
Как выбрать модель встраивания для создания приложения RAG?

Выбор правильной модели Embedding - важный шаг при построении системы RAG. Здесь я привожу основные факторы и рекомендации по выбору модели Embedding для ознакомления:
Определите сценарии применения
Во-первых, необходимо выяснить конкретные сценарии применения и требования к системе RAG. Например, работает ли она с текстовыми данными, изображениями или мультимодальными данными? Для разных типов данных могут потребоваться разные модели встраивания. Например, для текстовых данных можно обратиться к таблице лидеров HuggingFace's MTEB (Massive Text Embedding Benchmark: коллекция метрик для оценки моделей встраивания текста), чтобы выбрать подходящую модель, или зайти в отечественное сообщество Magic Matching и посмотреть на таблицы лидеров.
Общие и специфические для конкретной области требования
Во-вторых, выбирайте модель в зависимости от общности или специфичности задачи. Если задача, которую вы хотите реализовать, является более общей и не требует слишком большого объема знаний о домене, вы можете выбрать общую модель Embedding; если же задача связана с конкретным доменом (например, юриспруденция, здравоохранение и т. д., образование, финансы и т. д.), вам нужно выбрать модель, которая больше подходит для этого домена.
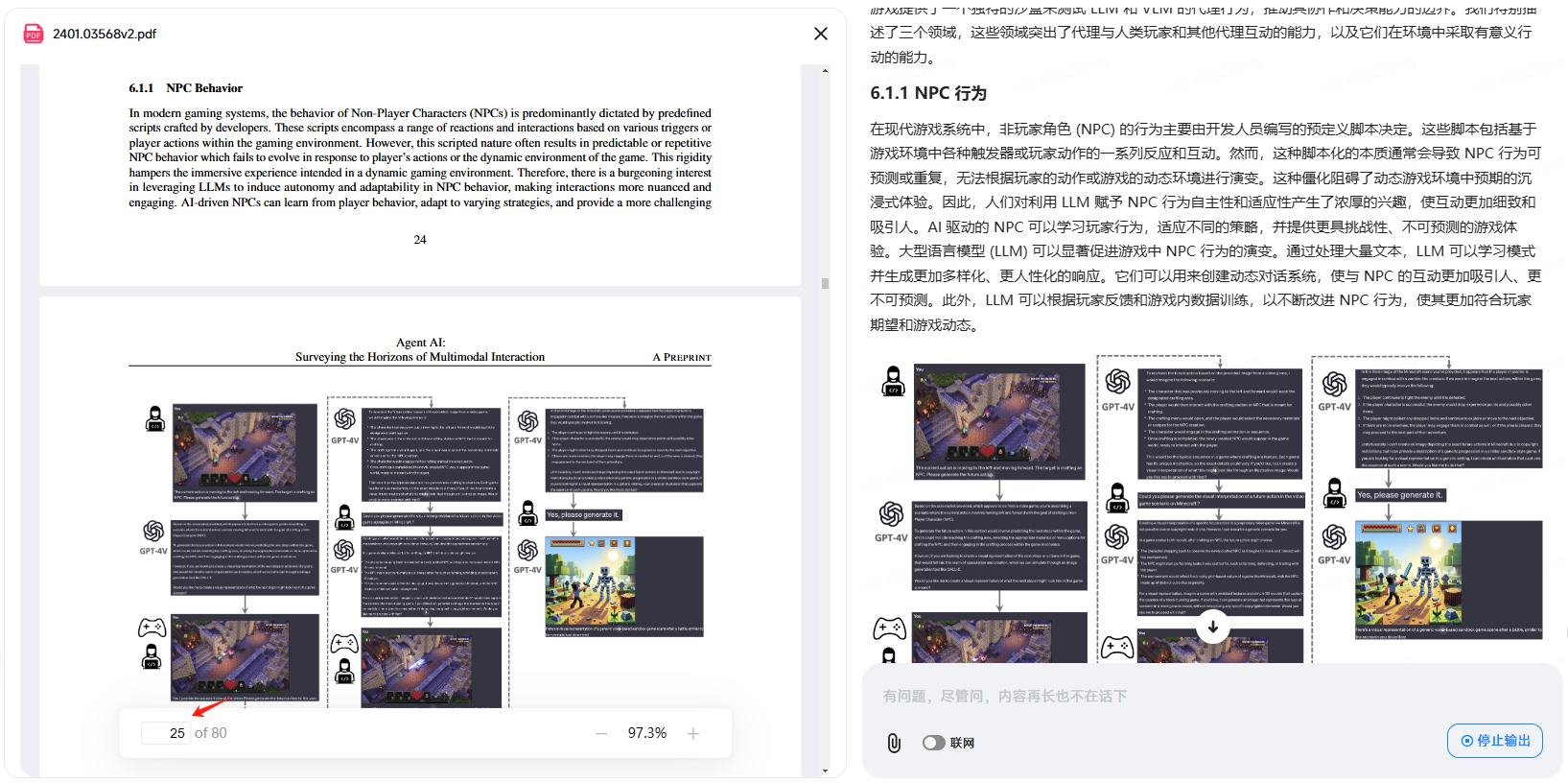
многоязычие
Если содержимое базы знаний существует в вашей системе и вам необходимо поддерживать несколько языков, вы можете выбрать многоязычные модели встраивания, такие как BAAI/bge-M3, bce_embedding (Chinese-English) и т. д., которые лучше работают в многоязычной среде. Если ваша база знаний содержит в основном китайские данные, вы можете выбрать такие модели, как iic/nlp_gte_sentence-embedding_chinese-base и т. д. Эффект будет лучше.
Оценка производительности
Чтобы оценить производительность различных моделей, обратитесь к бенчмаркам, таким как MTEB Leaderboards. Эти бенчмарки охватывают множество языков и типов задач и помогут вам найти модели, лучше всего справляющиеся с конкретными задачами. Далее необходимо учесть размер и ресурсные ограничения модели. Большие модели могут обеспечить более высокую производительность, но они также увеличивают вычислительные затраты и требования к памяти. Кроме того, большие размеры вкраплений обычно обеспечивают более богатую семантическую информацию, но также могут привести к большим вычислительным затратам. Поэтому необходимо взвесить выбор, основываясь на реальных аппаратных ресурсах и требованиях к производительности.
