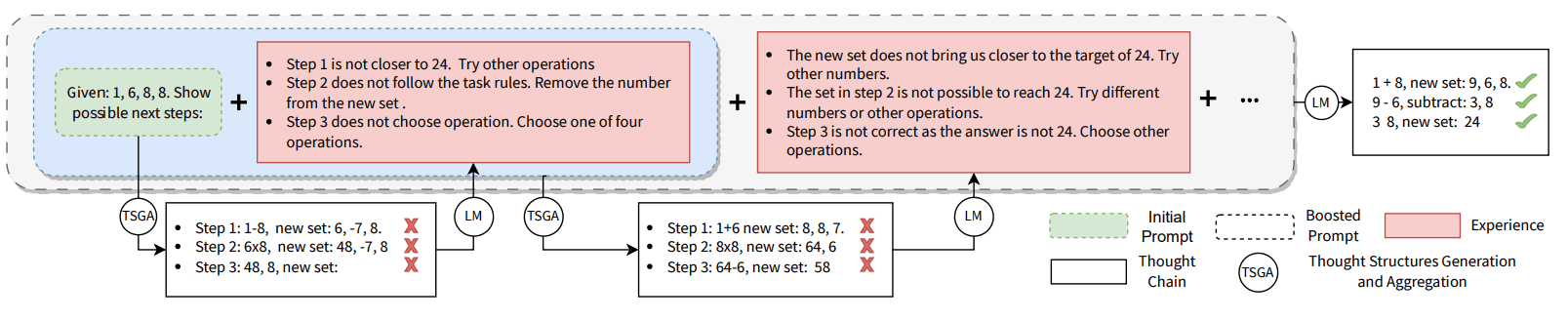
Интерпретация ключевых параметров большой модели: токен, длина контекста и границы вывода

Крупномасштабные языковые модели (LLM) играют все более важную роль в области искусственного интеллекта. Для того чтобы лучше понять и применить LLM, нам необходимо глубже понять их основные концепции. В этой статье мы сосредоточимся на трех ключевых концепциях, а именно: Token, Maximum Output Length и Context Length, чтобы помочь читателям устранить барьеры понимания и более эффективно использовать технологию LLM.
Токен: базовый процессор LLM
Token Токен - это базовая единица большой языковой модели (LLM) для обработки текстов на естественном языке, которую можно понимать как наименьшую семантическую единицу, которую модель может распознать и обработать. Хотя Token можно условно сравнить со "словом" или "фразой", более точно его можно описать как строительный блок, на котором модель основывает свой анализ и генерацию текста.
На практике существует определенная конверсионная зависимость между Token и количеством слов. В общем случае:
- 1 английский символ ≈ 0,3 Токен
- 1 китайский иероглиф ≈ 0,6 жетона
Поэтому мы можемприблизительная оценка(математика) родкак правилоКитайский иероглиф можно рассматривать как Token.

Как показано на рисунке выше, когда мы вводим текст в LLM, модель сначала разбивает его на последовательности токенов, а затем обрабатывает эти последовательности токенов, чтобы сгенерировать нужный результат. Следующий рисунок наглядно демонстрирует процесс токенизации текста:

Максимальная длина вывода (предел вывода): верхний предел генерации одного текста моделью
согласно DeepSeek В качестве примера можно привести модели серии, которые устанавливают ограничение на максимальную длину выхода.

Выше.deepseek-chat соответствие модели DeepSeek-V3 версия, в то время как deepseek-reasoner тогда модель соответствует DeepSeek-R1 Версии. Для модели вывода R1 и модели диалога V3 максимальная длина выходных данных установлена на 8K.
Учитывая приблизительное соотношение конвертации, один кандзи примерно равен одному токену.8K Максимальная длина выходного сигнала может быть интерпретирована как: Модель способна генерировать до 8000 китайских иероглифов за одно взаимодействие..
Концепция максимальной длины вывода относительно интуитивна и проста для понимания: она ограничивает максимальный объем текста, который модель может выдать в каждом ответе. Как только этот предел достигнут, модель не сможет продолжать генерировать больше контента.
Контекстное окно: объем памяти модели.
Длина контекста, также известная в технической сфере как Context Windowявляется ключевым параметром для понимания возможностей LLM. Мы продолжаем DeepSeek Модель проиллюстрирована на примере:

