
Сложные рассуждения с большими моделями от OpenAI-o1

В 2022 году OpenAI выпустила ChatGPT, который стал самым быстрым APP в мире, преодолевшим отметку в сотни миллионов пользователей, и тогда люди подумали, что мы приблизились к настоящему ИИ. Но вскоре люди обнаружили, что ChatGPT может вести беседы и даже писать стихи и статьи, но он по-прежнему неудовлетворителен в простой логике, как, например, знаменитая "клубника" с несколькими стеблями "р" в ней.
Теперь, два года спустя, OpenAI выпустила модель o1, которая вызвала бурную дискуссию о методологии, лежащей в ее основе, с ее мощной способностью к логическим рассуждениям и мощной способностью OpenAI скрывать технологии. В этой статье мы проанализировали некоторые смежные статьи, чтобы взглянуть на развитие способности к сложным рассуждениям в больших моделях, используя в качестве ориентира предположения о технологии модели o1.
01 Фон
Цепочка мышления, или сокращенно ЦМ, - это концепция в когнитивной психологии и образовании, которая описывает поэтапный процесс развития мышления людей в процессе решения проблем или принятия решений. Вместо того чтобы просто переходить от вопроса к ответу, этот процесс включает в себя несколько шагов, каждый из которых может включать в себя сбор, анализ, оценку и пересмотр предыдущих выводов. Таким образом, люди способны более систематически подходить к решению сложных проблем и находить рациональные решения.
Supervised fine-tuningSupervised Learning, или контролируемое обучение, - это наиболее распространенная форма обучения моделей в области машинного обучения, использующая наборы данных с метками для обучения модели с целью точной классификации данных или прогнозирования результатов. По мере поступления входных данных в модель контролируемое обучение корректирует весовые коэффициенты модели до тех пор, пока модель не станет адекватной.
Supervised Fine-Tune, или сокращенно SFT, относится к контролируемому обучению, когда мы обучаем модель с набором данных, ориентированных на конкретную задачу, поверх существующей базовой модели, чтобы она могла обучаться на ее основе для решения конкретной задачи.
Обучение с подкреплениемОбучение с подкреплением, или сокращенно RL, - одна из трех основных парадигм машинного обучения, наряду с контролируемым и неконтролируемым обучением. Обучение с подкреплением фокусируется на поиске баланса между исследованием (неизвестное) и эксплуатацией (известное), позволяя моделям обучаться правильному поведению с целью получения максимальной прибыли в долгосрочной перспективе.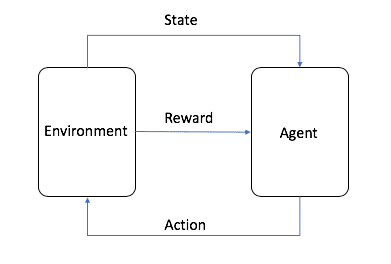
Изображение взято из AWS, как показано на рисунке, в обучении с подкреплением агент является конечной целью, которую нам нужно обучить, и взаимодействует с заданным окружением (Environment) и генерирует вознаграждение и передачу состояния, агент обучается на основе вознаграждения и лучше выбирает следующее действие, так что цикл - это процесс обучения. Этот цикл и есть процесс обучения с подкреплением.
В процессе обучения LLM RL играет важную роль, и уже стало общепринятым в индустрии, что этап предварительного обучения выравнивается с помощью RLHF. В процессе обучения с подкреплением в LLM нам обычно требуется еще одна модель для имитации окружающей среды, чтобы вознаградить выход LLM, которая называется Reward Model, или RM для краткости.
У нас будет несколько моделей: модель Актора, модель Критика и модель Вознаграждения. В соответствии со стандартной схемой обучения RL, описанной выше, Актор и Критик образуют Агента, а Награда обучается как Среда в процессе обучения RL.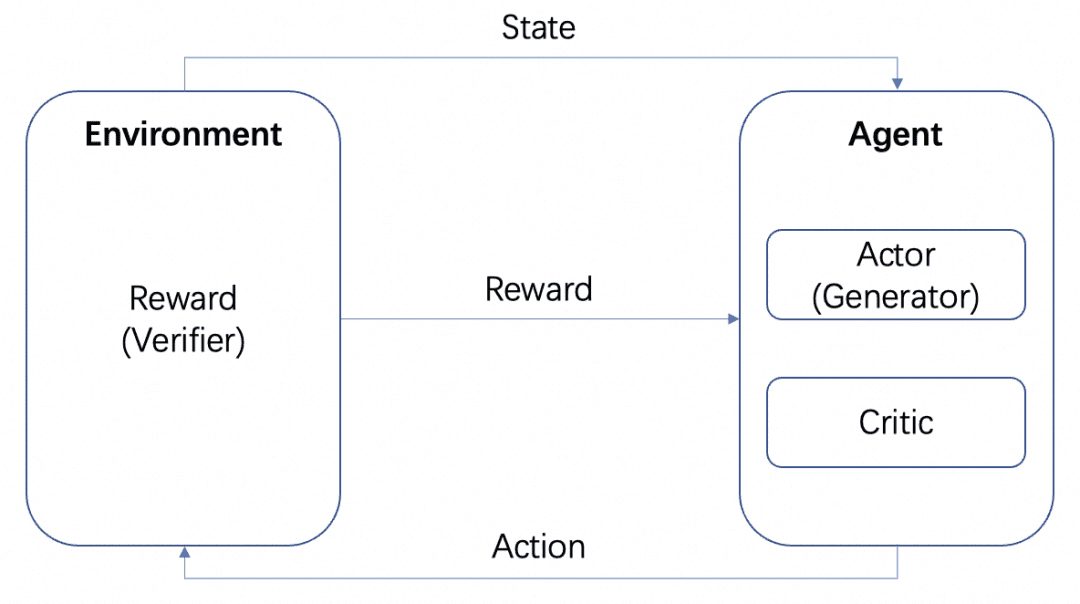
Но после обучения мы можем развернуть модели Actor или Reward отдельно, где модель Actor - это наш генератор, а модель Reward - это верификатор, который мы используем для измерения качества генерации генератора. Это структура Generator-Verifier, о которой OpenAI упоминает в статье Let's verify step by step. Это структура Генератор-Верификатор, о которой OpenAI упоминает в статье Let's verify step by step.
Модели вознаграждения можно разделить на категории в зависимости от того, насколько подробными являются их отзывы:
-Process Based Reward Model PRM: PRM дает обратную связь на основе промежуточных результатов LLM.
-Модель вознаграждения по результатам ORM: ORM дает обратную связь только после достижения конечного результата.
