DeepSeek-OCR - модель оптического распознавания символов с открытым исходным кодом DeepSeek

Что такое DeepSeek-OCR?
DeepSeek-OCR - это DeepSeek Разработанная командой с открытым исходным кодом передовая модель оптического распознавания символов (OCR) преобразует текст в изображения с помощью технологии "контекстуального оптического сжатия", которая использует визуальные жетон Он способен сжимать и декодировать текст для эффективной обработки длинных текстов. Его технические особенности включают высокую степень сжатия (точность до 97% при 10-кратном сжатии), совместное понимание языка и зрения, поддержку нескольких структур и форматов (JPG, PNG, PDF и т. д. и распознавание нескольких языков), сквозную архитектуру VLM и т. д. Он может использоваться в широком диапазоне сценариев применения, включая длинные тексты, сложные документы и многоязыковое развертывание. Широкий спектр сценариев применения, работа с длинными текстами, сложными документами, поддержка нескольких языков, локализованное развертывание. Он обладает значительными преимуществами в плане производительности, такими как высокая эффективность (одна видеокарта A100-40G позволяет генерировать более 200 000 страниц обучающих данных в день), низкая задержка (распознавание в реальном времени со скоростью 15 кадров в секунду на мобильных устройствах, задержка составляет менее 100 миллисекунд) и высокая адаптивность (точность распознавания до 98,7% в сложных сценариях). Для удобства разработчиков выпущен открытый исходный код и весовые коэффициенты модели.
Особенности DeepSeek-OCR
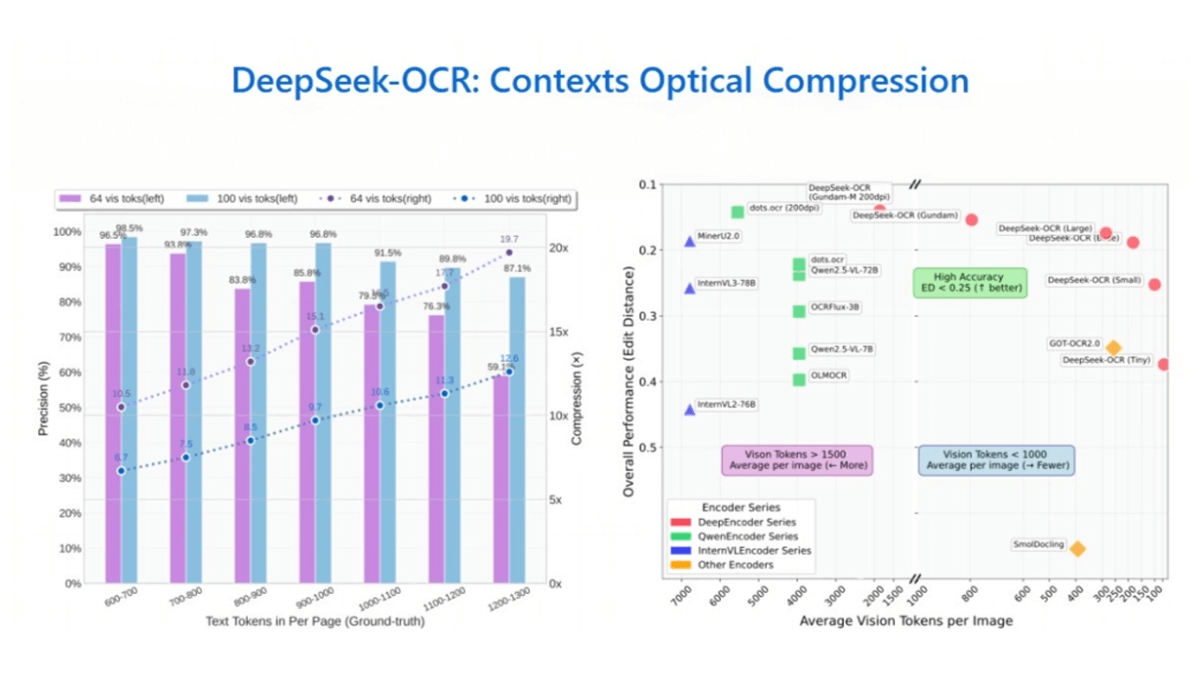
- Контекстное оптическое сжатие: Преобразование текста в изображение, сжатие и декодирование по визуальным маркерам для эффективной обработки длинных текстов с точностью до 97% при 10-кратном сжатии.
- Совместное визуально-вербальное понимание: Сочетание визуальной информации в изображениях со способностью понимать языковые модели для точного понимания семантики и структуры текста.
- Поддержка нескольких структур, нескольких форматовОн поддерживает широкий спектр форматов изображений (JPG, PNG, PDF) и распознавание нескольких языков, а также отлично справляется с рукописным текстом, смешанным текстом и документами, содержащими графики и текст.
