модели для использования в таких областях, как интеллектуальный диалог и создание контента.
ближайший (из мест) Дистилляция Это слово встречается очень часто.
Команда DeepSeek, которая произвела фурор два дня назад, выпустила DeepSeek-R1В результате применения методов обучения с усилением и дистилляции большая модель с 670 параметрами была успешно перенесена в облегченную модель с 7 параметрами.
Дистиллированная модель превосходит традиционные модели того же размера и даже приближается к лучшей небольшой модели OpenAI, OpenAI-o1-mini.
В области искусственного интеллекта используются большие языковые модели (например, GPT-4, DeepSeek-R1 ) продемонстрировал отличные возможности рассуждений и генерации данных с сотнями миллиардов параметров. Однако огромные вычислительные требования и высокая стоимость развертывания существенно ограничивают его применение в таких сценариях, как мобильные устройства и пограничные вычисления.
Как сжать размер модели без потери производительности?Дистилляция знаний(Knowledge Distillation) - ключевая техника для решения этой проблемы.
1. Что такое дистилляция знаний
Дистилляция знаний - это метод машинного обучения, целью которого является передача знаний от большой предварительно обученной модели (т.е. "модели учителя") к меньшей "модели ученика".
В глубоком обучении он используется как форма сжатия модели и передачи знаний, особенно для крупномасштабных глубоких нейронных сетей.
Суть дистилляции знаний заключается в следующеммиграция знанийкоторый имитирует выходное распределение модели учителя, так что модель ученика наследует ее способность к обобщению и логику рассуждений.
- Модель преподавателя(Teacher Model): обычно сложная модель с большим количеством параметров и достаточным обучением (например, DeepSeek-R1), на выходе которой содержатся не только результаты предсказания, но и неявная информация о сходстве между категориями.
- Модели для студентов(Модель ученика: небольшая, компактная модель с меньшим количеством параметров, которая обеспечивает передачу компетенций благодаря соответствию мягким целям модели учителя.
В отличие от традиционного глубокого обучения, где целью является обучение искусственной нейронной сети делать предсказания, более похожие на образцы, представленные в обучающем наборе данных, дистилляция знаний требует, чтобы модель ученика не только соответствовала правильному ответу (это сложная задача), но и изучала "логику мышления" модели учителя. -Т.е. выходраспределение вероятностей(мягкая мишень).
Например, в задании на классификацию изображений модель преподавателя будет не только утверждать, что "на этой картинке изображена кошка" (уверенность 90%), но и давать такие варианты, как "похоже на лису" (5%), "другие животные " (5%) и другие возможности.
Эти значения вероятности похожи на "легкие баллы", которые ставит учитель при проверке экзаменационных работ. Улавливая корреляции (например, у кошек и лисиц похожие заостренные уши и шерсть), студенческая модель со временем научится быть более гибкой в своей способности к дискриминации, а не механически запоминать стандартные ответы.
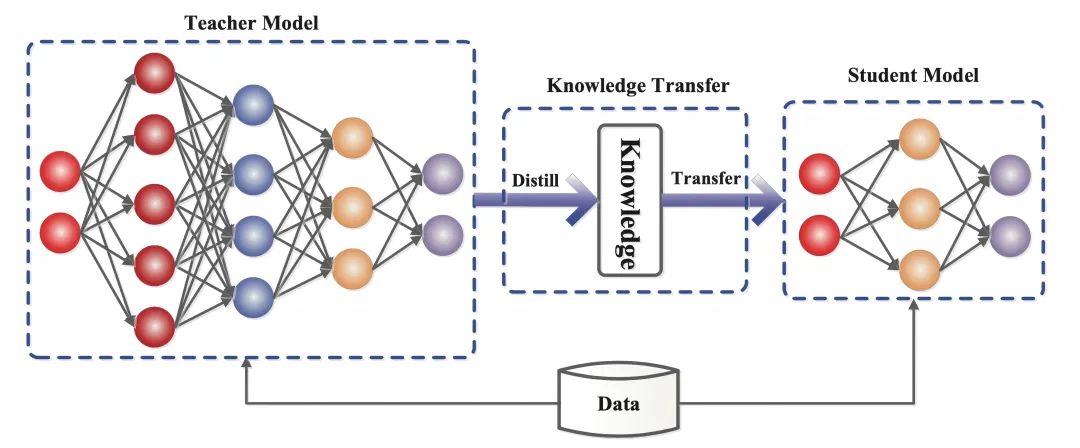
2. Знание принципов дистилляции
В статье 2015 года Distilling the Knowledge in a Neural Network, в которой предлагается разделить обучение на два этапа с разными целями, авторы проводят аналогию: если личиночная форма многих насекомых оптимизирована для извлечения энергии и питательных веществ из окружающей среды, то взрослая форма совершенно другая, оптимизированная для передвижения и размножения, тогда как традиционное глубокое обучение использует одни и те же модели на этапах обучения и развертывания, хотя у них разные требования.
Понимание "знания" в работах также разнится:
До публикации статьи существовала тенденция отождествлять знания обучающей модели с выученными значениями параметров, что затрудняло понимание того, как можно сохранить те же знания при изменении формы модели.