Ниже мы рассмотрим эти две концепции на конкретных сценариях.
Monte Carlo Tree Search Monte Carlo Tree Search, или MCTS, - это алгоритм поиска по дереву, суть которого заключается в том, что на каждом шаге предпринимается несколько попыток поведения и прогнозируется возможная будущая отдача от этих попыток, при этом основное внимание уделяется выборочному исследованию некоторых из наиболее выгодных вариантов поведения.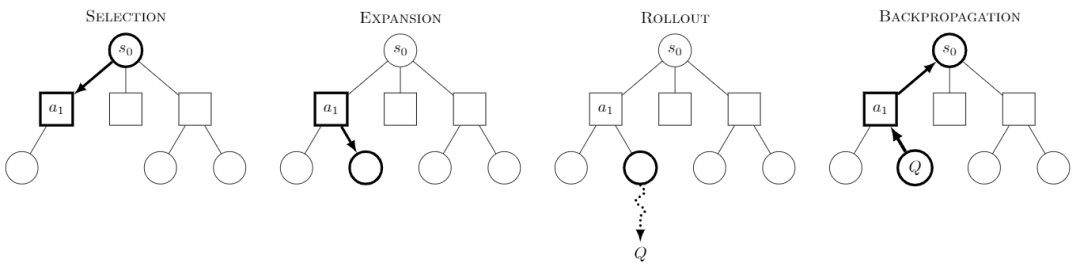
Изображение из Википедии. Считается, что каждый квест состоит из четырех этапов:
-Выбор: выбрать узел
-Расширение: генерирует новый узел из данного узла для исследования
-Развернуть: выполнить моделирование вдоль этого нового узла, чтобы получить результат
-Обратное распространение: результаты моделирования распространяются в обратном направлении, обновляя узлы на путях.
Непрерывно исследуя дерево, мы получаем дерево, каждый узел которого содержит возможный результат исследования, и мы можем искать в этом дереве, чтобы получить наилучший путь или результат.
В рамках MCTS для RL были созданы такие известные модели, как AlphaZero, которая выполняет шаги Selection и Rollout с использованием обучаемых моделей, что позволяет сократить большое пространство поиска и стоимость моделирования MCTS для эффективного получения оптимального решения. Подход AlphaZero заключается в использовании обучаемых моделей для выполнения шагов Selection и Rollout, что позволяет сократить большое пространство поиска и стоимость моделирования MCTS для эффективного получения оптимального решения, например, использование Policy Network для эффективного поиска следующего возможного шага и использование Value Network для определения стоимости каждого шага вместо моделирования Rollout.
Способность o1 к многоступенчатым рассуждениям Когда речь заходит о модели o1, мы должны сказать о ее удивительной способности к многоступенчатым рассуждениям, и на сайте OpenAI приводится несколько примеров, демонстрирующих ее способность к многоступенчатым рассуждениям в паролях, кодах, математике, кроссвордах и т. д. Пример, связанный с "паролями", - это "THERE ARE THREE R'S IN STRAWBERRY", который также является хорошим примером того, как он раньше расшифровывался. В примере, связанном с "паролем", результатом расшифровки является "THERE ARE THREE R'S IN STRAWBERRY", что также является результатом когда-то существовавшего "пароля". ChatGPT Способность к аргументированному ответу.
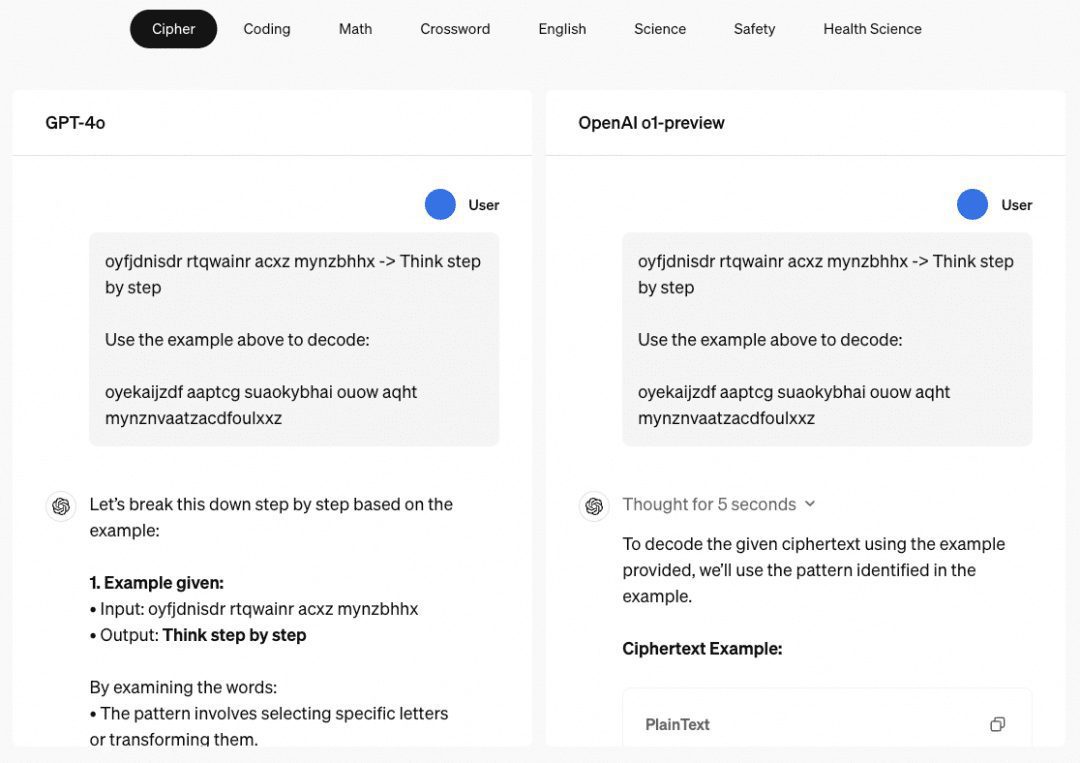
Поэтому мы изучили ряд работ, главным образом в этом качестве, которые были собраны и обобщены, как описано ниже.
02 Инженерное слово
В настоящее время для обучения ИИ обычно требуется большое количество примеров, в то время как обучение на очень малом количестве примеров называется Few-Shot или Zero-Shot, если примеры вообще не даются.