Как показано на рисунке, и модель вывода, и модель диалога, иDeepSeek (используется в форме номинального выражения) Context Window все 64K. Итак.64K Что именно означает длина контекста
Чтобы понять длину контекста, необходимо сначала уточнить его определение. Контекстное окно - это максимальное количество лексем, которое может быть обработано большой языковой моделью (LLM) за один сеанс вывода.. Эта сумма состоит из двух частей:
(1) входная секция: Все вводимые пользователем данные, такие как подсказки, история диалога и любое дополнительное содержимое документа.
(2) выходная секция: Содержимое ответа, который модель генерирует и возвращает в данный момент.
Короче говоря, когда мы взаимодействуем с LLM один раз, весь процесс, начиная с ввода вопроса и заканчивая выдачей моделью ответа, называется "одиночным умозаключением". Во время этого процесса сумма всего входного и выходного текстового контента (считаемого в Token) не может быть больше, чем Context Window Ограничения для DeepSeek С точки зрения модели, это ограничение является 64KКоличество китайских иероглифов, использованных в исследовании, составляет около 60 000.
Если вам интересно.Так есть ли предел тому, что можно ввести? Ответ - да. Как упоминалось ранее, модель имеет длину контекста 64K и максимальную длину вывода 8K. Таким образом, в одном раунде диалога максимальное количество лексем для входного контента теоретически равно длине контекста минус максимальная длина вывода, т. е. 64K - 8K = 56K. Таким образом, в одном вопросно-ответном взаимодействии пользователь может ввести около 56 000 слов, а модель может вывести около 8 000 слов.
Механизмы обработки контекста для многораундовых диалогов
На практике мы часто проводим несколько раундов диалога с LLM. Так как же в многораундовом диалоге можно работать с контекстом? Возьмем DeepSeek Например, при инициировании многораундового диалога серверная сторонаКонтекст диалога пользователя не сохраняется по умолчанию. Это означает, что вДля каждого нового запроса на диалог пользователю необходимо собрать воедино весь контент, включая историю диалога, и передать его API в качестве входной информации..
Чтобы более наглядно проиллюстрировать механику многораундового диалога, приведем пример кода на языке Python для многораундового диалога с использованием API DeepSeek:
from openai import OpenAI
client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
# Round 1
messages = [{"role": "user", "content": "What's the highest mountain in the world?"}]
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
messages.append(response.choices[0].message)
print(f"Messages Round 1: {messages}")
# Round 2
messages.append({"role": "user", "content": "What is the second?"})
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages
)
messages.append(response.choices[0].message)
print(f"Messages Round 2: {messages}")
Содержимое параметра messages, передаваемого API во время первого раунда запросов диалога, выглядит следующим образом:
[
{"role": "user", "content": "What's the highest mountain in the world?"}
]
Требуется для второго раунда запросов на диалог:
(1) Добавьте выход модели из предыдущего раунда диалога к сообщения Конец списка;
(2) Добавьте новый вопрос пользователя также в сообщения Конец списка.
Таким образом, во втором раунде диалога параметр messages, передаваемый API, будет содержать следующее:
[
{"role": "user", "content": "What's the highest mountain in the world?"},
{"role": "assistant", "content": "The highest mountain in the world is Mount Everest."},
{"role": "user", "content": "What is the second?"}
]
Из этого следует, что суть многораундового диалога заключается в том, чтобы объединитьИсторические транскрипты диалогов (включая пользовательский ввод и вывод модели) сращиваются перед последним пользовательским вводом, а затем сращенный полный диалог передается в LLM за один раз.
Это означает, что в сценарии многораундового диалога Контекстное окно для каждого раунда диалога не всегда остается неизменным на уровне 64K, а уменьшается по мере увеличения количества раундов. Например, если входы и выходы первого раунда диалога используют в общей сложности 32К лексем, то во втором раунде диалога доступное контекстное окно будет составлять только 32К. Этот принцип согласуется с ограничением длины контекста, рассмотренным выше.
У вас также может возникнуть вопрос: если, согласно этому механизму, входы и выходы каждого раунда диалога очень длинные, не потребуется ли несколько раундов диалога, чтобы выйти за пределы модели? На практике, однако, кажется, что модель способна правильно реагировать даже при нескольких раундах диалога.
Это очень хороший вопрос, который подводит нас к еще одному ключевому понятию: "контекстное усечение".
Контекстуальное усечение: стратегии работы с очень длинными диалогами
Когда мы используем продукты, основанные на LLM (например, DeepSeek, Wisdom Spectrum и т. д.), поставщики услуг обычно не выставляют пользователю жесткие границы контекстного окна, а используют усечение контекста, чтобы Стратегия Context Truncation используется для обработки очень длинных текстов.
Допустим, модель поддерживает контекстное окно размером 64 К. Если пользователь накопил 64 К или почти столько же за несколько раундов диалога, а затем инициирует новый запрос (например, на 2 К жетонов), лимит контекстного окна будет превышен. В этом случае сервер обычно сохраняет самый последний запрос. 64K Токен (включая самый последний ввод), при этом отбрасывая самую раннюю часть истории диалога**. Для пользователя сохраняется его самый последний ввод, в то время как самый ранний ввод (или даже вывод) "забывается" моделью. **
Именно поэтому при многократных раундах диалога модель иногда страдает от "амнезии", хотя мы по-прежнему можем получать от нее нормальные ответы. Поскольку емкость контекстного окна ограничена, модель не может запомнить всю историческую информацию о диалоге, она может только "вспомнить самое последнее и забыть давнее".
Необходимо подчеркнуть, что"Контекстное усечение" - это стратегия, реализованная на инженерном уровне, а не возможность, заложенная в самой модели**. Пользователи, как правило, не ощущают присутствия процесса усечения в момент использования, поскольку серверная часть делает это в фоновом режиме. **

