
Как большие модели становятся "умнее"? Стэнфордский университет раскрывает ключ к самосовершенствованию: четыре вида когнитивного поведения

В последние годы область искусственного интеллекта достигла впечатляющих успехов, особенно в области моделирования больших языков (LLM). Многие модели, такие как Qwen, продемонстрировали удивительную способность к самопроверке ответов и исправлению ошибок. Однако не все модели одинаково способны к самосовершенствованию. При одинаковых дополнительных вычислительных ресурсах и времени на "обдумывание" некоторые модели способны максимально использовать эти ресурсы и значительно улучшить свою производительность, в то время как другие не добиваются особых успехов. В связи с этим феноменом возникает вопрос: какие факторы ответственны за такое расхождение?
Подобно тому, как человек тратит больше времени на глубокие размышления, сталкиваясь со сложными проблемами, некоторые продвинутые модели больших языков начинают демонстрировать подобное поведение при самосовершенствовании с помощью обучения с подкреплением. Однако между моделями, обученными с помощью одного и того же обучения с подкреплением, существуют значительные различия в самосовершенствовании. Например, Qwen-2.5-3B значительно превосходит Llama-3.2-3B в игре Countdown. Хотя обе модели относительно слабы на начальном этапе, в конце обучения с подкреплением Qwen достигает точности около 60%, а Llama - только около 30%. Какой скрытый механизм лежит в основе такого значительного разрыва?
Недавнее исследование, проведенное в Стэнфорде, позволило глубже изучить механизмы, лежащие в основе способности больших моделей к самосовершенствованию, и обнаружить, что ключевые языковые модели, лежащие в основе когнитивное поведение Важность искусственного интеллекта. Это исследование открывает новые перспективы в понимании и расширении возможностей самосовершенствования систем ИИ.
Исследование широко обсуждалось после его публикации. Генеральный директор Synth Labs, например, считает, что открытие очень интересно, поскольку его можно интегрировать в любую модель, чтобы улучшить ее производительность.

Четыре ключевых когнитивных поведения
Чтобы выяснить причины различий в самосовершенствовании, исследователи сосредоточились на двух базовых моделях, Qwen-2.5-3B и Llama-3.2-3B. Обучая их с помощью обучения с подкреплением в игре Countdown, исследователи заметили существенные различия: способность Qwen решать задачи значительно улучшилась, в то время как Llama-3 продемонстрировала относительно ограниченное улучшение в процессе обучения. Так какие же свойства модели отвечают за эту разницу?

Чтобы систематически изучать этот вопрос, исследовательская группа разработала схему анализа когнитивного поведения, которое имеет решающее значение для решения проблем. Эта система описывает четыре ключевых вида когнитивного поведения:
- Верификация:: Систематическая проверка ошибок.
- Обратный путь:: Откажитесь от неудачных подходов и попробуйте новые пути.
- Постановка подцелей:: Разбивайте сложные проблемы на управляемые шаги.
- Обратное мышление: Обратный вывод от желаемого результата к исходным данным.
Эти модели поведения очень похожи на то, как эксперты решают сложные задачи. Например, математики проводят доказательства, тщательно проверяя каждый шаг дедукции; возвращаясь назад, чтобы проверить предыдущие шаги, когда встречаются противоречия; и разбивая сложные теоремы на более простые леммы для пошаговых доказательств.

Предварительный анализ показывает, что модель Qwen естественным образом демонстрирует такое поведение при выводе, особенно в областях проверки и обратного хода, в то время как модель Llama-3 явно не обладает подобным поведением. Основываясь на этих наблюдениях, исследователи сформулировали основную гипотезу: Для эффективного использования моделью увеличенного времени тестирования критически важны определенные модели поведения в начальной стратегии. Другими словами, если модель ИИ хочет стать "умнее", когда у нее будет больше времени на "размышления", она должна сначала приобрести некоторые базовые навыки мышления, такие как привычка проверять ошибки и проверять результаты. Если модель с самого начала не обладает этими базовыми навыками мышления, она не сможет эффективно улучшить свою производительность, даже если ей будет предоставлено больше времени на размышления и вычислительных ресурсов. Это очень похоже на процесс обучения человека - если у студентов отсутствуют базовые навыки самопроверки и исправления ошибок, то простая сдача более длительных экзаменов вряд ли значительно улучшит их успеваемость.
Экспериментальная проверка: важность когнитивного поведения
Чтобы проверить гипотезу, исследователи провели серию экспериментов с умным вмешательством.
