DeepSeek-R1-FP4: оптимизированная под FP4 версия вывода DeepSeek-R1 работает в 25 раз быстрее

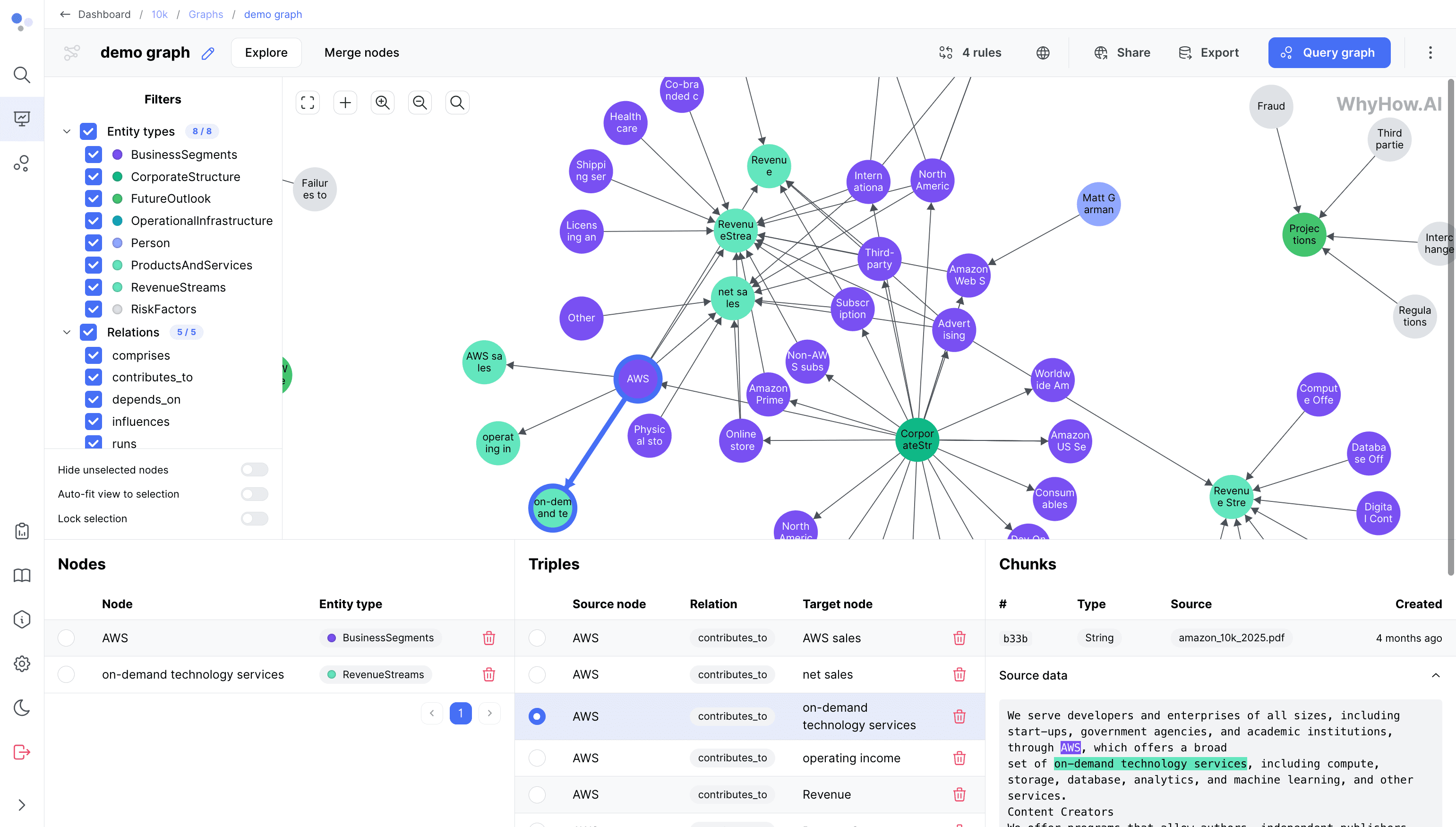
Общее введение
DeepSeek-R1-FP4 - это квантифицированная языковая модель, открытая и оптимизированная NVIDIA на основе DeepSeek искусственный интеллект DeepSeek-R1 Разработка. Она квантует веса и значения активации в типы данных FP4 с помощью оптимизатора моделей TensorRT, что позволяет значительно снизить требования к ресурсам модели при сохранении высокой производительности. Занимая примерно в 1,6 раза меньше дискового пространства и памяти GPU по сравнению с оригинальной моделью, она идеально подходит для эффективного вычисления в производственных средах. Оптимизированная специально для архитектуры NVIDIA Blackwell, модель, как утверждается, обеспечивает 25-кратное ускорение вычислений на жетон Он в 20 раз дешевле и демонстрирует высокий потенциал производительности. Благодаря поддержке контекста длиной до 128 Кбайт он подходит для обработки сложных текстовых задач и открыт как для коммерческого, так и для некоммерческого использования, предоставляя разработчикам экономически эффективное решение для ИИ.

Список функций
- Эффективное рассуждение: Значительное повышение скорости вычислений и оптимизация использования ресурсов с помощью квантования FP4.
- Длительная поддержка контекста: Поддерживает максимальную длину контекста 128K, что подходит для обработки задач генерации длинных текстов.
- Развертывание TensorRT-LLM: Может быть быстро развернут для работы на графических процессорах NVIDIA с помощью фреймворка TensorRT-LLM.
- использование открытого исходного кода:: Поддержка коммерческих и некоммерческих сценариев, позволяющих свободно модифицировать и развивать производные.
