Crawl4AI: асинхронный веб-краулер с открытым исходным кодом для извлечения структурированных данных без LLM

Общее введение
Crawl4AI - это асинхронный веб-краулер с открытым исходным кодом, предназначенный для работы с большими языковыми моделями (LLM) и приложениями искусственного интеллекта (AI). Он упрощает процесс сбора и извлечения данных, поддерживает эффективный сбор данных и предоставляет удобные для LLM форматы вывода, такие как JSON, очищенный HTML и Markdown. Crawl4AI поддерживает одновременный сбор нескольких URL-адресов, полностью бесплатен и имеет открытый исходный код, подходит для различных потребностей в сборе данных.
Официальная справочная документация
Список функций
- Асинхронная архитектура: эффективная обработка нескольких веб-страниц, быстрый поиск данных
- Несколько форматов вывода: поддержка JSON, HTML, Markdown
- Ползание по нескольким URL: одновременное ползание по нескольким веб-страницам
- Извлечение медиатегов: извлечение тегов изображений, аудио и видео.
- Извлечение ссылок: извлечение всех внешних и внутренних ссылок
- Извлечение метаданных: извлечение метаданных из страниц
- Пользовательские крючки: поддержка аутентификации, заголовков запросов и модификаций страниц
- Настройка агента пользователя: настройка агентов пользователя
- Скриншот страницы: скриншот страницы ползания
- Выполнение пользовательского JavaScript: выполнение нескольких пользовательских JavaScript перед просмотром
- Поддержка прокси: повышение конфиденциальности и доступности
- Управление сеансами: обработка сложных сценариев многостраничного кроулинга
Использование помощи
Процесс установки
Crawl4AI предлагает гибкие варианты установки для различных сценариев использования. Вы можете установить его как пакет Python или использовать Docker.
Установка с помощью pip
- Базовая установка
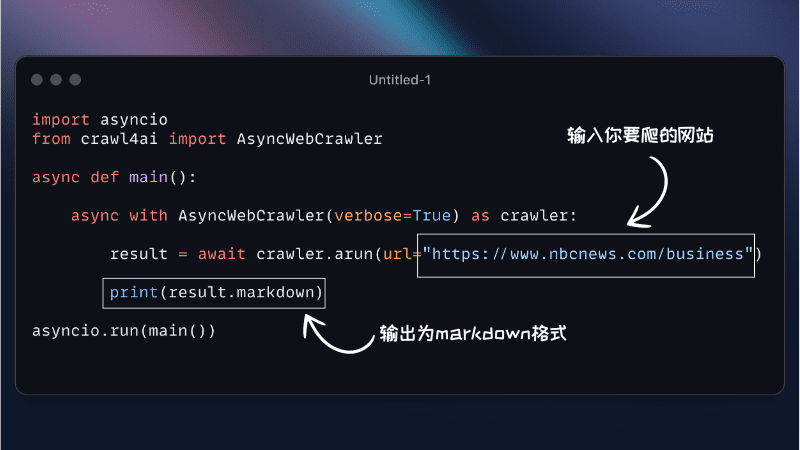
pip install crawl4aiПо умолчанию будет установлена асинхронная версия Crawl4AI, использующая Playwright для веб-ползания.
- Установка Playwright вручную (если требуется)
playwright installили
python -m playwright install chromium
Установка с помощью Docker
- Извлечение образа Docker
docker pull unclecode/crawl4ai - Запуск контейнеров Docker
docker run -it unclecode/crawl4ai
Руководство по использованию
- Основное использование
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"]) print(results) - Пользовательские настройки
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler( user_agent="CustomUserAgent", headers={"Authorization": "Bearer token"}, custom_js=["console.log('Hello, world!')"] ) results = crawler.crawl(["https://example.com"]) print(results) - Извлечение конкретных данных
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"], extract_media=True, extract_links=True) print(results) - Управление сеансами
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() session = crawler.create_session() session_results = session.crawl(["https://example.com"]) print(session_results)
Crawl4AI предлагает богатый набор функций и гибкие возможности настройки для решения различных задач по поиску и сбору данных в Интернете. Благодаря подробным руководствам по установке и использованию пользователи смогут легко начать работу и в полной мере воспользоваться мощными возможностями инструмента.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...