Рассуждения на основе больших языковых моделей: баланс между "недодуманностью" и "передуманностью"

Большие языковые модели (LLM) быстро развиваются, и их способность к рассуждениям стала ключевым показателем уровня интеллекта. В частности, модели с большими возможностями рассуждений, такие как OpenAI o1, иDeepSeek-R1, иQwQ-32B ответить пением Kimi K1.5 Они привлекли большое внимание благодаря своей способности решать сложные задачи, имитируя глубокие мыслительные процессы человека. Эта способность часто включает в себя технику, называемую масштабированием времени вывода, которая позволяет модели тратить больше времени на исследование и исправление в процессе генерации ответов.
Однако при более глубоком рассмотрении оказывается, что эти модели часто впадают в две крайности, когда дело доходит до рассуждений:Недоумевая ответить пением Переосмысление.
недостаточно пищи для размышлений Это относится к частой смене идей в рассуждениях модели, что затрудняет фокусировку на перспективном направлении для более глубокого изучения. Вывод модели может быть наполнен такими словами, как "альтернатива", "но подождите", "позвольте мне пересмотреть" и т. д., что как показано на рисунке ниже, что приводит к неправильным окончательным ответам. Это явление можно сравнить с человеческой невнимательностью, которая влияет на правильность рассуждений.

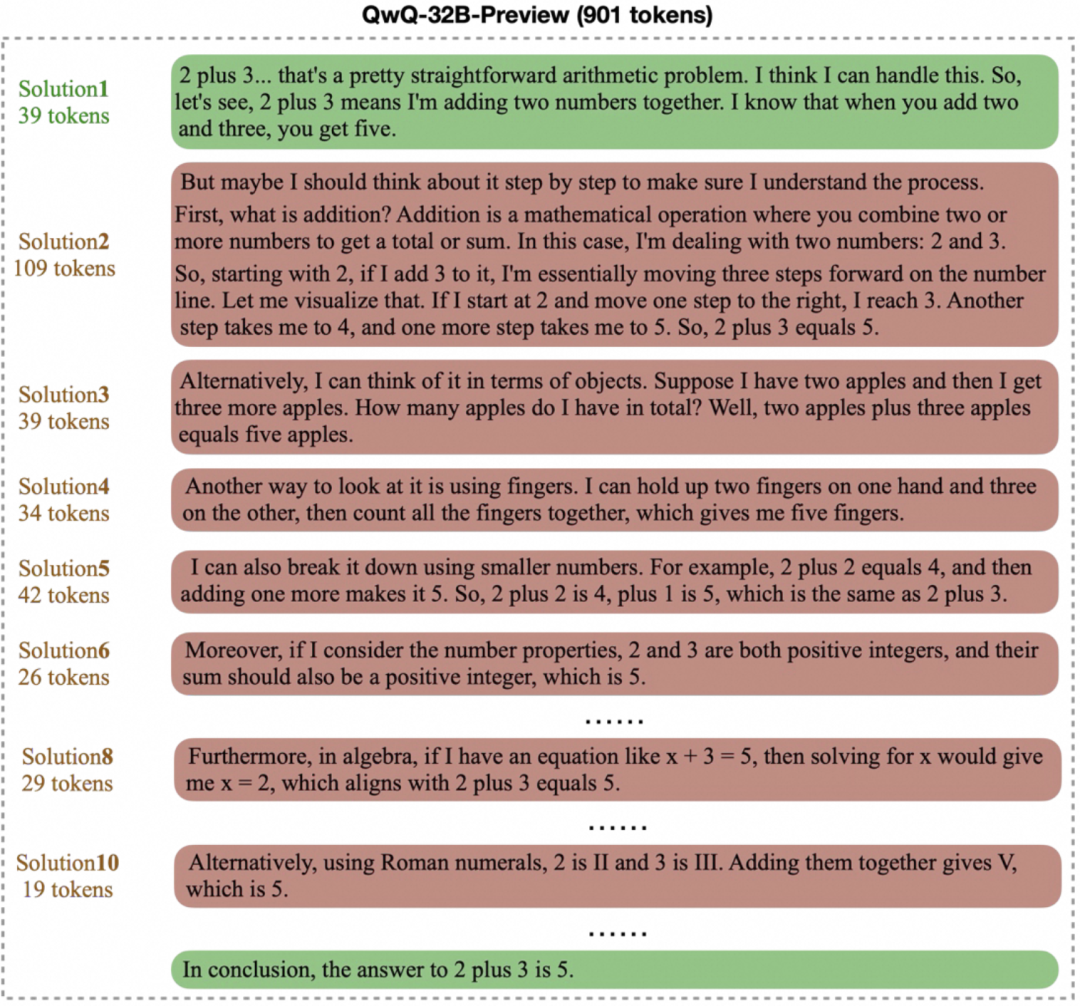
переосмысление Вместо этого модель порождает длинные и ненужные "цепочки размышлений" над простыми задачами. Например, для решения базовой арифметической задачи типа "2+3=?" Например, для решения базовой арифметической задачи типа "2+3=?" некоторые модели могут потребовать сотни или даже тысячи часов работы. token чтобы итеративно проверить или исследовать несколько решений, как показано ниже. Хотя сложные мыслительные процессы полезны для решения сложных задач, в простых сценариях это, безусловно, приводит к пустой трате вычислительных ресурсов.