- оптимизация производительности: Разработанный для архитектуры Blackwell, он обеспечивает сверхвысокую эффективность вывода и экономическую эффективность.
Использование помощи
Процесс установки и развертывания
Для развертывания DeepSeek-R1-FP4 требуется определенная поддержка аппаратного и программного окружения, особенно NVIDIA GPU и фреймворка TensorRT-LLM. Ниже представлено подробное руководство по установке и использованию, которое поможет пользователям быстро начать работу.
1. Подготовка окружающей среды
- требования к оборудованию: Рекомендуется использовать графические процессоры архитектуры NVIDIA Blackwell (например, B200), для чего требуется не менее 8 GPU (каждый с ~336 ГБ VRAM без квантования, ~1342 ГБ после квантования для соответствия требованиям модели). Для небольших тестов рекомендуется использовать как минимум 1 высокопроизводительный GPU (например, A100/H100).
- зависимость от программного обеспечения:
- Операционная система: Linux (например, Ubuntu 20.04 или более поздняя версия).
- Драйвер NVIDIA: последняя версия (поддерживает CUDA 12.4 или выше).
- TensorRT-LLM: последняя версия мастер-ветки должна быть скомпилирована из исходных текстов на GitHub.
- Python: 3.11 или более поздняя версия.
- Другие библиотеки:
tensorrt_llm, иtorchи т.д.
2. Загрузить модель
- интервью Страница с обнимающимися лицамиПерейдите на вкладку "Файлы и версии".
- Загрузите файл модели (например.
model-00001-of-00080.safetensors(и т.д., всего 80 фрагментов общим объемом более 400 ГБ). - Сохраните файл в локальном каталоге, например
/path/to/model/.
3. Установка TensorRT-LLM
- Клонируйте последнюю версию репозитория TensorRT-LLM с GitHub:
git clone https://github.com/NVIDIA/TensorRT-LLM.git cd TensorRT-LLM
- Скомпилируйте и установите:
make build pip install -r requirements.txt - Проверьте установку:
python -c "import tensorrt_llm; print(tensorrt_llm.__version__)"
4. модель развертывания
- Загрузите и запустите модель, используя предоставленный код примера:
from tensorrt_llm import SamplingParams, LLM # 初始化模型 llm = LLM( model="/path/to/model/nvidia/DeepSeek-R1-FP4", tensor_parallel_size=8, # 根据 GPU 数量调整 enable_attention_dp=True ) # 设置采样参数 sampling_params = SamplingParams(max_tokens=32) # 输入提示 prompts = [ "你好,我的名字是", "美国总统是", "法国的首都是", "AI的未来是" ] # 生成输出 outputs = llm.generate(prompts, sampling_params) for output in outputs: print(output) - Перед выполнением приведенного выше кода убедитесь, что ресурсы GPU были выделены правильно. Если ресурсов недостаточно, настройте параметр
tensor_parallel_sizeПараметры.
5. руководство по функциональной эксплуатации
Эффективное рассуждение
- Основным преимуществом DeepSeek-R1-FP4 является технология квантования FP4. Вместо того чтобы вручную настраивать параметры модели, пользователи могут просто убедиться, что их оборудование поддерживает архитектуру Blackwell, и ощутить увеличение скорости вычислений. Во время выполнения рекомендуется установить
max_tokensПараметр управляет длиной вывода, чтобы не тратить ресурсы впустую. - Пример того, как это сделать: запустите скрипт Python в терминале, вводите различные запросы и наблюдайте за скоростью и качеством вывода.
длительная обработка контекста
- Модель поддерживает длину контекста до 128K, что подходит для создания длинных статей или обработки сложных диалогов.
- Операция: В
promptsВведите длинный контекст, например начало статьи из 5 000 слов, а затем установитеmax_tokens=1000Текст генерируется так же, как и последующий. Проверьте связность сгенерированного текста после выполнения. - Предупреждение: длинные контексты могут увеличивать потребление памяти, поэтому рекомендуется следить за использованием памяти GPU.
оптимизация производительности
- Если вы используете графические процессоры Blackwell, вы можете получить прямой выигрыш в 25-кратном ускорении вычислений. При использовании других архитектур (например, A100) прирост производительности может быть немного ниже, но все равно значительно лучше, чем у неквантованной модели.
- Рекомендации по эксплуатации: В среде с несколькими графическими процессорами настройте
tensor_parallel_sizeпараметры для полного использования аппаратных ресурсов. Например, для 8 GPU устанавливается значение 8, а для 4 GPU - значение 4.
6. часто задаваемые вопросы и решения
- Недостаточно видеопамяти: Если появится сообщение о переполнении памяти, уменьшите
tensor_parallel_sizeили использовать менее квантованную версию (например, формат GGUF, предложенный сообществом). - Медленное рассуждение: Убедитесь, что TensorRT-LLM скомпилирован правильно и включено ускорение GPU, проверьте соответствие версии драйвера.
- аномалия на выходе: Проверьте формат запроса ввода, чтобы убедиться, что никакие специальные символы не мешают работе с моделью.
Рекомендации по использованию
- первоначальное использование: Начните с простых подсказок и постепенно увеличивайте длину контекста, чтобы ознакомиться с работой модели.
- производственная среда: Перед развертыванием протестируйте несколько наборов подсказок, чтобы убедиться, что результат соответствует ожиданиям. Рекомендуется оптимизировать многопользовательский доступ с помощью средств балансировки нагрузки.
- Персонализация разработчика:: Модели могут быть модифицированы на основе лицензий с открытым исходным кодом для решения конкретных задач, таких как генерация кода или системы вопросов и ответов.
Выполнив эти действия, пользователи смогут быстро развернуть и использовать DeepSeek-R1-FP4, чтобы насладиться удобством эффективных выводов.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...