Как рассчитать количество параметров для большой модели, и что означают 7B, 13B и 65B?

В последнее время многие люди, занимающиеся обучением и выводом больших моделей, обсуждают связь между количеством параметров модели и ее размером. Например, знаменитая серия alpaca больших моделей LLaMA содержит четыре версии с различными размерами параметров: LLaMA-7B, LLaMA-13B, LLaMA-33B и LLaMA-65B.
Буква "B" здесь является сокращением от "Billion", что означает миллиард. Так, самая маленькая модель LLaMA-7B содержит около 7 миллиардов параметров, а самая большая модель LLaMA-65B - около 65 миллиардов параметров.
Итак, как рассчитываются эти параметры? Кроме того, каков приблизительный уровень количества параметров большой модели, соответствующий файлу модели размером 100 ГБ? Миллиарды, десятки миллиардов, сотни миллиардов или триллионы? В данной статье мы подробно ответим на эти вопросы.
I. Методы расчета больших значений параметров модели
Для детального анализа процесса подсчета параметров мы возьмем в качестве примера трансформер, инфраструктуру большой модели.
Стандарт Трансформатор Модель состоит из L одинаковых слоев, уложенных друг на друга, и каждый слой содержит две основные части: слой самовнушения (SAL) и слой нейронной сети с прямой передачей (MLP).
1. Самостоятельное внимание
Механизм самовозбуждения является основой трансформатора. Независимо от того, является ли он самовозбуждающимся или многоголовочным (MHA), расчет количества параметров сердечника одинаков.
В слое самовнимания входная последовательность сначала отображается на три вектора: вектор запроса (Query, Q), вектор ключа (Key, K) и вектор значения (Value, V). В MHA эти три вектора далее разделяются на несколько голов, каждая из которых отвечает за фокусировку на отдельной части входной последовательности.

- Самостоятельное внимание с одной стороны. Q, K, V линейно преобразуются весовой матрицей формы [h, h], где h - размерность скрытого слоя. Таким образом, общее количество параметров Q, K, V составляет 3h². Кроме того, существует слой линейного преобразования для выхода с той же формой весовой матрицы [h, h]. Таким образом, общее количество параметров для одноголового самовнушения составляет 4h² (не обращайте внимания на термин "предвзятость").
- Разнонаправленное внимание (MHA). Предположим, что имеется n_голов, каждая из которых имеет размерность h_head = h / n_head. Каждая голова имеет отдельную весовую матрицу Q, K, V формы [h, h_head]. Таким образом, параметрическая величина весовой матрицы Q, K, V для каждой головки равна 3 * h * h_head = 3h²/n_head. Общее количество параметрических величин для n_head головок равно n_head * (3h²/n_head) = 3h². Наконец, форма матрицы весов линейного преобразования для выходного слоя равна [h, h]. Таким образом, общее количество параметров в MHA также составляет 4h² (не обращайте внимания на термин "предвзятость").
Таким образом, количество параметров в слое самопритяжения можно приближенно считать равным 4h² как для одной, так и для нескольких голов.
2. слой нейронной сети с обратной связью (MLP)
Слой MLP состоит из двух линейных слоев. Первый линейный слой увеличивает размерность скрытого слоя h до 4h, а второй линейный слой уменьшает размерность обратно до h из 4h.