Более абстрактное представление о знании заключается в том, что оно является усвоеннымПереход от входного вектора к выходному вектору.
Методы дистилляции знаний не только воспроизводят выходные данные моделей преподавателей, но и имитируют их "мыслительные процессы". В эпоху LLM дистилляция знаний позволяет передавать такие абстрактные качества, как стиль, способность рассуждать, соответствие предпочтениям и ценностям человека.
Реализацию дистилляции знаний можно разбить на три основных этапа:
2.1 Генерация мягких целей: "фаззификация" ответа
Модель учителя передаетсяВысокотемпературный SoftmaxТехнология преобразует "черно-белые" ответы в "нечеткие подсказки", содержащие подробную информацию.
При увеличении температуры (Temperature) (например, T=20) распределение вероятностей на выходе модели становится более гладким.
Например, оригинальное суждение "Кот (90%), Лиса (5%)".
Может стать "Кот (60%), Лиса (20%), Другой (20%)".
Эта адаптация заставляет ученические модели фокусироваться на корреляциях между категориями (например, у кошек и лисиц одинаковые по форме уши), а не на механическом запоминании обозначений.
2.2 Разработка целевых функций: баланс между мягкими и жесткими целями
Цели обучения в студенческой модели две:
- Подражайте логике мышления учителя(Мягкая цель): изучение межклассных отношений путем сопоставления высокотемпературных вероятностных распределений учителей.
- Запомните правильный ответ.(Жесткая цель): обеспечить отсутствие снижения базовой точности.
Функция потерь в модели студента представляет собой взвешенную комбинацию мягких и жестких целей, и веса обеих функций необходимо динамически регулировать.
Например, если назначить веса 70% для мягких целей и 30% для жестких, это будет похоже на то, как если бы студенты тратили 70% времени на изучение решений учителя и 30% времени на закрепление стандартных ответов, в конечном итоге достигая баланса между гибкостью и точностью.
2.3 Динамическое регулирование температурных параметров, контроль "гранулярности передачи" знаний.
Параметр температуры - это "ручка сложности" интеллектуальной дистилляции:
- Режим высокой температуры(например, T=20): ответы весьма неоднозначны и подходят для передачи сложных ассоциаций (например, различение разных пород кошек).
- низкотемпературный режим(например, T = 1): ответы близки к исходному распределению и подходят для решения простых задач (например, распознавания чисел).
- динамичная стратегия: Экстенсивное поглощение знаний с высокой температурой вначале и последующее охлаждение, чтобы сосредоточиться на ключевых особенностях.
Например, задачи распознавания речи требуют более низких температур для поддержания точности. Этот процесс похож на то, как учитель регулирует глубину обучения в зависимости от уровня ученика - от эвристики до сдачи тестов.
3. Важность дистилляции знаний
Самые эффективные модели для конкретной задачи, как правило, слишком большие, медленные или дорогие для большинства реальных случаев использования, но они имеют отличную производительность, которая обусловлена их размером и возможностью предварительного обучения на больших объемах обучающих данных.
Напротив, небольшие модели, хотя и работают быстрее и требуют меньше вычислительных затрат, являются менее точными, менее совершенными и менее осведомленными, чем большие модели с большим количеством параметров.
Именно здесь, например, проявляется ценность применения дистилляции знаний:
Большая 670-параметрическая модель DeepSeek-R1 переносит свои возможности на облегченную 7-параметрическую модель с помощью техники дистилляции знаний: DeepSeek-R1-7B, которая превосходит неинференционные модели, такие как GPT-4o-0513, по всем параметрам. DeepSeek-R1-14B превосходит QwQ-32BPreview по всем метрикам оценки, в то время как DeepSeek-R1-32B и DeepSeek-R1-70B значительно превосходят o1-mini в большинстве бенчмарков.
Эти результаты свидетельствуют о большом потенциале дистилляции. Дистилляция знаний стала важным техническим инструментом.
В области обработки естественного языка многие исследовательские институты и компании используют методы дистилляции для сжатия больших языковых моделей в более компактные версии для таких задач, как перевод, диалоговые системы и классификация текстов.
Например, большие модели, после их обработки, можно запускать на мобильных устройствах, чтобы предоставлять услуги перевода в режиме реального времени, не прибегая к мощным облачным вычислительным ресурсам.
Ценность дистилляции знаний становится еще более значительной в IoT и пограничных вычислениях. Если большие традиционные модели часто требуют поддержки мощных GPU-кластеров, то небольшие модели дистиллируются для работы на микропроцессорах или встраиваемых устройствах с гораздо меньшим энергопотреблением.
Эта технология не только значительно снижает затраты на развертывание, но и позволяет более широко использовать интеллектуальные системы в таких областях, как здравоохранение, автономное вождение и "умные дома".
В будущем возможности применения дистилляции знаний станут еще шире. С развитием генеративного ИИ технология дистилляции может помочь нам разработать более легкие генеративные модели для интеллектуального диалога, создания контента и других областей.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...