DeepSeek-VL2: экспертная модель визуального языка для расширенного мультимодального понимания

Общее введение
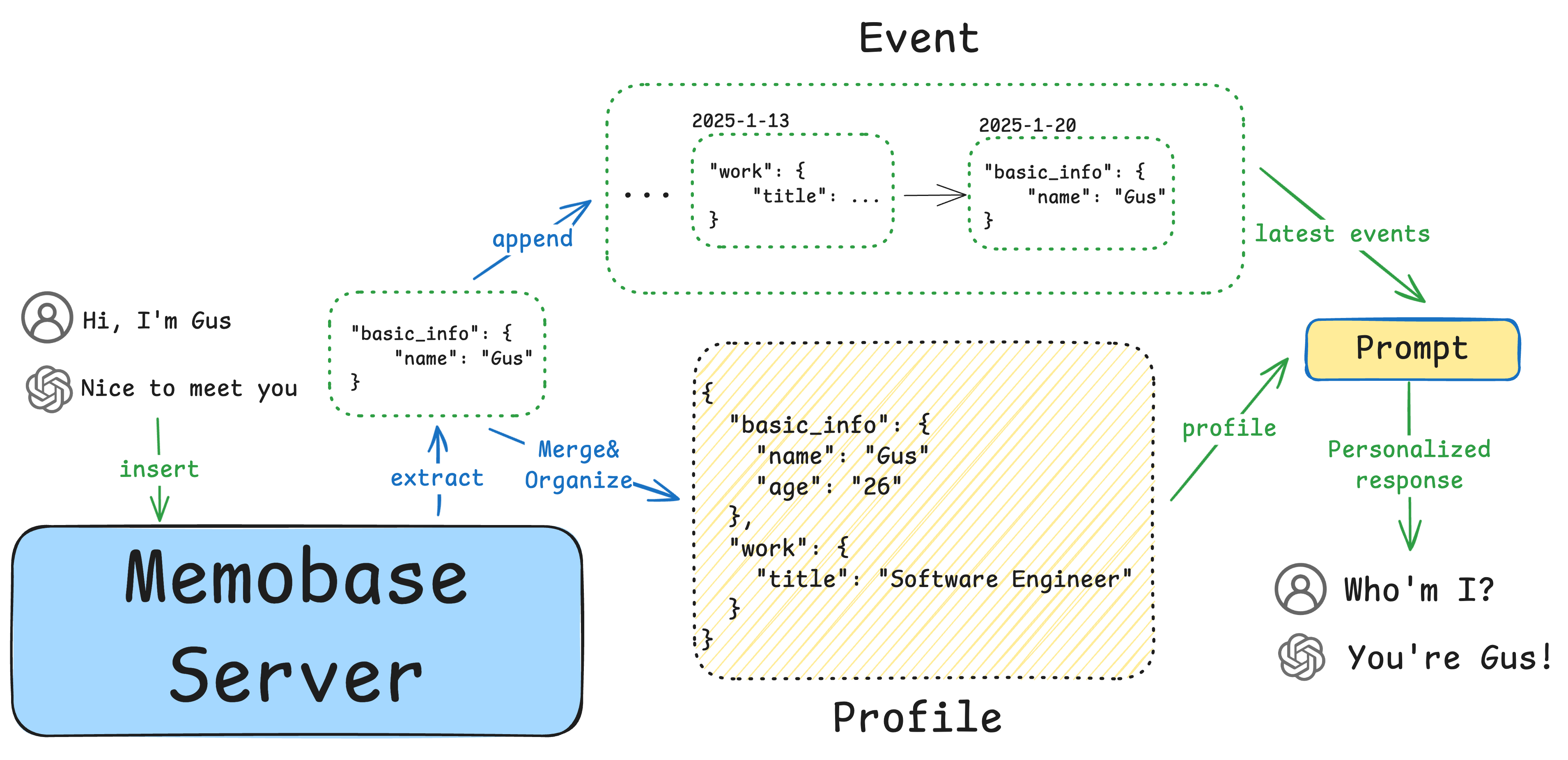
DeepSeek-VL2 - это серия усовершенствованных визуальных языковых моделей Mixture-of-Experts (MoE), которые значительно превосходят по производительности свою предшественницу DeepSeek-VL. Модели отлично справляются с такими задачами, как визуальный ответ на вопрос, оптическое распознавание символов, понимание документов/таблиц/диаграмм и визуальная локализация. Семейство DeepSeek-VL2 состоит из трех вариантов: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small и DeepSeek-VL2, которые имеют 1,0B, 2,8B и 4,5B параметров активации соответственно. параметров активации, соответственно. Эти модели по производительности сопоставимы или превосходят существующие открытые модели плотности и MoE с аналогичным или меньшим числом параметров.