Во-первых, они попытались провести бутстрап модели Llama-3, используя синтетические траектории вывода, содержащие специфическое когнитивное поведение (в частности, ретроспекцию). Результаты показывают, что модель Llama-3, управляемая таким образом, демонстрирует значительные улучшения в обучении с подкреплением, причем прирост производительности даже сопоставим с Qwen-2.5-3B.
Во-вторых, даже если траектории рассуждений, использованные для бутстрапинга, содержали неправильные ответы, модель Llama-3 все равно была способна добиться прогресса, пока эти траектории демонстрировали правильные модели рассуждений. Этот вывод позволяет предположить, что Ключевым фактором, который действительно способствует самосовершенствованию модели, является наличие рассуждающего поведения, а не правильность самого ответа.
Наконец, исследователи отфильтровали набор данных OpenWebMath, чтобы подчеркнуть эти модели поведения при рассуждениях, и использовали эти данные для предварительного обучения модели Llama-3. Экспериментальные результаты показывают, что такая целенаправленная адаптация данных предварительного обучения эффективно вызывает поведение умозаключений, необходимое для эффективного использования моделью вычислительных ресурсов. Траектория повышения производительности модели Llama-3, прошедшей предварительное обучение, удивительным образом совпадает с траекторией модели Qwen-2.5-3B.
Результаты этих экспериментов убедительно свидетельствуют о наличии тесной связи между начальным поведением модели в рассуждениях и ее способностью к самосовершенствованию. Эта связь помогает объяснить, почему одни языковые модели способны эффективно использовать дополнительные вычислительные ресурсы, а другие стагнируют. Более глубокое понимание этой динамики необходимо для разработки систем ИИ, способных значительно улучшить решение задач.
Игра с обратным отсчетом времени с выбором модели
Исследование начинается с удивительного наблюдения: языковые модели одинакового размера из разных семейств моделей демонстрируют совершенно разный прирост производительности при обучении с применением обучения с подкреплением. Для глубокого изучения этого феномена исследователи выбрали игру Countdown в качестве основного тестового стенда.
Countdown - это математическая головоломка, в которой игроку нужно объединить заданный набор чисел с помощью четырех основных операций: сложения, вычитания, умножения и деления, чтобы достичь заданного числа. Например, если даны числа 25, 30, 3, 4 и целевое число 32, игроку нужно получить точное число 32 с помощью ряда операций, например, (30 - 25 + 3) × 4 = 32.
Игра "Обратный отсчет" была выбрана для данного исследования потому, что она позволяет изучить математические рассуждения, возможности планирования и стратегии поиска модели, при этом предоставляя относительно ограниченное пространство поиска, что позволяет исследователю проводить глубокий анализ. По сравнению с более сложными областями, игра Countdown снижает сложность анализа, но при этом эффективно исследует сложные рассуждения. Кроме того, успех игры Countdown в большей степени зависит от навыков решения задач, чем от других математических задач, а не от чисто математических знаний.
Исследователи выбрали две базовые модели, Qwen-2.5-3B и Llama-3.2-3B, чтобы сравнить различия в обучении между разными семействами моделей. Эксперименты по обучению с подкреплением основаны на библиотеке VERL и реализованы с помощью TinyZero. Для обучения модели в течение 250 шагов использовался алгоритм PPO (Proximal Policy Optimization) с выборкой 4 траекторий на каждую реплику. Причина выбора алгоритма PPO заключается в том, что по сравнению с GRPO По сравнению с другими алгоритмами обучения с подкреплением, такими как REINFORCE, PPO демонстрирует лучшую устойчивость при различных настройках гиперпараметров, хотя общая разница в производительности между алгоритмами невелика. (Примечание редактора: есть подозрение, что оригинальное слово "GRPO" является опечаткой и должно читаться как PPO.)
Результаты экспериментов показывают совершенно разные траектории обучения для двух моделей. Несмотря на то что в начале выполнения задания обе модели демонстрируют схожие низкие результаты, Qwen-2.5-3B показывает "качественный скачок" примерно на 30-м шаге обучения, о чем свидетельствуют значительно более длинные ответы, генерируемые моделью, и значительное увеличение точности. В конце обучения Qwen-2.5-3B достигает точности около 601 TP3T, что значительно выше, чем 301 TP3T у Llama-3.2-3B.