В статье "Chain of Thought Prompting Elicits Reasoning in Large Language Models" предлагается подход Few-Shot для улучшения математического обоснования моделей:
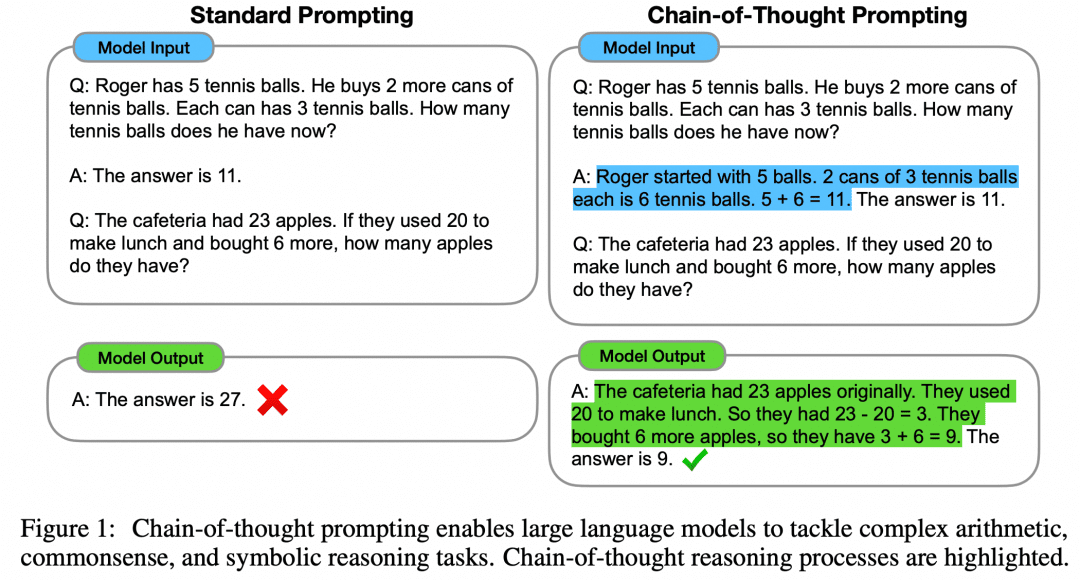
Как показано на рисунке, левая сторона дает LLM образец для обучения в подсказке ввода LLM, что является Few-Shot Learning, но его эффект все еще неудовлетворителен. В статье предлагается парадигма Few-Shot с CoT на правой стороне. Таким образом, справа в Few-Shot даются не только вопрос и ответ на пример, но и промежуточный процесс и результат. Авторы обнаружили, что построенный таким образом Few-Shot Prompt с использованием CoT улучшает вывод модели.
По мере совершенствования самой модели и проведения дополнительных исследований в статье "Large Language Models are Zero-Shot Reasoners" выясняется, что Zero-Shot также может использовать CoT для расширения возможностей модели:

Вместо того чтобы заниматься разработкой промежуточного процесса CoT или даже конструированием примеров для Few-Shot, простое "Давайте думать шаг за шагом" может улучшить LLM. Звучит как несерьезно. Позднее этот призыв был подхвачен и изменен OpenAI на "Let's verify step by step", и теперь эта статья является основой для многократного чтения всеми, кто хочет понять o1.
Конечно, построение CoT только на инженерии слов-ключей не может быть причиной того, что o1 настолько мощный, но CoT, пошаговый подход к развитию логики, стал доминирующим направлением для дополнения рассуждений в больших моделях.
03 CoT + контролируемая точная настройка
Конечно, уже были попытки научить LLM многоступенчатым рассуждениям CoT с помощью SFT. "STaR: Bootstrapping Reasoning With Reasoning" - это ранняя попытка. Изображение ниже взято из этой работы: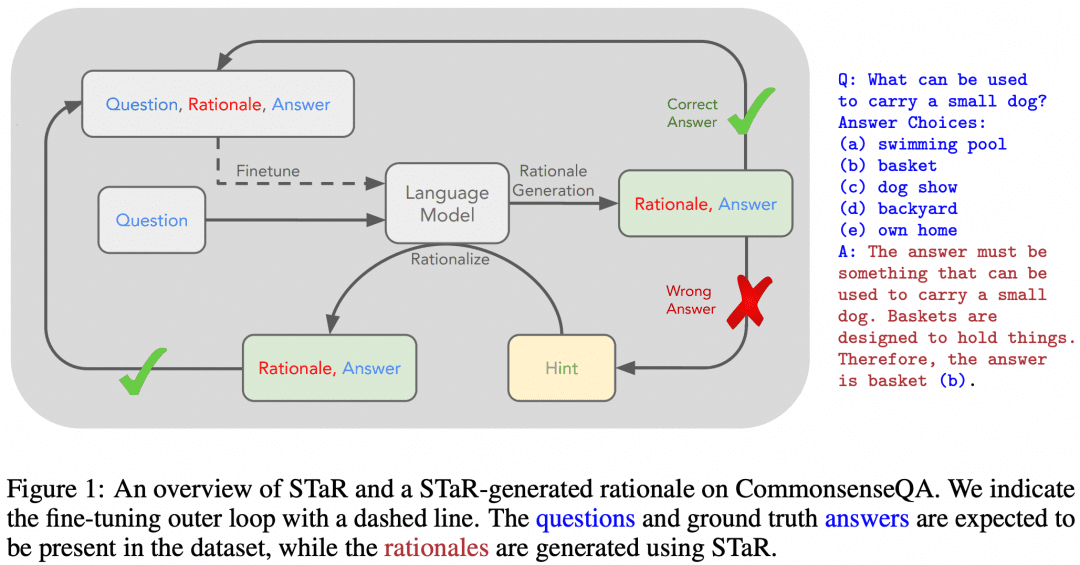
Идея статьи заключается в следующем. Сначала мы используем подход к конструированию слов, описанный выше, чтобы заставить модель попробовать CoT для рассуждения над набором данных, в результате чего будет получена партия ответов, в которой, естественно, будут как правильные, так и неправильные ответы:
Если мы получаем правильный ответ, мы считаем соответствующий CoT, сгенерированный моделью, высококачественным CoT, затем собираем такие высококачественные образцы "вопрос-CoT-ответ", чтобы получить новый набор данных, и используем этот набор данных для SFT нашего LLM, и, продолжая циклический процесс, мы можем получить LLM с лучшей способностью к рассуждению. LLM;
Если есть вопросы, на которые LLM всегда отвечает неправильно, то мы напрямую даем LLM увидеть "Вопрос+Ответ", и пусть он генерирует CoT от вопроса к ответу, и мы можем считать, что CoT, сгенерированный LLM, правильный, когда ответ известен, и эта часть образца "Вопрос-CoT-Ответ" также может быть использована для обучения. Образец "Вопрос-КоТ-Ответ" также может быть использован для обучения.
