
DINOv3 - базовая модель самоконтроля зрения нового поколения от Meta AI

Что такое DINOv3?
DINOv3 Да Мета ИИ DINOv3 - это новое поколение базовой модели самоконтролируемого зрения, которая использует парадигму самоконтролируемого обучения для изучения особенностей изображений без маркировки данных. Благодаря улучшению подготовки данных и введению привязки по Граму решается проблема деградации признаков и повышается способность к обобщению. DINOv3 предоставляет две архитектуры опорных сетей, ViT и ConvNeXt, из которых ViT-7B является самой большой на данный момент версией, содержащей 6,7 миллиарда параметров. Модель может генерировать высококачественные плотные представления признаков, которые точно передают локальные связи и пространственную информацию изображений. Она отлично справляется с широким спектром визуальных задач, таких как классификация изображений, обнаружение целей, семантическая сегментация и т. д., и может превзойти многие профессиональные модели без тонкой настройки под конкретную задачу. DINOv3 поддерживает извлечение признаков высокого разрешения, что подходит для анализа медицинских изображений, мониторинга окружающей среды и других сценариев, требующих высокоточных признаков.
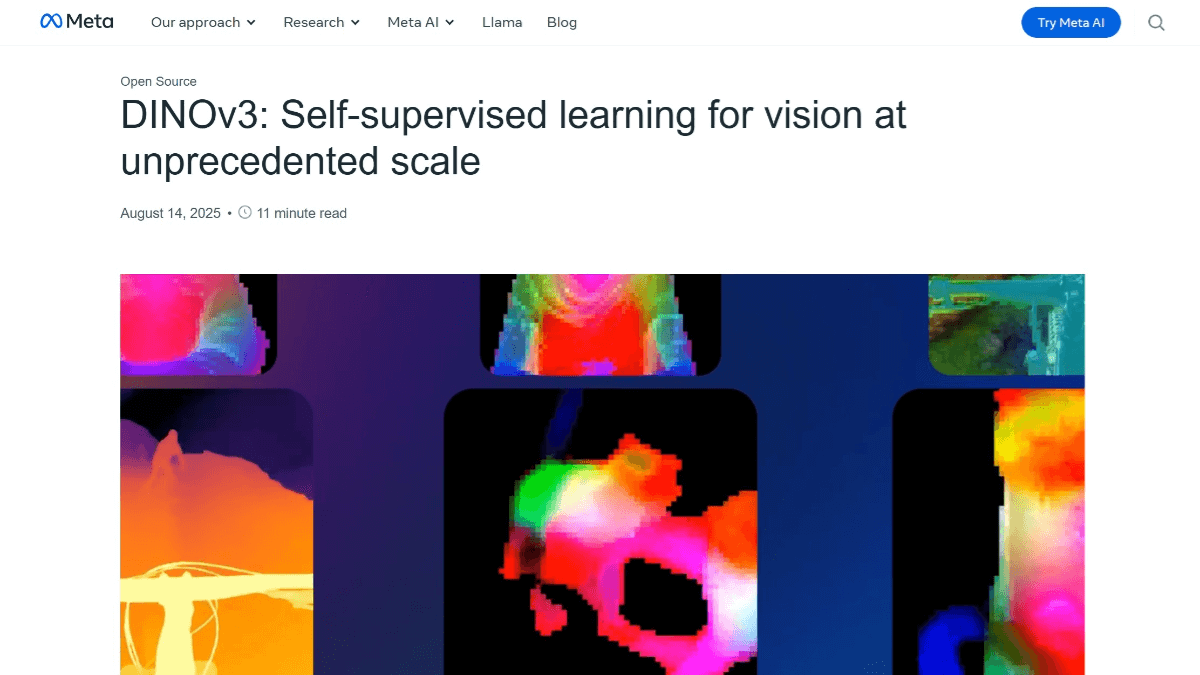
Особенности DINOv3
- Возможность самостоятельного обученияМодель может изучать особенности изображений без меченых данных и решает проблему ухудшения характеристик при длительном обучении за счет улучшения подготовки данных и введения привязки по Граму, что улучшает обобщающую способность модели.