Практические испытания и валидация
Наконец, если это возможно, вы можете выбрать 2-3 модели для сравнения эффектов, протестировать и проверить работу выбранных моделей в реальных бизнес-сценариях, наблюдать за такими метриками, как точность и отзыв, чтобы оценить эффективность моделей на конкретных наборах данных, и внести коррективы на основе полученных результатов.
Рекомендация по внедрению модели
Ниже приведены 5 основных моделей Embedding, рекомендуемых для построения систем RAG в качестве справочной информации:
Встраивание BGEРазработанная Wisdom Source Institute, она поддерживает множество языков и предлагает несколько версий, включая эффективный реранкер. Модель имеет открытый исходный код и свободное лицензирование, и подходит для таких задач, как поиск, классификация и кластеризация.
GTE Embedding: разработанный институтом Alibaba Dharma, основанный на концепции BERT, он применяется в таких сценариях, как поиск информации и оценка семантического сходства с превосходной производительностью.
Jina Embedding: разработан командой Jina AI's Finetuner, обучен на наборе данных Linnaeus-Clean, подходит для поиска информации и оценки семантического сходства с выдающейся производительностью.
Conan-Embedding: это модель встраивания, оптимизированная для китайского языка, которая достигает уровня SOTA (State-of-the-Art) на C-MTEB, и особенно подходит для систем RAG, требующих высокоточного семантического представления китайского языка.
text-embedding-ada-002: Разработанный командой Xenova, он совместим с библиотекой Hugging Face и обеспечивает высококачественные векторные представления текста для широкого спектра задач NLP.
Конечно, существуют также Sentence-BERT, E5-embedding, Instructor и так далее, производительность этих моделей в различных сценариях будет немного отличаться, в зависимости от ваших конкретных потребностей и соображений, которые я перечислил выше, вы можете выбрать подходящую модель для построения системы RAG.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...