Вместе эти два вопроса указывают на главную проблему: как повысить эффективность мышления модели, сохранив при этом качество ответов? Идеальная модель должна уметь находить и давать правильный ответ за минимальное время.
Чтобы решить эту проблему.EvalScope Проект представляет EvalThink компонент, цель которого - предоставить стандартизированный инструмент для оценки эффективности мышления модели. В данной работе мы будем использовать MATH-500 В качестве примера можно привести анализ набора данных, включающий DeepSeek-R1-Distill-Qwen-7B Производительность ряда моделей рассуждений, включая те, которые сосредоточены на шести измерениях: рассуждение по модели token Номер, первый раз правильно token Количество, оставшиеся отражения token Номера,token Эффективность, количество цепочек субмышления и точность.
Методология и процесс оценки
Процесс оценки состоит из двух основных этапов: оценка обоснованности модели и оценка эффективности модельного мышления.
Оценка обоснованности модели
Цель этого этапа - получить модель в MATH-500 Необработанные результаты умозаключений и базовая точность по набору данных.MATH-500 Набор данных содержит 500 математических задач разной сложности (от 1 до 5 уровня).
Подготовка среды для оценки
Оценка может быть выполнена путем обращения к совместимому с OpenAI API сервису рассуждений.EvalScope Система также поддерживает использование transformers Библиотека просматривается на месте. Для тех, кому необходимо работать с длинными цепочками мыслей (возможно, более 10 000 token) модели вывода с использованием vLLM возможно ollama Эффективные системы вывода, такие как эти, развертывают модели, которые могут значительно ускорить процесс оценки.
согласно DeepSeek-R1-Distill-Qwen-7B В качестве примера можно использовать vLLM Пример команды для развертывания службы выглядит следующим образом:
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --served-model-name DeepSeek-R1-Distill-Qwen-7B --trust_remote_code --port 8801
Обзор исполнительной аргументации
пройти (законопроект, проверку и т.д.) EvalScope (используется в форме номинального выражения) TaskConfig Настройте адрес API модели, имя, набор данных, размер партии и параметры генерации, а затем запустите задачу оценки. Ниже приведен пример кода на языке Python:
from evalscope import TaskConfig, run_task
task_config = TaskConfig(
api_url='http://0.0.0.0:8801/v1/chat/completions', # 推理服务地址
model='DeepSeek-R1-Distill-Qwen-7B', # 模型名称 (需与部署时一致)
eval_type='service', # 评测类型:服务
datasets=['math_500'], # 数据集
dataset_args={'math_500': {'few_shot_num': 0, 'subset_list': ['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5']}}, # 数据集参数,包含难度级别
eval_batch_size=32, # 并发请求数
generation_config={
'max_tokens': 20000, # 最大生成 token 数,设置较大值防截断
'temperature': 0.6, # 采样温度
'top_p': 0.95, # top-p 采样
'n': 1, # 每个请求生成一个回复
},
)
run_task(task_config)
После завершения оценки модель будет экспортирована в формате MATH-500 Точность на каждом уровне сложности (AveragePass@1):
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|-----------------------------|-----------|---------------|----------|-----|--------|---------|
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 1 | 43 | 0.9535 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 2 | 90 | 0.9667 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 3 | 105 | 0.9587 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 4 | 128 | 0.9115 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 5 | 134 | 0.8557 | default |
Оценка эффективности модельного мышления
После получения заключенияEvalThink Компонентные вмешательства для более глубокого анализа эффективности. Основные показатели оценки включают:
- моделируемое рассуждение
token(Токены рассуждений): Цепочки мышления во время создания модели ответов (как в модели O1/R1)</think>(то, что предшествует флагу), содержащийся вtokenОбщая сумма. - правильно с первого раза
tokenКоличество (первые правильные жетоны): От начала вывода модели до первого появления идентифицируемого места правильного ответаtokenКоличество. - Оставшиеся размышления
tokenКоличество (жетоны отражения):: От первой позиции правильного ответа до конца цепочки размышленийtokenКоличество. Это частично отражает стоимость продолжения проверки или исследования после того, как модель нашла ответ. - Мысль Num:: Подсчитывая конкретные знаки (напр.