Поскольку это исследование довольно старое, сейчас в нем легко найти лазейки, например, в LLM часто встречается "неправильный процесс, но правильный результат" или "правильный процесс, но неправильный результат", что означает, что образцы, которые мы использовали для обучения выше, на самом деле не такого уж высокого качества. Это означает, что образцы, которые мы использовали для обучения, на самом деле не так уж и качественны. Как же получить более корректный процесс умозаключения?
04 Поиск по дереву Монте-Карло
Выше мы узнали, что CoT разбивает логику от вопроса к ответу на промежуточный мыслительный процесс за промежуточным мыслительным процессом, так можно ли использовать MCTS для поиска лучшего мыслительного шага для следующего шага рассуждения, а значит, и лучшей цепочки мыслительных рассуждений? Естественно, да.
Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers разработали такой алгоритм MCTS, названный rStar, и разместили проект на GitHub. Изображение ниже взято из статьи, и не правда ли, оно имеет некоторое сходство с изображением MCTS выше?
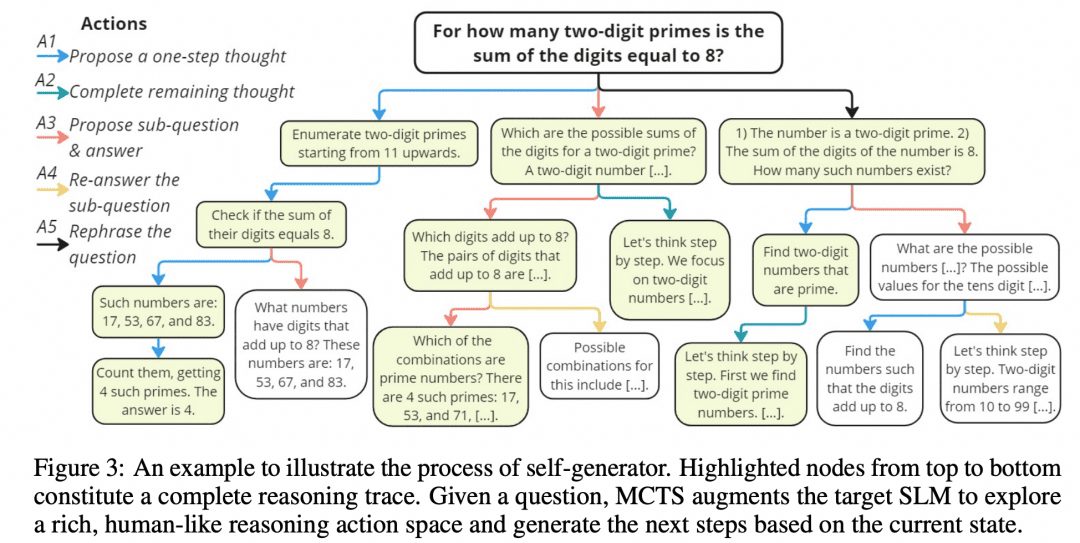
Как показано на рисунке выше, исследователи разделили промежуточные этапы CoT на 5 типов узлов:
1. Создание следующих шагов в рассуждениях
2. создайте все последующие рассуждения
3. Создайте подвопрос и ответ на него
4. повторный ответ на подвопросы
5. вопросы реконфигурации
Затем MCTS используется для определения следующего узла мыслительного шага. Путь, связанный узел за узлом размышлений, и есть CoT. Мы просто берем все полученные конечные результаты и голосуем по ним.
Конечно, авторы изучили не только это, как уже говорилось выше, необходимо иметь возможность измерять корректность узлов и правильность рассуждений на каждом шаге, и исследователи разработали следующий метод:
-Дискриминантная фильтрация: после получения оригинального пути вывода, случайным образом маскируем его часть, а затем используем другую модель для вывода, если получаем тот же результат, что и оригинальный генератор, значит, оригинальный путь вывода надежен.
-Корректность ответов: собираются все окончательные ответы, и доля конкретного ответа от всех ответов является баллом ответа.
-Корректность процесса: для каждого узла рассуждений в пути параллельно генерируется несколько узлов типа 2 для получения одношаговых конечных результатов, и доля этих результатов, являющихся конечным результатом текущего пути, рассматривается как оценка процесса этого узла рассуждений. Трехкомпонентная мера приводит к оптимальному пути, а конечный результат оптимального пути рассматривается как результат MCTS.
05 Генератор + верификатор
Помимо вышеупомянутой MCTS, которая позволяет организовать мыслительные процессы в деревья и исследовать их, существуют и другие способы сделать это. Например, обучение с подкреплением, и мы снова обратимся к введению в обучение с подкреплением: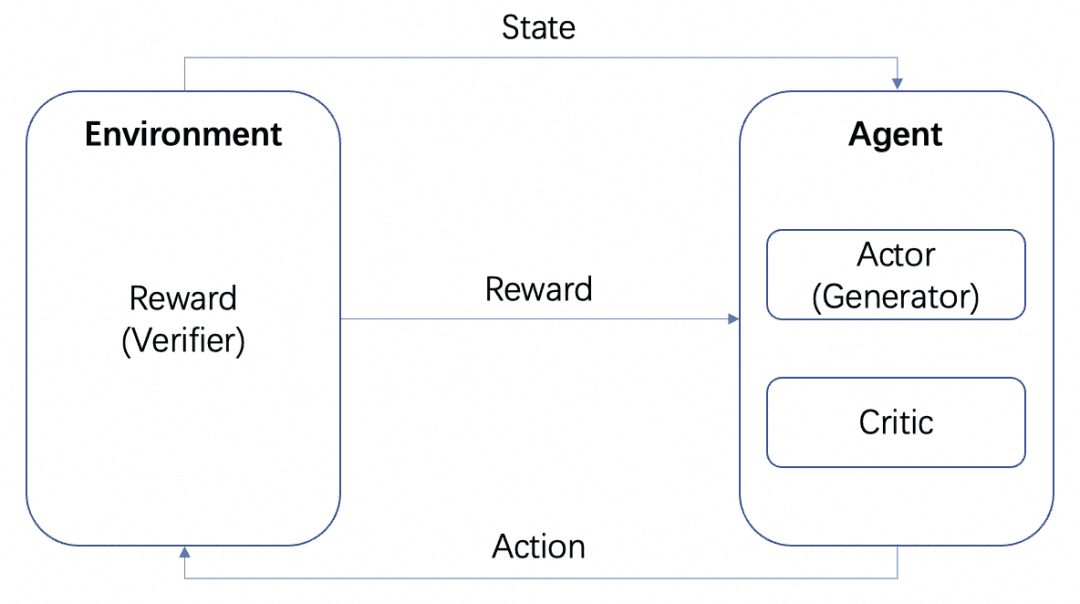
Если мы возьмем LLM в качестве Актора, другой RM, обученный на проблеме, в качестве Окружения, и неявного Критика, то цикл обучения с подкреплением будет выглядеть следующим образом: Актор выдает результат для проблемы, RM проверяет правильность результата и передает его Агенту, а Актор и Критик обучаются в соответствии с вознаграждением. Актор и Критик обучаются на основе награды. Мы называем Агента Генератором, поскольку его задача - генерировать результаты, а РМ - Верификатором, поскольку его задача - проверять результаты.