Подводя итог, можно сделать следующие выводы о длине контекста, максимальной длине вывода и усечении контекста:
- Контекстное окно (например, 64К) - это жесткий предел для модели, позволяющий обрабатывать один запросОбщее количество входов и выходов Token не должно превышать этот предел.
- Управление очень длинными текстами в многораундовых диалогах на стороне сервера с помощью контекстных политик усеченияПозволяет пользователям вступать в диалог в несколько раундов Контекстное окно ограничения, но это будет происходить за счет объема долговременной памяти модели.
- Ограничения контекстного окна обычно являются стратегией поставщика услуг, направленной на контроль затрат или снижение рискаТехнические возможности самой модели не совсем совпадают с возможностями модели.
Сравнение параметров моделей: OpenAI и Anthropic
Настройки параметров максимальной длины вывода и длины контекста различаются у разных производителей моделей. На следующем рисунке показаны конфигурации параметров некоторых моделей на примере OpenAI и Anthropic:

На рисунке "Context Tokens" представляет собой длину контекста, а "Output Tokens" - максимальную длину вывода.
Технические принципы: причины ограничений
Почему LLM устанавливает ограничения на максимальную длину вывода и длину контекста? С технической точки зрения, это связано с ограничениями на архитектуру модели и вычислительные ресурсы. Вкратце, ограничение на окно контекста определяется следующими ключевыми факторами:
(1) Диапазон кодов позиций: Трансформатор Модель опирается на позиционное кодирование (например, RoPE, ALiBi) для присвоения позиционной информации каждому токену, и диапазон конструкций позиционного кодирования напрямую определяет максимальную длину последовательности, которую может обрабатывать модель.
(2) Расчет механизма самовнушения: При генерации каждого нового токена модель должна вычислить аттенционный вес между этим токеном и всеми предыдущими токенами (как входными, так и сгенерированными выходными). Поэтому общая длина последовательности строго ограничена. Кроме того, использование памяти KV Cache положительно коррелирует с общей длиной последовательности, и превышение длины контекстного окна может привести к переполнению памяти или ошибкам вычислений.
Типичные сценарии применения и стратегии реагирования
Очень важно понимать понятия максимальной длины выходного сигнала и длины контекста, а также технические принципы, лежащие в их основе. Получив эти знания, пользователи должны разработать соответствующие стратегии при использовании инструментов больших моделей, чтобы повысить эффективность и результативность их применения. Ниже перечислены несколько типичных сценариев применения и приведены соответствующие стратегии реагирования:
- Короткий вход + длинный выход
- сценарий применения: Пользователи вводят небольшое количество токенов (например, 1K) и хотят, чтобы модель генерировала длинный контент, например, статьи, рассказы и т.д.
- Конфигурация параметров: Во время вызова API вы можете установить значение max_tokens параметр установлен на большее значение, например 63,000 (Обязательно введите то же количество жетонов, что и в max_tokens и не более Контекстное окно пределы, например, 1K + 63K ≤ 64K).
- потенциальный риск: Вывод модели может быть прекращен раньше времени из-за проверки качества (например, чрезмерное повторение, включение чувствительных слов и т.д.).
- Длинный вход + короткий выход
- сценарий применения: Пользователь вводит длинный документ (например, 60 тыс. лексем) и просит модель обобщить его, извлечь информацию и т. д. и выдать короткий результат.
- Конфигурация параметров: Вы можете установить max_tokens параметр устанавливается на меньшее значение, например 4,000 (например, 60K + 4K ≤ 64K).
- потенциальный риск: Если модель действительно требует больше выходных маркеров, чем количество max_tokens Если входной документ сжимается (например, из него извлекаются ключевые абзацы, сокращается избыточная информация и т. д.), чтобы обеспечить полноту выходных данных, то выходные данные будут сжаты.
- Управление многораундовым диалогом
- правила и положения: Во время нескольких раундов диалога необходимо следить за тем, чтобы общее количество накопленных входных и выходных жетонов не превышало Контекстное окно ограничения (превышение которых будет усечено).
- типичный пример::
(1) Диалог в 1 раунде: пользователь вводит 10K жетонов, модель выводит 10K жетонов, накапливается 20K жетонов.
(2) Диалог во втором раунде: пользователь ввел 30 тыс. жетонов, модель вывела 14 тыс. жетонов, накоплено 64 тыс. жетонов.
(3) Диалог в третьем раунде: пользователь вводит 5K токенов, сервер обрезает самые ранние 5K токенов и сохраняет последние 59K. жетоны История, плюс новый ввод 5K жетонов, итого 64K жетонов.
Понимая три основных понятия: токен, максимальная длина вывода и длина контекста, а также сформулировав разумную стратегию, основанную на конкретных сценариях применения, мы сможем более эффективно использовать технологию LLM и полностью раскрыть ее потенциал.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...