alternatively,but wait,let me reconsider), чтобы оценить, как часто модель меняет идеи. tokenЭффективность жетонов:: Измерение эффективности мышленияtokenПоказатель в процентах, рассчитывается как правильное решение с первого разаtokenЧисла и общее мышлениеtokenСреднее значение отношения количества (учитывались только образцы с правильными ответами):
Эффективность жетонов = 1⁄N ∑ Первый правильный Жетоныi⁄Рассуждения Токенси
где N - количество правильно отвеченных вопросов. Чем выше значение, тем более "эффективным" является мышление модели.
Для целей определения "права первого раза token Число" - система оценки, которая опирается на ProcessBench Идея состоит в том, чтобы использовать отдельную модель судьи, например Qwen2.5-72B-Instructдля проверки шагов умозаключения и нахождения позиции, где правильный ответ возникает раньше всего. Реализация предполагает декомпозицию вывода модели на шаги (стратегия опциональна: по конкретному разделителю) separatorКлючевые слова для прессы keywordsили переписаны и нарезаны с помощью LLM. llm), а затем пусть судья-модель оценит каждую из них.
Образец кода для выполнения оценки эффективности мышления:
from evalscope.third_party.thinkbench import run_task
# 配置裁判模型服务
judge_config = dict(
api_key='EMPTY',
base_url='http://0.0.0.0:8801/v1', # 假设裁判模型也部署在此服务
model_name='Qwen2.5-72B-Instruct',
)
# 配置待评估模型的信息
model_config = dict(
report_path='./outputs/2025xxxx', # 上一步推理结果路径
model_name='DeepSeek-R1-Distill-Qwen-7B', # 模型名称
tokenizer_path='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', # Tokenizer 路径,用于计算 token
dataset_name='math_500', # 数据集名称
subsets=['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5'], # 数据集子集
split_strategies='separator', # 推理步骤分割策略
judge_config=judge_config
)
max_tokens = 20000 # 过滤 token 过长的输出
count = 200 # 每个子集抽样数量,加速评测
# 运行思考效率评估
run_task(model_config, output_dir='outputs', max_tokens=max_tokens, count=count)
В результатах оценки будут подробно описаны шестимерные показатели модели на каждом уровне сложности.
Анализ и обсуждение результатов
Исследовательская группа использовала EvalThink справа DeepSeek-R1-Distill-Qwen-7B и несколько других моделей (QwQ-32B, иQwQ-32B-Preview, иDeepSeek-R1, иDeepSeek-R1-Distill-Qwen-32B) была оценена и добавлена специализированная неинферентная математическая модель Qwen2.5-Math-7B-Instruct Для сравнения.