Демо: https://huggingface.co/spaces/deepseek-ai/deepseek-vl2-small

Список функций
- Визуальные вопросы и ответы: Поддерживает сложные задания визуальных викторин, предоставляя точные ответы.
- Оптическое распознавание символов (OCR)Эффективное распознавание текстового содержимого на изображениях.
- Понимание документов: Разбор и понимание сложной структуры и содержания документов.
- Понимание формы: Идентификация и обработка табличных данных для извлечения полезной информации.
- Графическое пониманиеАнализировать и интерпретировать данные и тенденции на графиках и диаграммах.
- визуальная ориентация: Точное определение местоположения целевого объекта на изображении.
- Поддержка нескольких вариантовДля удовлетворения различных потребностей предлагаются модели Tiny, Small и Standard.
- Высокая производительность: Сокращение количества параметров активации при сохранении высокой производительности.
Использование помощи
Процесс установки
- Убедитесь, что версия Python >= 3.8.
- Клонирование репозитория DeepSeek-VL2:
git clone https://github.com/deepseek-ai/DeepSeek-VL2.git
- Перейдите в каталог проекта и установите необходимые зависимости:
cd DeepSeek-VL2
pip install -e .
Пример использования
Пример простого рассуждения
Ниже приведен пример кода для простого вывода с помощью DeepSeek-VL2:
import torch
from transformers import AutoModelForCausalLM
from deepseek_vl2.models import DeepseekVLV2Processor, DeepseekVLV2ForCausalLM
from deepseek_vl2.utils.io import load_pil_images
# 指定模型路径
model_path = "deepseek-ai/deepseek-vl2-tiny"
vl_chat_processor = DeepseekVLV2Processor.from_pretrained(model_path)
vl_model = DeepseekVLV2ForCausalLM.from_pretrained(model_path)
# 加载图像
images = load_pil_images(["path_to_image.jpg"])
# 推理
inputs = vl_chat_processor(images=images, return_tensors="pt")
outputs = vl_model.generate(**inputs)
print(outputs)
Подробный порядок работы функций
- Визуальные вопросы и ответы::
- Модели загрузки и процессоры.
- Введите изображение и вопрос, и модель выдаст ответ.
- Оптическое распознавание символов (OCR)::
- пользоваться
DeepseekVLV2ProcessorЗагрузить изображение. - Модель вызывается для вывода, чтобы извлечь текст из изображения.
- пользоваться
- Понимание документов::
- Загружает входные данные, содержащие изображение документа.
- Модель разбирает структуру документа и возвращает результат разбора.
- Понимание формы::
- Введите изображение, содержащее форму.
- Модель распознает структуру и содержание формы и извлекает ключевую информацию.
- Графическое понимание::
- Загрузите изображение графика.
- Модель анализирует графические данные, обеспечивая интерпретацию и анализ тенденций.
- визуальная ориентация::
- Введите описание и изображение целевого объекта.
- Модель определяет местоположение целевого объекта на изображении и возвращает координаты его положения.
Выполнив описанные выше действия, пользователи смогут в полной мере использовать возможности DeepSeek-VL2 для выполнения различных сложных задач, связанных с визуальным языком.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...