- Многочисленные архитектуры магистральных сетейДве архитектуры магистральных сетей, ViT и ConvNeXt, доступны для удовлетворения различных вычислительных потребностей, причем ViT-7B является самой большой версией на сегодняшний день, содержащей 6,7 миллиарда параметров.
- Высококачественное представление признаков: Он может генерировать высококачественные плотные представления признаков, которые точно передают локальные отношения и пространственную информацию изображений для широкого спектра визуальных задач.
- Многофункциональность: хорошо справляется с такими задачами, как классификация изображений, обнаружение целей, семантическая сегментация и т.д., превосходя многие профессиональные модели без тонкой настройки под конкретную задачу и значительно снижая затраты на вывод.
- Извлечение признаков с высоким разрешением: Поддержка извлечения признаков высокого разрешения для сценариев, требующих высокоточных признаков, таких как анализ медицинских изображений и мониторинг окружающей среды.
Основные преимущества DINOv3
- Мощное самоконтролируемое обучениеОна не требует большого количества меченых данных и обеспечивает эффективное обучение благодаря инновационному механизму самоконтроля, который решает проблему деградации признаков и улучшает способность модели к обобщению.
- Гибкие варианты архитектурыАрхитектуры магистральных сетей ViT и ConvNeXt позволяют удовлетворить различные требования к вычислительным ресурсам и задачам, обеспечивая баланс между производительностью и эффективностью.
- Высококачественное представление признаков: Сгенерированные признаки точно передают локальные связи и пространственную информацию изображения и подходят для широкого спектра визуальных задач с отличной производительностью.
- Многофункциональность: Превосходит профессиональные модели без специальной тонкой настройки в таких задачах, как классификация изображений, обнаружение целей, семантическая сегментация и т. д., снижая затраты на разработку.
- Извлечение признаков с высоким разрешениемОн поддерживает извлечение признаков с высоким разрешением и подходит для анализа медицинских изображений, мониторинга окружающей среды и других сценариев, требующих высокой точности.
- Открытый исходный код и простота использования: Открытый исходный код и модели, поддержка библиотек Hugging Face Hub и Transformers, простота быстрого начала работы и разработки приложений.
Какой официальный сайт у DINOv3?
- Веб-сайт проекта:: https://ai.meta.com/blog/dinov3-self-supervised-vision-model/
- Библиотека моделей HuggingFace:: https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
- Технические документы:: https://ai.meta.com/research/publications/dinov3/
Для кого предназначена DINOv3
- Исследователи компьютерного зренияDINOv3 предоставляет мощные возможности самоконтроля и высококачественные представления признаков, подходящие для специалистов, занимающихся исследованием визуальных задач, таких как классификация изображений, обнаружение целей и семантическая сегментация.
- Разработчик глубокого обученияОткрытый исходный код и предварительно обученные модели делают DINOv3 идеальным решением для разработчиков глубокого обучения, позволяющим быстро создавать и внедрять приложения для зрения в сценариях, требующих эффективной разработки и оптимизации.
- Специалист по медицинской визуализации: Возможность извлечения признаков высокого разрешения имеет большой потенциал в области анализа медицинских изображений для задач медицинской диагностики, требующих высокоточных признаков, таких как анализ рентгеновских снимков, КТ и МРТ.
- Специалисты по мониторингу окружающей среды и географическим информационным системам (ГИС)DINOv3 может использоваться для решения задач экологического мониторинга, таких как анализ спутниковых снимков и мониторинг вырубки лесов, обеспечивая техническую поддержку работ, связанных с ГИС.
- Инженер по зрению роботовВысокоточные функции зрения и многозадачность DINOv3 делают его идеальным решением для роботизированных систем технического зрения для задач визуального восприятия в сложных условиях, например, для роботов-исследователей Марса.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...