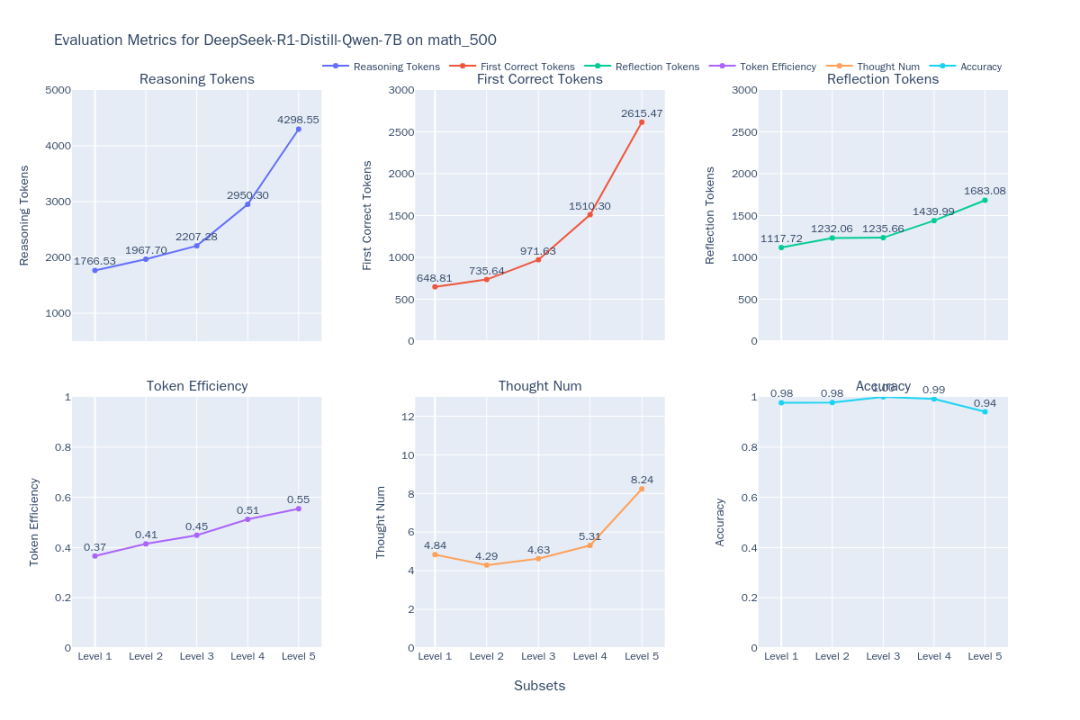
Рисунок 1: Показатель эффективности мышления DeepSeek-R1-Distill-Qwen-7B
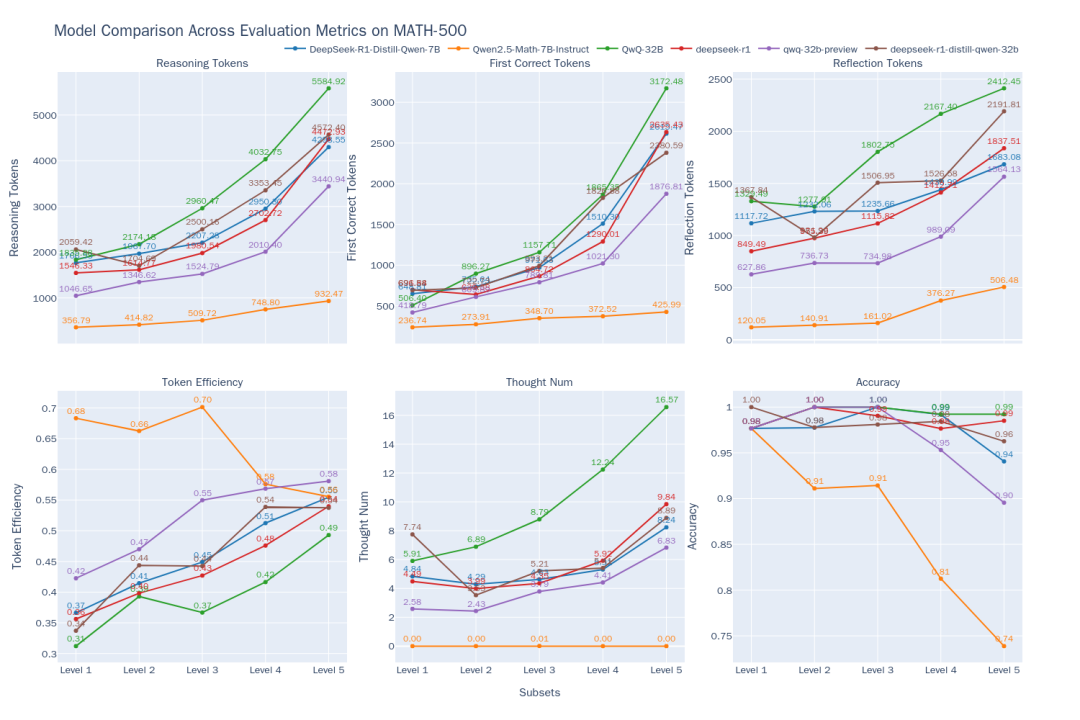
Рисунок 2: Сравнение эффективности мышления 6 моделей на разных уровнях сложности MATH-500
По результатам сравнения (рис. 2) можно проследить следующие тенденции:
- Корреляция между сложностью и производительностью: По мере увеличения сложности задачи (от уровня 1 до уровня 5) точность большинства моделей снижается. Однако.