Если задуматься, разве отношения между Актором и Критиком внутри Агента не похожи на сеть Политики и Ценности, используемую AlphaZero? Также верно, что сети политики и ценностей вписываются в рамки Актора и Критика.
Теперь мы подытожим, что в процессе обучения с подкреплением участвуют три сети: Actor, Critic и RM. В развертывании используются различные фреймворки в зависимости от ситуации: в настольной игре победитель может быть известен только в конце игры, а награда, выдаваемая RM, слишком мала, поэтому мы решили сохранить фреймворк Actor-Critic в развертывании, а затем провести MCTS для поиска лучшего решения; в развертывании LLM наш обученный RM может обеспечить своевременную обратную связь, поэтому мы можем естественно объединить Actor и RM в фреймворк Generator-Verifier в развертывании. В развертывании LLM наш обученный RM может обеспечить своевременную обратную связь, поэтому мы можем естественным образом объединить Actor и RM в фреймворк Generator-Verifier во время развертывания.
OpenAI работает в этом направлении еще со времен GPT3 (ChatGPT основан на модели GPT-3.5). Их решением стала статья Training Verifiers to Solve Math Word Problems. Изображение ниже взято из этого документа:
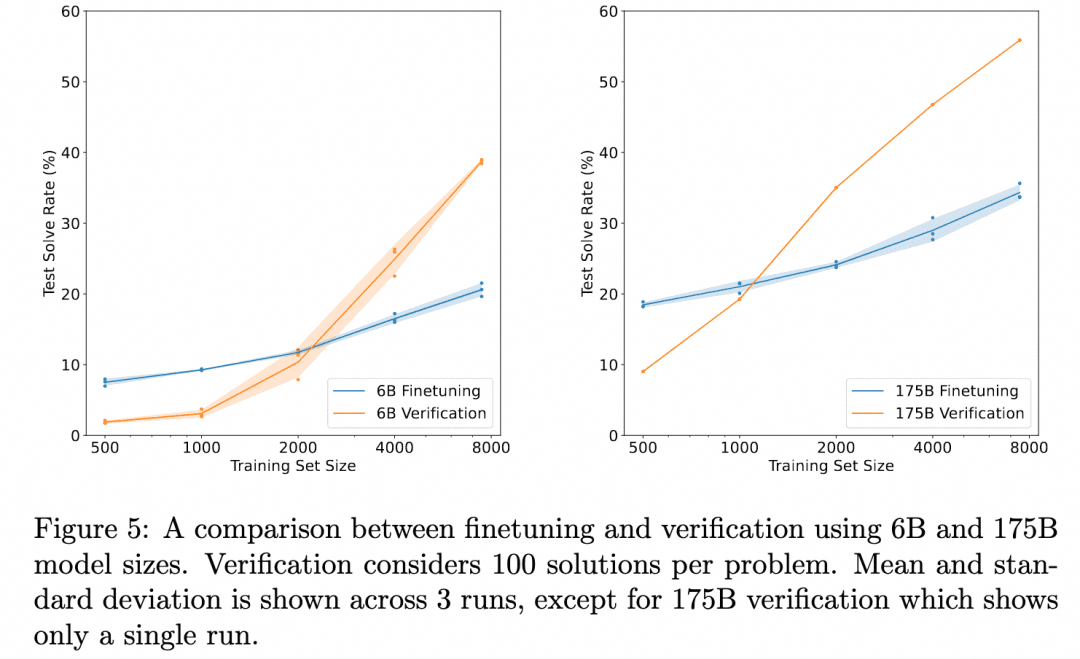
На приведенном выше графике сравниваются "Корректность результатов, полученных при простой настройке Генератора" и "Корректность результатов, полученных при тонкой настройке Верификатора, оценке нескольких результатов, полученных Генератором, и выборе более высоко оцененного результата". Это демонстрирует эффективность верификатора.
Это связано с тем, что задача здесь состоит в том, чтобы, рассуждая над проблемой, получить результат. Таким образом, используемый Генератор не производит промежуточного процесса рассуждений, а выдает результат напрямую, а Верификатор - это ORM (Outcome Based Reward Model), о которой мы упоминали в разделе "Обучение с подкреплением" и которая служит для получения оценки на основе результата Генератора. Таким образом, здесь нет многоступенчатого процесса умозаключений, который мы хотели бы изучить, а есть лишь открытие того, что проверка ORM дает лучшие конечные результаты, чем простая тонкая настройка.
Поэтому команда OpenAI пошла дальше: с одной стороны, они заставили Генератор больше не выдавать результаты напрямую, а вместо этого производить пошаговые рассуждения; с другой стороны, они обучили PRM (Process-based Reward Model) действовать в качестве верификатора, роль которого заключается в том, чтобы выставлять оценки за каждый шаг в процессе рассуждений Генератора. Мы считаем, что результаты, полученные в результате стремления к корректности процесса рассуждений Генератора таким образом, с наибольшей вероятностью будут правильными.