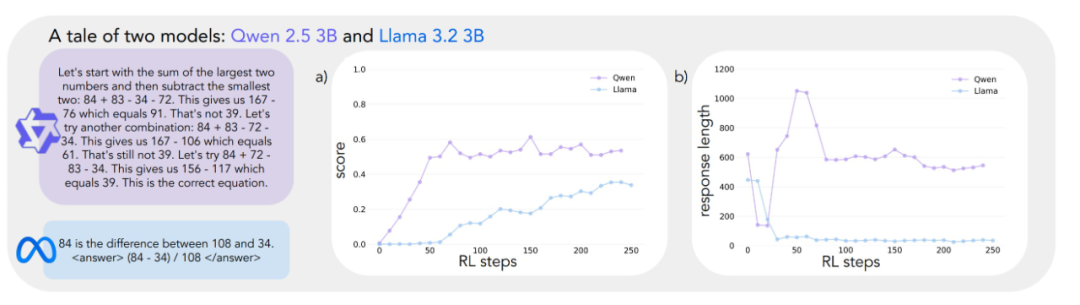
На более поздних этапах обучения исследователи заметили интересный сдвиг в поведении Qwen-2.5-3B: модель постепенно перешла от использования явных утверждений о проверке (например, "8*35 - 280, слишком много") к неявной проверке решения. Модель будет последовательно (на русский язык это переводится как "последовательно земля" или "последовательно") пробовать разные решения, пока не найдет правильное, вместо того чтобы оценивать свою работу словами. Контраст поразителен. Этот контраст приводит к главному вопросу: каковы возможности, лежащие в основе модели, которые позволяют ей успешно самосовершенствоваться на основе рассуждений? Для ответа на этот вопрос необходима систематическая основа для анализа когнитивного поведения.
Концепция когнитивно-поведенческого анализа
Чтобы глубже понять, чем отличаются траектории обучения в двух моделях, исследователи разработали систему выявления и анализа ключевых когнитивных форм поведения в результатах моделирования. Эта система фокусируется на четырех основных видах поведения:
- Обратный путь: Явно модифицируйте метод при обнаружении ошибки (например, "Этот метод не работает, потому что..."). .").
- Верификация: Систематически проверяйте промежуточные результаты (например, "Давайте проверим этот результат с помощью ... чтобы проверить этот результат").
- Постановка подцелей: Разбейте сложные проблемы на управляемые шаги (например, "Чтобы решить эту проблему, нам сначала нужно..."). .
- Обратное мышление: В задачах с целевыми рассуждениями начните с желаемого результата и работайте в обратном направлении, чтобы найти путь к решению (например, "Чтобы достичь цели 75, нам нужно число, которое ... кратно ..."). .").
Эти модели поведения были выбраны потому, что они представляют собой стратегию решения проблем, сильно отличающуюся от линейных, монотонных моделей рассуждений, распространенных в языковых моделях. Эти когнитивные модели поведения позволяют создавать более динамичные, похожие на поиск траектории рассуждений, в которых решения могут развиваться нелинейно. Хотя этот набор моделей поведения не является исчерпывающим, исследователи выбрали их, потому что их легко идентифицировать, и они естественным образом соответствуют стратегиям решения проблем человеком в играх Countdown и в более широких задачах математического мышления, таких как построение математических доказательств.
Каждое когнитивное поведение может быть понято через его роль в рассуждении жетон Например, обратный путь представлен в виде последовательности лексем, явно отрицающих и заменяющих предыдущие шаги. Например, обратный путь представлен в виде последовательности лексем, которые явно отрицают и заменяют предыдущие шаги; проверка представлена генерацией лексем, которые сравнивают результаты с критериями решения; обратный путь представлен лексемами, которые инкрементально строят путь решения к начальному состоянию от цели; а постановка подцели представлена явным предложением промежуточных шагов, которые должны быть достигнуты на пути к конечной цели. Исследователи разработали конвейер классификации с использованием модели GPT-4o-mini, который надежно идентифицирует эти паттерны в выходных данных модели.