- Весовая матрица первого линейного слоя имеет вид [h, 4h], а количество параметров равно 4h².
- Второй линейный слой имеет весовую матрицу формы [4h, h] с той же параметрической величиной 4h².
Таким образом, общее количество параметров в слое MLP составляет 8h² (без учета члена смещения).
3. Нормализация слоев
После каждого слоя Self-Attention и MLP, а также после последнего слоя с выходом трансформатора обычно выполняется операция Layer Normalisation. Каждый слой Layer Normalisation содержит два обучаемых параметра:
- Параметр масштабирования (гамма): форма - [h].
- Параметр перевода (бета): форма - [h].
Поскольку каждый слой трансформатора имеет две нормализации слоев (после Self-Attention и MLP соответственно) плюс одну после выходного слоя, общее количество параметров нормализации слоев для L-слойного трансформатора составляет (2L + 1) * 2h.
4. Встраивание
Сначала входной текст необходимо преобразовать в векторы слов с помощью слоя встраивания слов. Если предположить, что размер списка слов равен V, а размерность вектора слов - h, то количество параметров слоя встраивания слов равно Vh.
5. выходной слой
Весовая матрица выходного слоя обычно используется совместно со слоем встраивания слов (Weight Tying), чтобы уменьшить количество параметров и потенциально улучшить производительность. Поэтому, если используется совместное использование весов, выходной слой обычно не вводит дополнительного количества параметров. Если же он не разделяется, то число параметров становится Vh.
6. позиционное кодирование
Позиционное кодирование используется для предоставления модели информации о положении слов во входной последовательности.
- Коды позиций для обучения. Если используется обучаемое позиционное кодирование, количество параметров равно N * h, где N - максимальная длина последовательности. Например, максимальная длина последовательности в ChatGPT составляет 4k.
- Код относительной позиции (например, RoPE или ALiBi). Эти методы не вводят обучаемых параметров.
Из-за относительно небольшого количества позиционно закодированных параметров ими обычно пренебрегают при подсчете общего количества параметров.
7. подсчет общего количества участников
Таким образом, общее количество параметров для модели L-слойного трансформатора составляет:
Общее количество параметров = L * (параметр самовнушения + параметр MLP + параметр LayerNorm * 2) + параметр встраивания + параметр выходного слоя + параметр LayerNorm (после выходного слоя)
Общее количество параметров ≈ L * (4h² + 8h² + 4h) + Vh + (опционально Vh) + 2h
Общее количество параметров ≈ L * (12h² + 4h) + Vh + 2h (при условии, что выходной слой имеет общие веса со слоем встраивания слов)
Когда скрытая размерность h велика, первичными членами 4h и 2h можно пренебречь, и число параметров модели может быть аппроксимировано как:
Общее количество участников ≈ 12Lh² + Vh
8. Предполагаемое количество участников LLaMA
В следующей таблице приведены некоторые ключевые параметры различных версий LLaMA и оценки их количества:
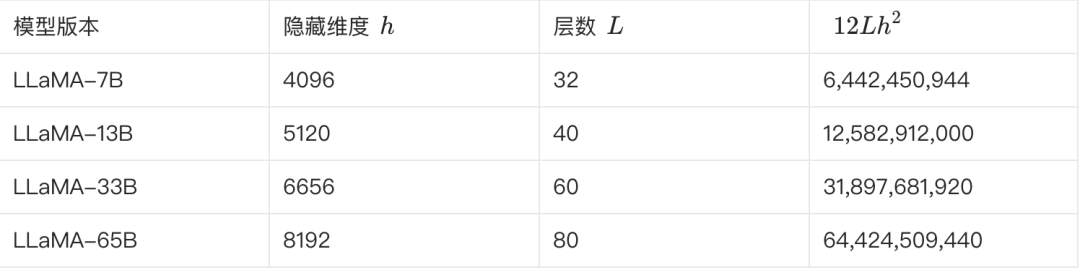
**Мы можем проверить это по приведенной выше формуле. Если взять в качестве примера LLaMA-7B, то, согласно таблице, L=32, h=4096, V=32000.**.
Расчетное количество параметров ≈ 12 * 32 * 4096² + 32000 * 4096 ≈ 6.55B
Эта оценка ближе к 6,7 Б. Подобным образом можно оценить и подтвердить несколько других версий.
II. Преобразование параметрических величин большой модели в размеры модели
Поняв, как вычисляется число параметров, мы рассмотрим, как преобразуются число параметров и размер модели.
В качестве примера мы по-прежнему используем LLaMA-7B, в которой насчитывается около 7 миллиардов участников.
- Теоретические расчеты. Если каждый параметр хранится в формате FP32 (32-битное число с плавающей точкой, занимающее 4 байта), то теоретический размер LLaMA-7B составляет: 7B * 4 байта = 28 ГБ.
- Физическое хранение. Для экономии места и повышения эффективности вычислений веса моделей обычно хранятся в формате с более низкой точностью, например, FP16 (16-битное число с плавающей точкой, занимающее 2 байта) или BF16. При использовании FP16 размер LLaMA-7B теоретически составляет: 7B * 2 байта = 14 ГБ.
- Другие факторы. Помимо весовых параметров, файл модели может содержать информацию о состоянии оптимизатора (например, импульс и дисперсию оптимизатора Адама), списки слов, конфигурации модели и т. д., что может занимать дополнительное место в памяти. Кроме того, некоторые параметры (например, гамма и бета для нормализации слоев) могут храниться в формате FP32.
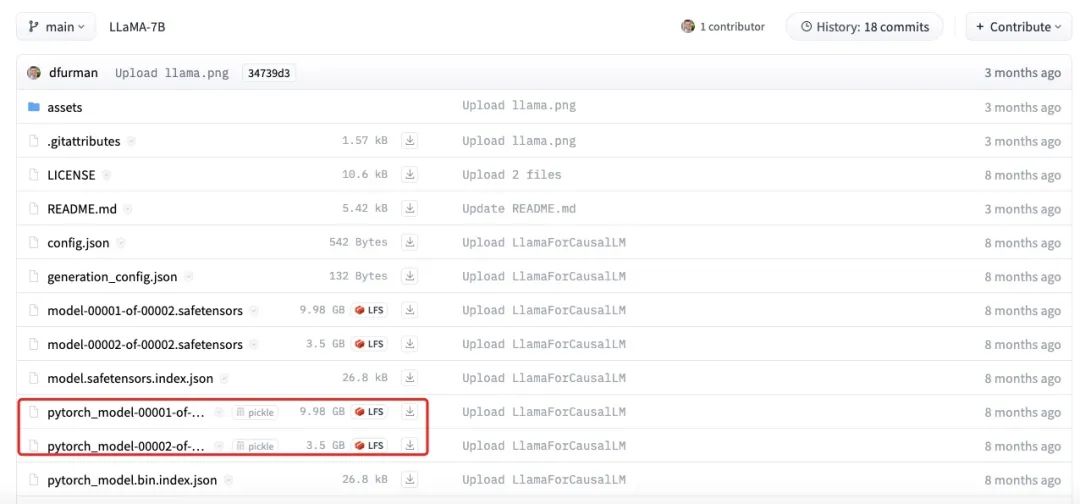
На рисунке выше показан фактический размер файла модели LLaMA-7B. Видно, что общий размер каждой части составляет около 13,5 ГБ, что ближе к нашей оценке в 14 ГБ. Небольшие различия могут быть вызваны ошибками округления, смещением параметров или тем, что некоторые параметры все еще хранятся с использованием FP32.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...