Это работа Let's verify step by step, о которой мы упоминали выше. В этой работе команда сравнила результаты умозаключений, полученные при поиске одного и того же генератора с PRM и ORM в качестве верификаторов (на тот момент их генератор уже был GPT-4), и доказала, что PRM в качестве верификатора ищет более точные результаты. Рисунок ниже взят из статьи:
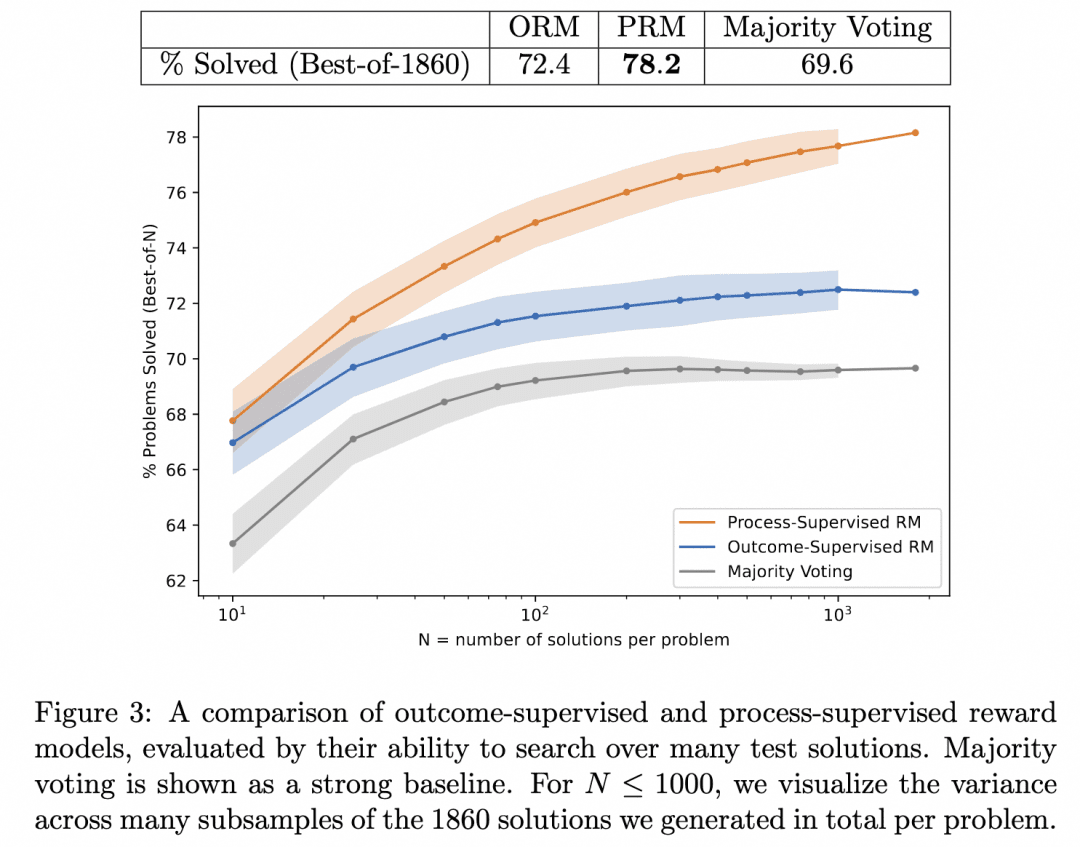
На рисунке выше показано, что один и тот же генератор пошаговых выводов дает результаты, в которых мы можем использовать ORM в качестве верификатора, чтобы выбрать лучший ответ для результата, но мы с большей вероятностью будем правы, если используем PRM в качестве верификатора, чтобы выбрать лучший ответ для процесса!
Это та технология, которая лежит в основе o1 и которую мы ищем? На данный момент мы можем только догадываться, что это одна из основных технологий, лежащих в ее основе. Причины этого следующие:
1, эта статья относительно далека от релиза o1, и один год - достаточный срок для того, чтобы исследователи OpenAI углубились в это направление. Поскольку PRM не теряет своей актуальности, хотя одного года также достаточно, чтобы приспособиться к другим направлениям, мы все же считаем, что они углубляются, а не разворачиваются.
2. в статье демонстрируется эффективность PRM в качестве верификатора, и очевидно, что следующим шагом могло бы стать улучшение генератора с помощью мощного верификатора для получения лучших результатов. Но в статье об этом ничего не говорится, так что у нас есть основания полагать, что OpenAI наверняка пыталась это сделать, и неясно, был ли результат o1.
С этими догадками покончено, давайте перейдем к изучению других способов использования Verifier для поиска. Статья "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters" из Google DeepMind, опубликованная в августе этого года, содержит более подробное исследование. Многие считают, что эта статья демонстрирует схожую техническую линию с принципами, лежащими в основе o1. Изображение ниже - из этой статьи:
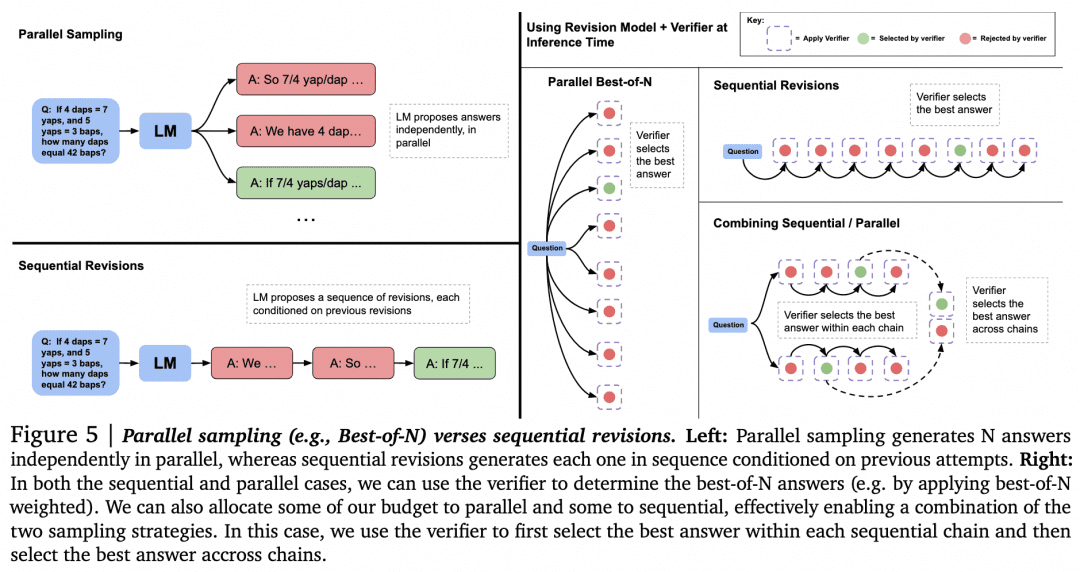
Теперь, когда у нас есть Генератор и Верификатор, как заставить их работать друг с другом, чтобы получить наилучшие результаты? Один из способов сделать это, как упоминалось выше, заключается в том, чтобы Генератор делал параллельные выборки для получения нескольких результатов, а Верификатор оценивал их и выбирал наивысший балл. Это подход Parallel Sampling + Best-of-N, показанный слева на рисунке выше. Но, очевидно, существуют и другие подходы:
-При генерации нескольких результатов, помимо параллельной выборки нескольких результатов, Генератор также может сгенерировать результат, а затем проверить и исправить сам результат, чтобы получить последовательность ответов, в которой они уже не будут параллельны друг другу.