Влияние первоначального поведения на самосовершенствование
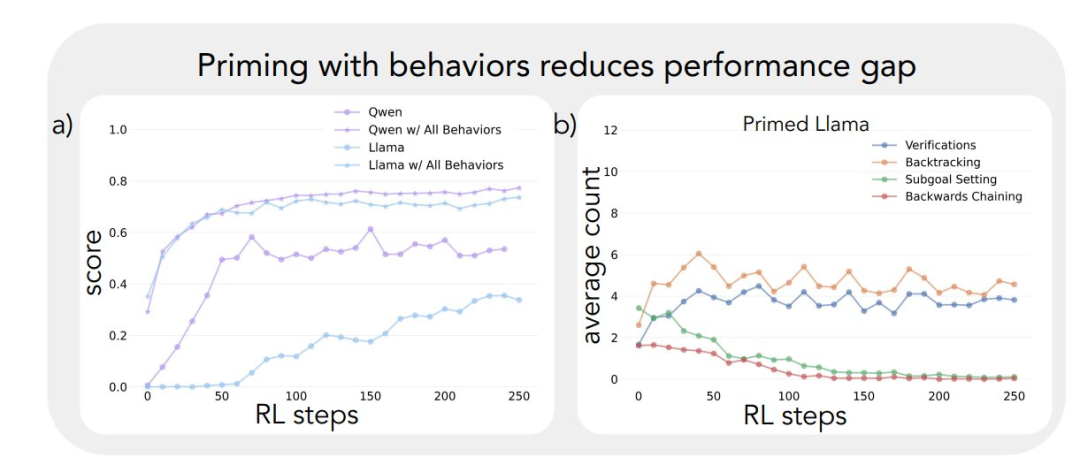
Применение описанной выше аналитической схемы к первоначальным экспериментам позволило сделать ключевой вывод: Значительное улучшение производительности модели Qwen-2.5-3B происходит параллельно с появлением когнитивного поведения, в частности, поведения проверки и обратного хода. В отличие от этого, модель Llama-3.2-3B не проявляла никаких признаков такого поведения на протяжении всего обучения.
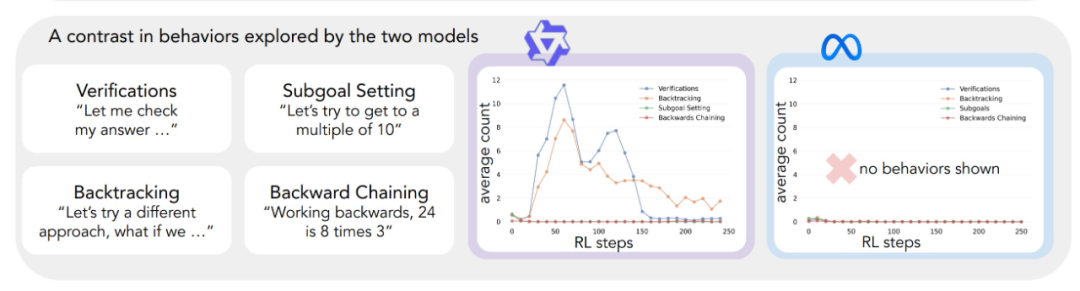
Чтобы глубже понять эту разницу, исследователи проанализировали исходные модели рассуждений трех моделей: Qwen-2.5-3B, Llama-3.2-3B и Llama-3.1-70B. Результаты анализа показали, что в модели Qwen-2.5-3B доля всех видов когнитивного поведения выше, чем в двух вариантах модели Llama - Llama-3.2-3B и Llama-3.1-70B. Модель 2.5-3B продемонстрировала более высокую долю всех видов когнитивного поведения. Хотя более крупная модель Llama-3.1-70B в целом активировала эти виды поведения чаще, чем модель Llama-3.2-3B, это увеличение было неравномерным, особенно для ретроспективного поведения, которое оставалось ограниченным даже в более крупной модели.

Эти наблюдения позволяют сделать два важных вывода:
- Наличие определенных когнитивных моделей поведения в начальной стратегии может быть предпосылкой, необходимой для того, чтобы модель могла эффективно использовать увеличенное время вычисления теста путем расширения последовательности умозаключений.
- Увеличение размера модели может в определенной степени улучшить частоту контекстуальной активации этих когнитивных моделей поведения.
Эта модель очень важна, поскольку обучение с подкреплением может только усилить поведение, которое уже присутствует в успешных траекториях. Это означает, что изначальное наличие этих когнитивных моделей поведения является необходимым условием для эффективного обучения в данной модели.
Вмешательство в начальное поведение: руководство обучением на модели
Установив важность когнитивного поведения в базовой модели, возникает следующий вопрос: можно ли искусственно вызвать это поведение в модели с помощью целенаправленного вмешательства? Исследователи предположили, что, создавая варианты базовой модели, которые выборочно демонстрируют определенные когнитивные модели поведения перед обучением с подкреплением, можно достичь более глубокого понимания того, какие поведенческие модели необходимы для эффективного обучения.
