DeepOCR - проект реплики с открытым исходным кодом, основанный на модели DeepSeek-OCR

Что такое DeepOCR
DeepOCR - это проект репликации с открытым исходным кодом, который реализует DeepSeek-OCR Основная архитектура системы эффективно обрабатывает текстовую информацию с помощью технологий оптического сжатия. Ядром является DeepEncoder, который состоит из SAM-базы (для обработки изображений высокого разрешения), 16× сверточного компрессора (для уменьшения жетон DeepOCR использует двухэтапный процесс обучения: на первом этапе используется набор данных LLaVA-CC3M для визуально-лингвистического выравнивания. Такая конструкция значительно сокращает память активации и количество токенов, сохраняя при этом высокую вычислительную мощность.DeepOCR использует двухэтапный процесс обучения: на первом этапе используется набор данных LLaVA-CC3M для обучения визуально-лингвистическому выравниванию; на втором этапе используется набор данных LLaVA-CC3M для обучения визуально-лингвистическому выравниванию. olmOCR На наборе данных проводится предварительное обучение, специфичное для OCR. При таком подходе к обучению DeepOCR демонстрирует хорошие результаты в бенчмарках OmniDocBench и olmOCR, особенно в задачах распознавания английского текста и разбора таблиц, подтверждая эффективность оптической компрессии.
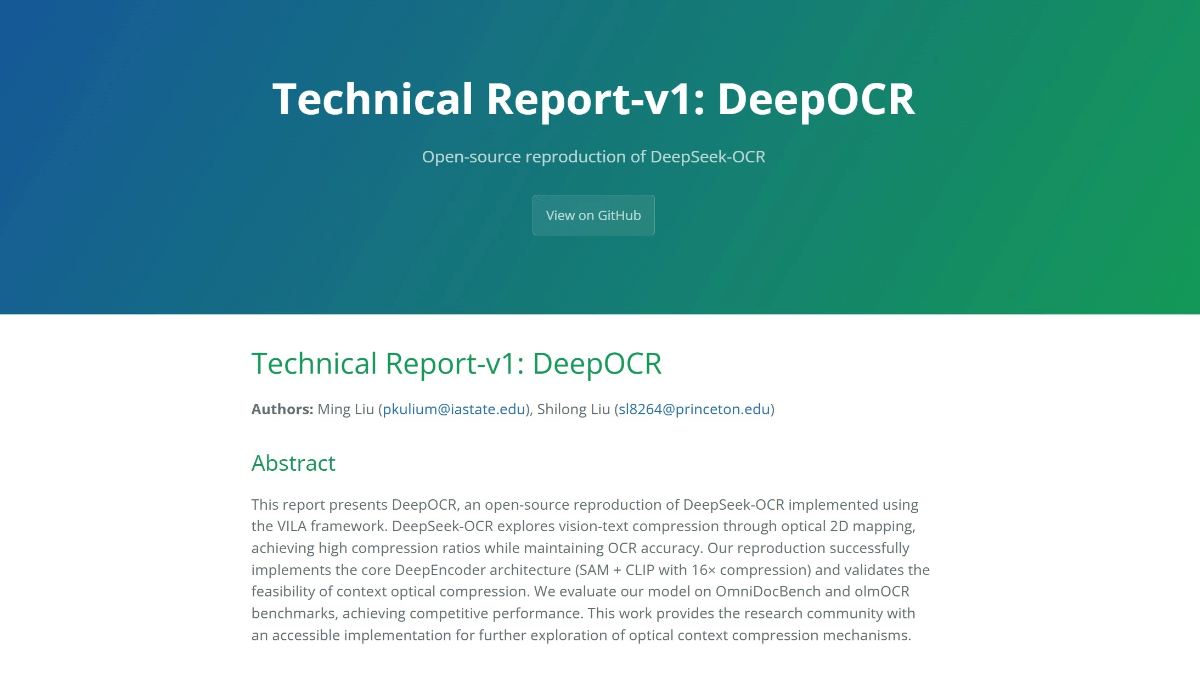
Особенности DeepOCR
- оптическое сжатие: Эффективное сжатие текстовой информации путем преобразования ее в изображение и обработки визуальными кодерами, такими как SAM и CLIP, со степенью сжатия до 7-20 раз.