-Возможны альтернативы Best-of-N, когда выбор осуществляется верификатором. Как показано на следующем рисунке из статьи:
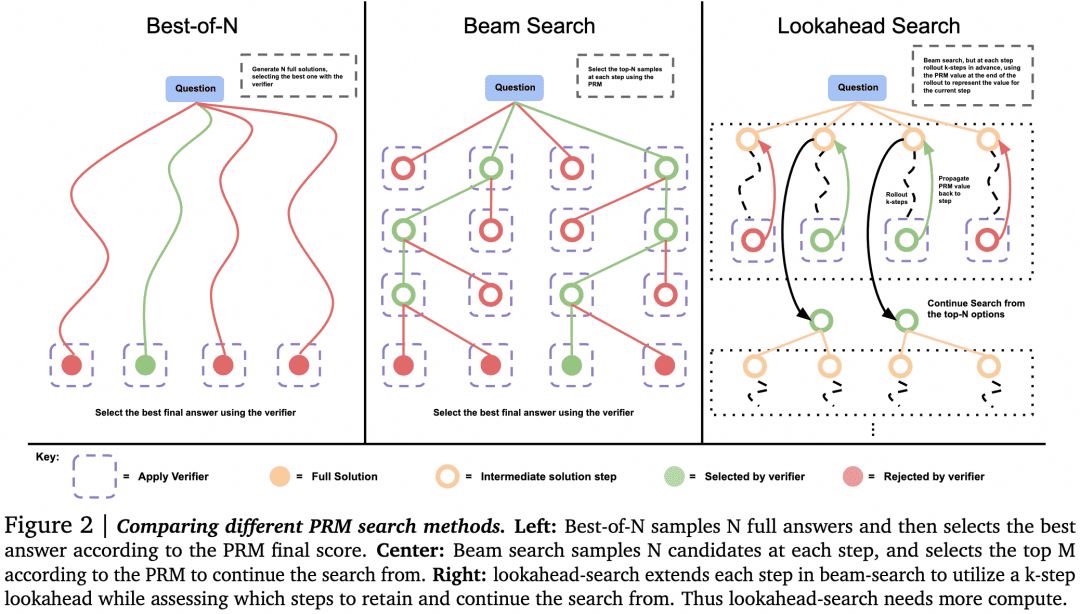
В работе установлено, что для простых задач следует использовать Verifier, чтобы побудить Generator к самопроверке и исправлению, а не к слепому параллельному поиску. Для сложных проблем лучше, чтобы Generator параллельно пробовал разные решения.
Похожая работа - A Comparative Study on Reasoning Patterns of OpenAI's o1 Model. Команда авторов статьи выложила на GitHub Open-o1, копию o1, и эта статья является результатом некоторых исследований, проведенных ими после выпуска o1. Изображение ниже взято из статьи:
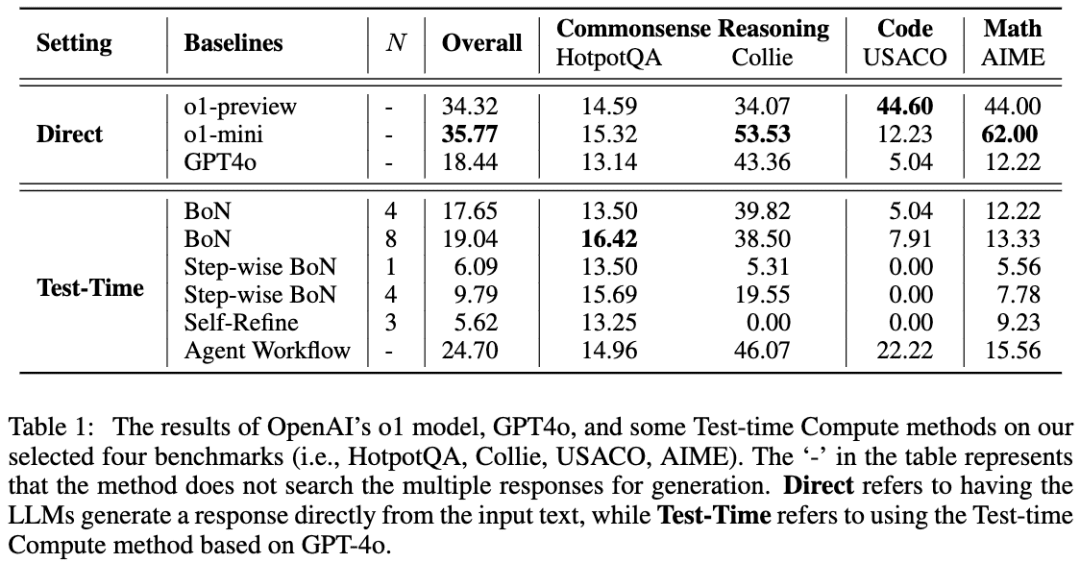
Команда использовала GPT-4o в качестве скелетной модели, а затем сравнила результаты, используя четыре распространенных подхода к тому, как заставить LLM думать перед рассуждениями. Команда обнаружила, что в задаче HotpotQA оба подхода - Best-of-N и Step-wise BoN - смогли значительно улучшить рассуждения LLM, а BoN даже заставил GPT-4o превзойти модель o1.
06 OpenR
Из современных проектов с открытым исходным кодом, которые пытаются повторить o1, OpenR - один из относительно хорошо выполненных.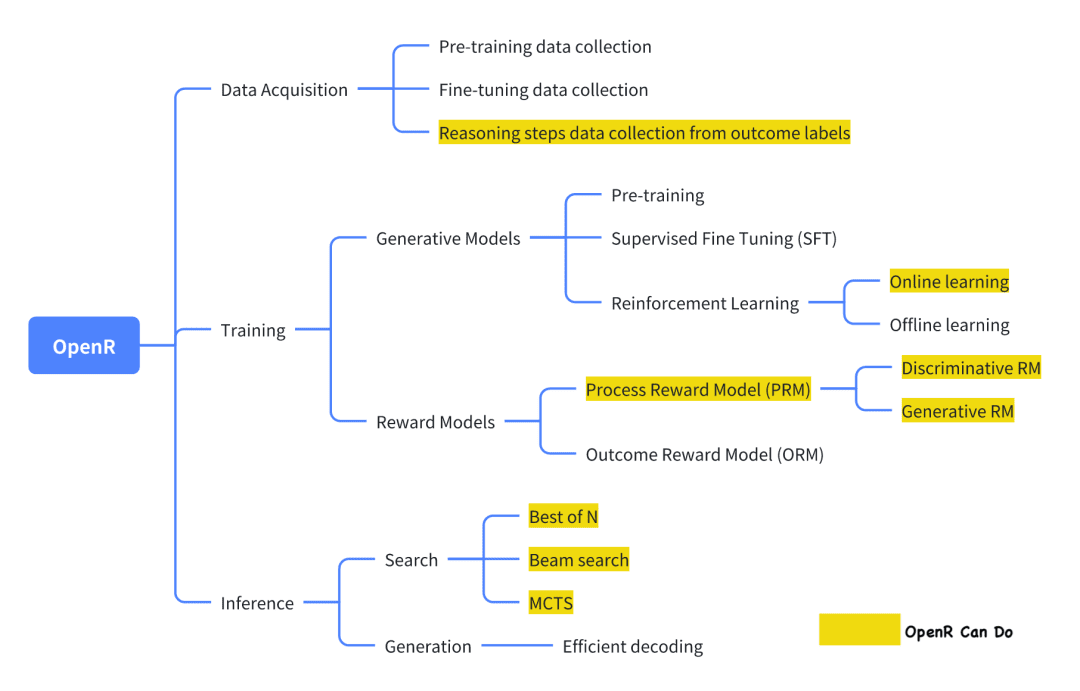
Изображение взято из официальной документации, в которой в соответствии с фреймворком Generator-Verifier реализован сбор данных, а также обучение и развертывание.