Чтобы проверить эту гипотезу, они сначала разработали семь различных стартовых наборов данных, используя игру "Обратный отсчет". Пять из этих наборов данных подчеркивали различные комбинации поведения: все комбинации стратегий, только отступление, отступление и проверка, отступление и постановка подцели, отступление и обратное мышление. Для создания этих наборов данных они использовали модель Claude-3.5-Sonnet, поскольку Claude-3.5-Sonnet способна генерировать траектории умозаключений с точно заданными поведенческими характеристиками.
Чтобы убедиться в том, что прирост производительности был обусловлен специфическим когнитивным поведением, а не просто увеличением времени вычислений, исследователи также ввели два контрольных условия: пустую цепочку мыслей и контрольное условие, в котором цепочка заполнялась маркерами-заполнителями, а длина точек данных соответствовала набору данных "все комбинации стратегий". ". Эти контрольные наборы данных помогли исследователям убедиться в том, что наблюдаемое улучшение производительности действительно связано с конкретным когнитивным поведением, а не просто с увеличением времени вычислений.
Кроме того, исследователи создали вариант набора данных "Полная комбинация стратегий", который содержит только неправильные решения, но сохраняет необходимые шаблоны рассуждений. Цель этого варианта - выявить разницу между важностью когнитивного поведения и точностью решений.