- Высокая степень сжатия и высокая точность: При сжатии в 10 раз точность OCR достигает 97%; даже при увеличении степени сжатия до 20 раз точность модели остается на уровне около 60%.
- Конечная архитектура VLMИспользуются кодер DeepEncoder и декодер DeepSeek3B-MoE, причем кодер отвечает за извлечение особенностей изображения, токенизацию и сжатие визуального представления, а декодер генерирует необходимые результаты на основе токенов и подсказок изображения.
- Широкий спектр сценариев примененияНиже перечислены некоторые особенности новейшей версии TP3T: она может "выстрелить" документ из тысяч слов в одну диаграмму, достигая точного сокращения 97% менее чем за одну десятую стоимости и обеспечивая эффективное решение проблемы длинных контекстов в больших языковых моделях; она может распознавать информацию в тексте, графики и диаграммы в таблицах или финансовых отчетах, и даже может читать химические молекулярные формулы, математические формулы и геометрические фигуры, поддерживает более 100 языков, включая китайский и английский; поддерживает локальное развертывание, что позволяет избежать отправки конфиденциальных документов в сторонние облачные сервисы.
- Значительные преимущества в производительностиОдна графическая карта A100-40G может поддерживать генерацию более 200 000 страниц данных обучения большой языковой модели/визуальной языковой модели в день; распознавание в реальном времени со скоростью 15 кадров в секунду и задержкой менее 100 миллисекунд может быть достигнуто на мобильных устройствах; благодаря многомасштабному модулю динамического слияния признаков и декодеру с учетом контекста точность распознавания модели в сложных сценах достигает 98,7%, что на 6,4 процентных пункта выше, чем в среднем по отрасли. На 6,4 процентных пункта выше, чем в среднем по отрасли.
Основные преимущества DeepSeek-OCR
- Эффективное контекстное оптическое сжатиеВ качестве примера можно привести следующее: благодаря преобразованию текста в изображения и использованию визуальных маркеров для сжатия и декодирования, достигается высокая степень сжатия при сохранении высокой точности: точность до 97% при 10-кратном сжатии и около 60% при 20-кратном сжатии, что эффективно решает проблему обработки длинных текстов.
- Глубокое слияние видения и языкаСочетание визуальной информации в изображении (например, расположение, макет, графика, границы таблицы) и понимания языковых моделей позволяет не только распознавать текстовое содержание, но и точно улавливать семантику и структуру макета для улучшения обработки сложных документов.
- Широкая поддержка форматов и языковОн поддерживает широкий спектр форматов изображений (JPG, PNG, PDF) и более 100 языков, а также работает с рукописным текстом, смешанным текстом и документами, содержащими графики и текст, что позволяет использовать его в самых разных сценариях.
- Мощная производительностьОдна видеокарта A100-40G способна обеспечить генерацию более 200 000 страниц данных для обучения большой языковой модели в день; распознавание в реальном времени со скоростью 15 кадров в секунду на мобильных устройствах, с задержкой менее 100 миллисекунд; точность распознавания до 98,71 TP3T в сложных сценах, что значительно выше среднего показателя по отрасли.
- Гибкое развертываниеОна поддерживает локальное развертывание, что позволяет избежать отправки конфиденциальных документов в сторонние облачные службы, обеспечить безопасность данных и удовлетворить потребности различных пользователей в средах развертывания.
Какой официальный сайт DeepSeek-OCR?
- Репозиторий GitHub:: https://github.com/deepseek-ai/DeepSeek-OCR
- Библиотека моделей HuggingFace:: https://huggingface.co/deepseek-ai/DeepSeek-OCR
- Технические документы:: https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
Для кого предназначен DeepSeek-OCR?
- бизнес-пользовательЕму необходимо работать с большим количеством документов, таких как финансовые отчеты, контракты, техническая документация и т. д. Он может повысить эффективность работы и снизить трудозатраты благодаря эффективным возможностям обработки длинных текстов и распознавания сложных документов.
- (научный) исследовательПоддержка нескольких языков и точные возможности распознавания DeepSeek-OCR могут помочь в академических исследованиях, где часто приходится работать со сложным контентом, таким как многоязычные документы, графики и формулы.
- педагог: Для организации и оцифровки учебных материалов, таких как подготовка учебных программ, анализ контрольных работ и т.д. Функции распознавания рукописного текста и поддержки нескольких форматов могут удовлетворить потребности преподавания.
- разработчик: Открытый исходный код и модельные веса позволяют разработчикам интегрировать их в собственные проекты, создавать специализированные OCR-приложения и расширять сценарии их применения.
- индивидуальный пользовательDeepSeek-OCR - это удобное и эффективное решение для извлечения содержимого документов, систематизации заметок, перевода материалов на иностранные языки и других сценариев, позволяющих повысить эффективность работы в офисе и учебе.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...