QwQ-32Bответить пениемDeepSeek-R1отлично справляясь с трудными задачами.QwQ-32BНаибольшая точность на уровне 5. В то же время выход всех моделейtokenЧисла становятся все длиннее по мере увеличения сложности, что соответствует ожиданию "рассуждения при расширении" - модели нужно больше "думать", чтобы решить головоломку. - Свойства модели рассуждений класса O1/R1:
- Повышение эффективности:: Интересно, что для
DeepSeek-R1ответить пениемQwQ-32BВ этом типе модели вывода, хотя вывод и становится длиннее, ноtokenЭффективность (эффективный)tokenпроцент) также увеличивается с ростом сложности (DeepSeek-R1От 36% до 54%.QwQ-32B(с 31% до 49%). Это говорит о том, что их дополнительное мышление при решении сложных задач более "экономично", в то время как при решении простых задач может быть определенное количество "избыточного мышления", например, ненужная итеративная проверка.QwQ-32B(используется в форме номинального выражения)tokenПотребление в целом высокое, что может быть одной из причин, почему он может поддерживать высокий уровень точности на 5-м уровне, но это также намекает на склонность к чрезмерному размышлению. - Пути мысли:
DeepSeekКоличество цепочек субмышления для моделей серии относительно стабильно на уровнях 1-4, но резко возрастает на самом сложном уровне 5, что говорит о том, что уровень 5 представляет собой серьезный вызов для этих моделей и требует многократных попыток. В отличие от этого.QwQ-32BСерийная модель характеризуется более плавным ростом числа цепочек размышлений, что отражает различные стратегии преодоления.
- Повышение эффективности:: Интересно, что для
- Ограничения неинферентных моделей:: Математические специализированные модели
Qwen2.5-Math-7B-InstructТочность резко падает при решении сложных задач, а его производительностьtokenЭто число гораздо меньше, чем для моделей рассуждений (около трети). Это говорит о том, что, хотя такие модели могут быть быстрее и менее ресурсоемкими при решении обычных задач, отсутствие более глубоких мыслительных процессов дает им значительный "потолок" производительности при решении сложных задач рассуждения.
Методологические соображения и ограничения
в применении EvalThink При проведении оценки необходимо учитывать несколько моментов:
- Определение показателей:
- предложенные в данной работе
tokenПоказатели эффективности, опираясь на существующие в литературе понятия "переосмысление" и "недоосмысление", ориентированы в первую очередь наtokenКоличество, являясь упрощенным показателем процесса мышления, не может передать все детали качества мышления. - Подсчет количества цепочек субмышления опирается на заранее определенные ключевые слова, и список ключевых слов может потребовать корректировки для разных моделей, чтобы точно отразить их модели мышления.
- предложенные в данной работе
- Область применения:
- Текущие метрики в основном проверены на наборах данных по математическим рассуждениям, и их эффективность в других сценариях, таких как открытые викторины и генерация идей, еще предстоит проверить.
- кейтер
DeepSeek-R1-Distill-Qwen-7Bоснована на математической модели дистилляцииMATH-500Возможно, существует естественное преимущество в производительности на наборе данных. Результаты оценки необходимо интерпретировать в контексте модели.
- Зависимость от модели судебного разбирательства:
tokenВычисление эффективности опирается на модель судьи (JM), позволяющую точно оценить правильность шагов рассуждения. КакProcessBench4Как отмечается в исследовании, это сложная задача для существующих моделей, и обычно для ее решения требуются модели с высокими возможностями.- Ошибки в модели судейства могут оказать непосредственное влияние на
tokenточность показателей эффективности, поэтому выбор правильной модели рефери очень важен.
В двух словах.EvalThink Представлен набор фреймворков и метрик для количественной оценки эффективности LLM-мышления, показывающий, насколько хорошо различные модели работают с точки зрения точности,token компромисс между потреблением и глубиной мышления. Эти выводы полезны для обучения моделей (напр. GRPO и SFT), представляется целесообразным разработать модели следующего поколения, которые будут более эффективными и смогут адаптивно регулировать глубину мышления в зависимости от сложности задачи.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...