Результаты экспериментов показывают, что модели Llama-3 и Qwen-2.5-3B демонстрируют значительный прирост производительности в результате обучения с применением подкрепления при инициализации набором данных, содержащим ретроспективное поведение. Анализ поведения также показывает, что Обучение с подкреплением избирательно усиливает поведение, полезность которого доказана эмпирически, и подавляет другие виды поведения. Например, в условии "Полное сочетание стратегий" модель сохраняет и усиливает ретроспективное поведение и поведение подтверждения, в то же время снижая частоту поведения, связанного с отходом назад и постановкой подцели. Однако в паре только с ретроспективным поведением подавляемые виды поведения (например, откат назад и постановка подцели) сохраняются на протяжении всего обучения.
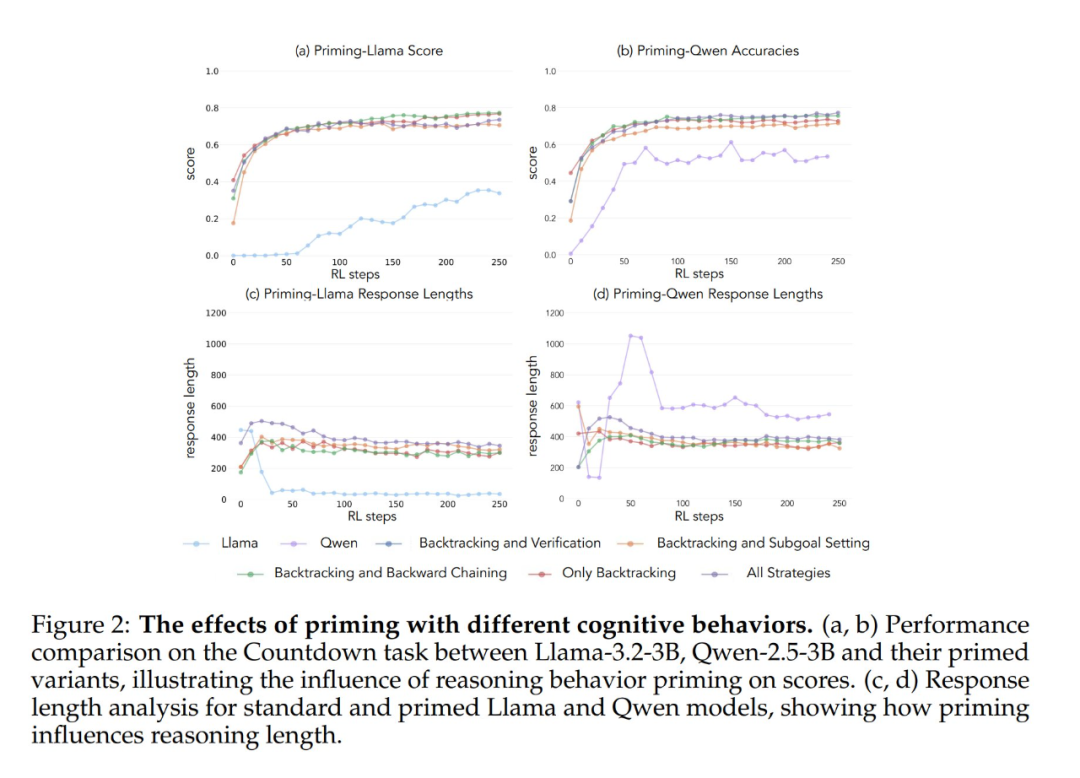
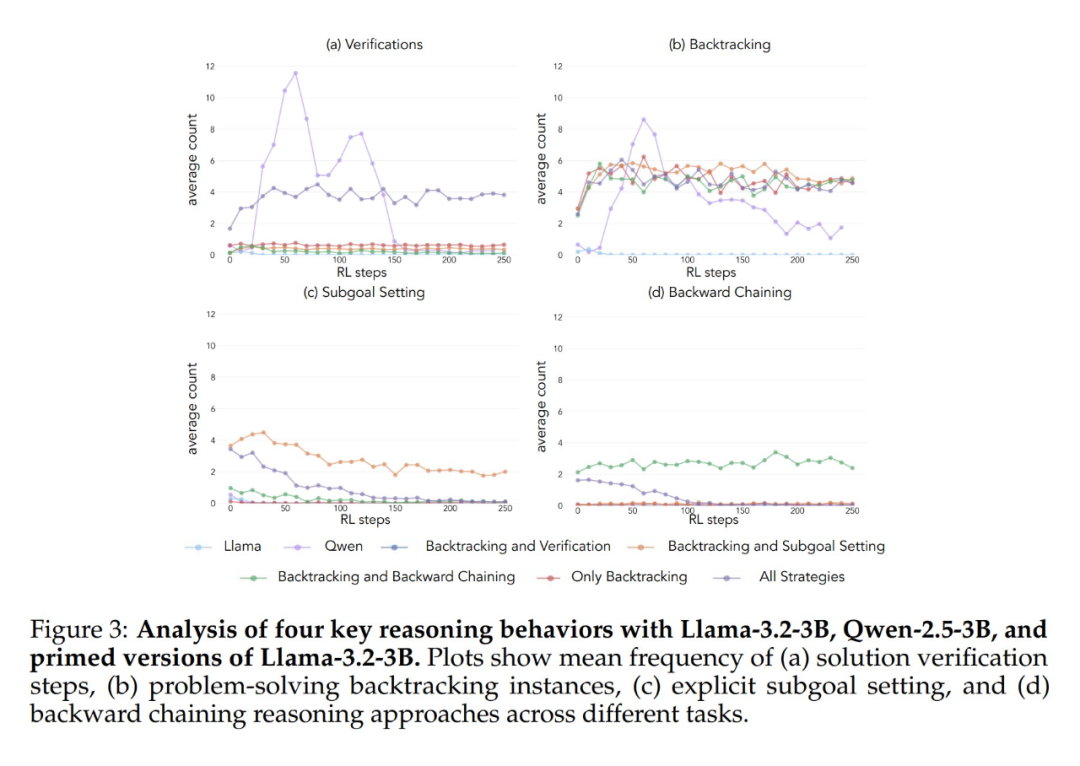
При запуске с использованием пустой мыслительной цепочки в качестве контрольного условия обе модели показали результаты, сопоставимые с базовой моделью Llama-3 (точность примерно 30%-35%). Это говорит о том, что простое назначение дополнительных жетонов без включения когнитивного поведения не является эффективным использованием времени вычислений в тесте. Еще более удивительно, что обучение с пустыми цепочками мыслей даже имело пагубный эффект, поскольку модель Qwen-2.5-3B перестала исследовать новые поведенческие модели. Это еще одно доказательство того, что Такое когнитивное поведение очень важно для того, чтобы модель эффективно использовала расширенные вычислительные ресурсы за счет более длинных последовательностей выводов.