- Обработка с высоким разрешениемПоддержка входных изображений с разрешением 1024×1024 и выше, а также эффективное управление памятью активации благодаря механизму оконного внимания и технологии конволюционного сжатия.
- мультимодальное слияние: Локальные признаки SAM и глобальные семантические признаки CLIP объединяются для получения 2048-мерных признаков, которые предоставляют богатую информацию для последующих задач.
- Двухэтапное обучениеНа первом этапе модель обучается визуально-лингвистическому выравниванию, а на втором - предварительно тренируется для задач OCR, чтобы убедиться, что модель хорошо справляется с задачами распознавания текста и разбора документов.
- с низким уровнем вычислительной мощности: Заморозка DeepEncoder (SAM + CLIP) значительно снижает потребность в графической памяти, позволяя модели завершить обучение на ограниченных ресурсах GPU (например, 2×H200).
- реализация с открытым исходным кодом: Полностью открытый исходный код на основе фреймворка VILA, предоставляющий исследовательскому сообществу доступную платформу для изучения механизмов сжатия оптического контекста.
- бенчмаркинг: Производительность модели подтверждена в бенчмарках OmniDocBench и olmOCR, и она особенно хорошо справляется с задачами распознавания английского текста и разбора таблиц.
Основные преимущества DeepOCR
- Эффективное сжатие::Оптическое сжатие, при котором текст представляется в виде изображения и обрабатывается с помощью визуального кодировщика, значительно сокращает количество текстовых лексем в 7-20 раз. Это делает модель более эффективной при обработке длинных текстов и снижает требования к вычислительным ресурсам.
- Возможность обработки данных с высоким разрешением::Он поддерживает входные данные с высоким разрешением (например, 1024×1024) и эффективно управляет памятью активации, чтобы избежать взрыва памяти, благодаря механизму оконного внимания (SAM) и методам сверточного сжатия. Это позволяет DeepOCR обрабатывать сложные макеты документов и изображения высокого разрешения.
- мультимодальное слияние::Локальные особенности SAM объединяются с глобальными семантическими особенностями CLIP для создания 2048-мерных богатых особенностей. Такое мультимодальное слияние обеспечивает более полную информацию для последующих задач и повышает производительность модели.
- с низким уровнем вычислительной мощности::В процессе обучения DeepEncoder (SAM + CLIP) замораживается, что значительно снижает потребность в графической памяти. Это позволяет модели завершить обучение на ограниченных ресурсах GPU (например, 2×H200), снижая аппаратный порог и делая ее подходящей для малых и средних команд.
Что такое официальный сайт DeepOCR
- Веб-сайт проекта:: https://pkulium.github.io/DeepOCR_website/
- Репозиторий Github:: https://github.com/pkulium/DeepOCR
Для кого предназначен DeepOCR
- Разработчики в области обработки документов и OCR::Длинные тексты и сложные макеты документов требуют эффективной обработки, и возможности оптического сжатия и обработки с высоким разрешением DeepOCR позволяют значительно повысить эффективность разбора документов.
- Малые и средние команды и независимые разработчики::Низкая вычислительная мощность DeepOCR делает его пригодным для работы на ограниченных аппаратных ресурсах, что снижает порог разработки.
- Участники сообщества с открытым исходным кодом::Члены сообщества с открытым исходным кодом могут участвовать в создании кода, улучшений и расширений для развития технологии.
- Академические исследователи, заинтересованные в инновационных технологиях::Мы надеемся найти применение оптической компрессии в различных областях, таких как понимание изображений и обнаружение элементов пользовательского интерфейса.
- Предприятия и организации, нуждающиеся в эффективной обработке текста::Возможности DeepOCR по эффективному сжатию и обработке данных можно использовать для оптимизации внутренней обработки документов и повышения эффективности работы.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...