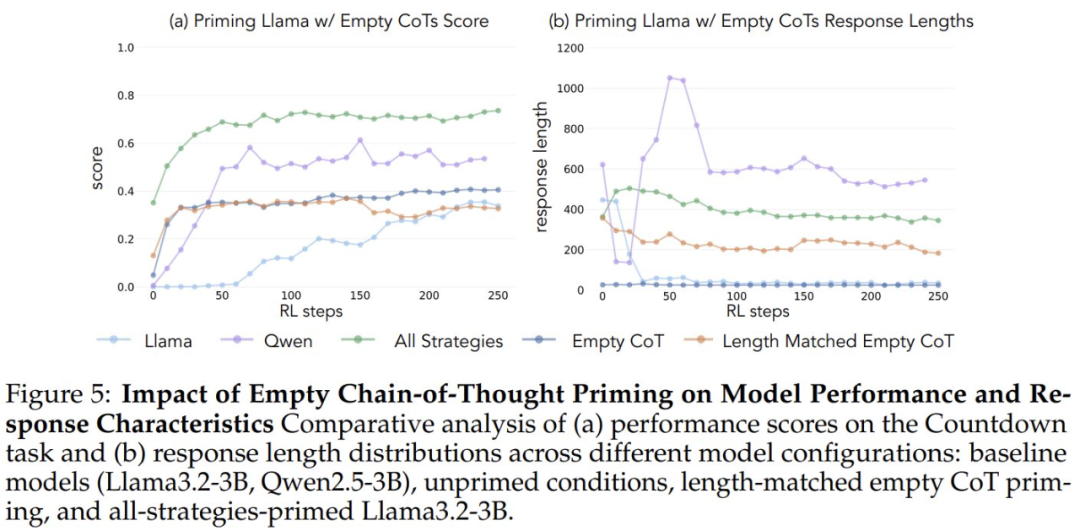
Что еще более удивительно, модели, инициализированные неправильными решениями, но с правильным когнитивным поведением, достигли почти такого же уровня производительности, как и модели, обученные на наборах данных, содержащих правильные решения. Этот результат убедительно свидетельствует о том, что Наличие когнитивных моделей поведения (а не получение правильных ответов) является ключевым фактором успешного самосовершенствования через обучение с подкреплением. Таким образом, модели рассуждений, полученные на основе относительно слабых моделей, могут эффективно направлять процесс обучения на построение более сильных моделей. Это еще раз доказывает, что Наличие когнитивного поведения важнее, чем правильность результата.

Поведенческий отбор на данных предварительного обучения
Результаты этих экспериментов свидетельствуют о том, что определенные виды когнитивного поведения необходимы для самосовершенствования модели. Однако методы, использовавшиеся в предыдущем исследовании для вызывания определенных форм поведения в исходных моделях, были специфичны для данной области и основывались на играх с обратным отсчетом. Это может негативно сказаться на способности обобщения итоговых выводов. Итак, можно ли увеличить частоту полезного поведения в выводах, изменив распределение данных предварительного обучения модели, чтобы добиться более общей способности к самосовершенствованию?
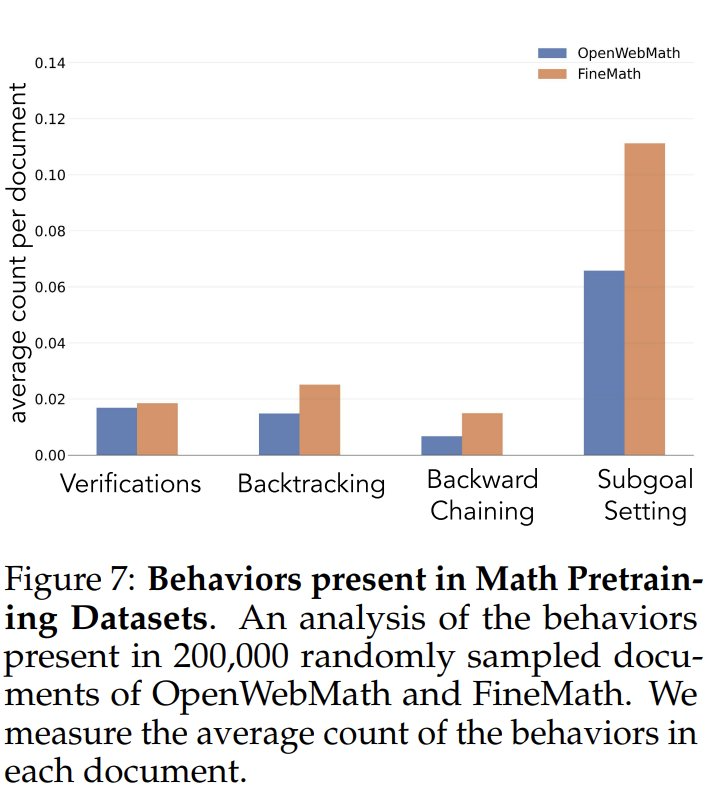
Чтобы изучить частоту когнитивного поведения в данных предварительного обучения, исследователи сначала проанализировали естественные частоты когнитивного поведения в данных предварительного обучения. Они сосредоточились на наборах данных OpenWebMath и FineMath, которые были созданы специально для математических рассуждений. Используя модель Qwen-2.5-32B в качестве классификатора, исследователи проанализировали 200 000 случайно выбранных документов из этих двух наборов данных на предмет наличия целевого когнитивного поведения. Результаты показали, что даже в этих корпорациях, ориентированных на математику, частота когнитивного поведения, такого как откат назад и проверка, остается низкой. Это говорит о том, что стандартные процессы предварительного обучения ограничивают знакомство с этими ключевыми поведенческими моделями.
Чтобы проверить, повышает ли искусственное увеличение воздействия когнитивного поведения на потенциал самосовершенствования модели, исследователи разработали целевой непрерывный набор данных для предварительного обучения на основе набора данных OpenWebMath. Сначала они использовали модель Qwen-2.5-32B в качестве классификатора для анализа математических документов из корпуса предварительного обучения с целью выявления наличия целевого поведения рассуждения. На основе этого они создали два сравнительных набора данных: один, богатый когнитивными моделями поведения, и контрольный, содержащий очень мало когнитивного контента. Затем они использовали модель Qwen-2.5-32B, чтобы переписать каждый документ в обоих наборах в структурированный формат "вопрос-ответ", сохраняя при этом естественное присутствие или отсутствие когнитивного поведения в исходных документах. Полученные наборы данных для предварительного обучения содержали в общей сложности 8,3 млн лексем. Такой подход позволил исследователям эффективно изолировать влияние когнитивного поведения, контролируя при этом формат и объем математического контента в процессе предварительного обучения.
После предварительного обучения модели Llama-3.2-3B на этих наборах данных и применения обучения с подкреплением исследователи обнаружили:
- Поведенчески насыщенные предварительно обученные модели в конечном итоге достигают уровня производительности, сопоставимого с моделью Qwen-2.5-3B, при относительно ограниченном улучшении производительности контрольной модели.
- Поведенческий анализ моделей после обучения показал, что поведенчески обогащенный вариант предварительно обученной модели сохранял высокую активацию поведения умозаключения на протяжении всего процесса обучения, в то время как контрольная модель демонстрировала поведение, сходное с базовой моделью Llama-3.
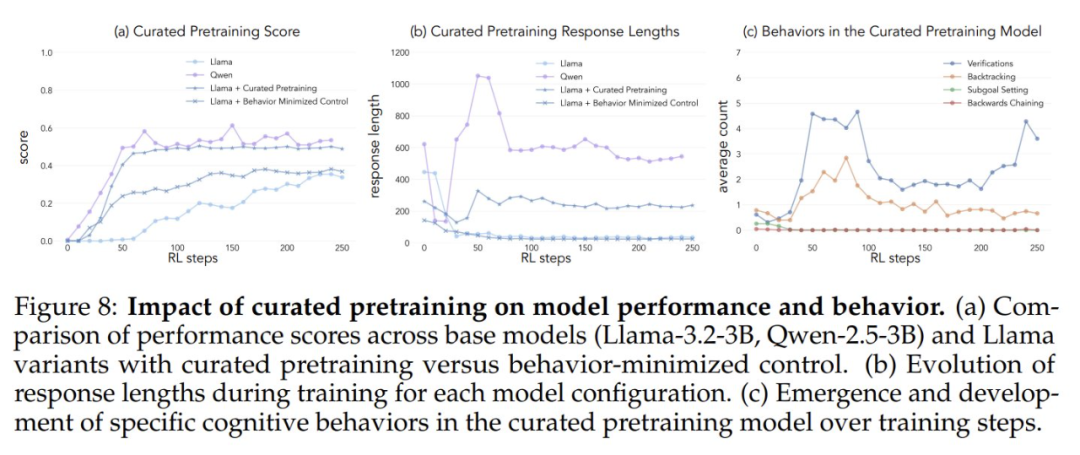
Результаты этих экспериментов убедительно свидетельствуют о том, что Целенаправленное изменение данных предварительного обучения может успешно генерировать ключевые когнитивные модели поведения, необходимые для эффективного самосовершенствования с помощью обучения с подкреплением. Данное исследование предлагает новые идеи и методы для понимания и улучшения возможностей самосовершенствования больших языковых моделей. За более подробной информацией обращайтесь к оригинальной статье.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...