Сбор данных Согласно официальному представлению, метод сбора данных взят из статьи: "Улучшение математического обоснования в языковых моделях с помощью автоматизированного наблюдения за процессом". Вкратце, он заключается в использовании MCTS для расширения исходного набора данных problem-final_answer для генерации шагов вывода CoT. В итоге получается набор данных MATH-APS.
Соответствующие наборы данных были размещены на ModelScope:
Набор данных PRM800K-Stepwise:
https://modelscope.cn/datasets/AI-ModelScope/openai-prm800k-stepwise-critic/
Набор данных MATH-APS:
https://modelscope.cn/datasets/AI-ModelScope/MATH-APS/
Набор данных Math-Shepherd:
https://modelscope.cn/datasets/AI-ModelScope/Math-Shepherd
Команда обучения Генератора использует вариант алгоритма PPO из обучения с подкреплением для обучения Генератора. Вкратце, алгоритм PPO использует информацию о вознаграждении, предоставляемую моделью вознаграждения, для обучения Генератора, и в то же время ограничивает Актора, чтобы он не слишком отклонялся от оригинального Актора во время процесса обучения, чтобы избежать потери существующих знаний. В настоящее время OpenR поддерживает три варианта: APPO, GRPO и TPPO.
Команда разработчиков Virifier использовала метод контролируемого обучения SFT для обучения PRM, используя вышеупомянутый набор данных MATH-APS, а также два набора данных с открытым исходным кодом, PRM800K и Math-Shepherd. В частности, в этих трех наборах данных на уровне шагов команда помечала каждый шаг меткой "+" или "-", а затем заставляла PRM учиться предсказывать метку каждого шага и определять, является ли она правильной или неправильной.
Модель использует "ступенчатые" данные для обучения PPO, а полученные веса модели были размещены в ModelScope, который в настоящее время предоставляет контрольные точки для моделей SFT, PRM и RL, а также некоторых форматов GGUF:
Модель mistral-7b-sft:
https://modelscope.cn/models/AI-ModelScope/mistral-7b-sft
Модель RL (версия GGUF):
https://modelscope.cn/models/QuantFactory/math-shepherd-mistral-7b-rl-GGUF
Моделирование PRM:
-ВерсияGGUF: https://modelscope.cn/models/QuantFactory/math-shepherd-mistral-7b-prm-GGUF
-PRM модель: https://modelscope.cn/models/AI-ModelScope/math-shepherd-mistral-7b-prm
Развертывание рассуждений Во время развертывания OpenR использует алгоритмы поиска через указанные Генератор и Верификатор для получения процесса рассуждений и окончательного ответа. В настоящее время поддерживаются MCTS, Beam Search и best_of_n.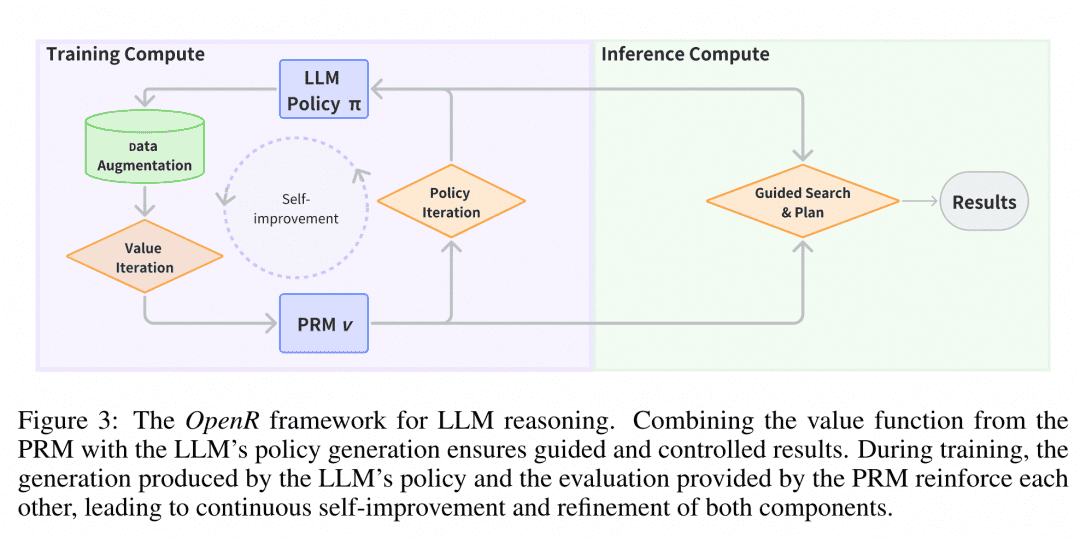
Структура OpenR показана на рисунке, и на данный момент OpenR реализует копию цепочки O1: от сбора обучающих данных до обучения PRM, использования PRM для усиления обучения и, наконец, развертывания модели. В настоящее время OpenR реализует цепочку, повторяющую цепочку O1, от сбора обучающих данных, обучения PRM, использования PRM для усиления обучения и развертывания модели для поиска, и команда сделала всю эту работу с открытым исходным кодом, чтобы сообщество могло учиться и пробовать, так что мы можем получить представление.
Опыт работы в творческом пространствеМы развернули службу выводов OpenR в творческом пространстве сообщества Magic Hitch, и разработчики могут ознакомиться с эффектами OpenR в режиме онлайн, пройдя по следующей ссылке: https://www.modelscope.cn/studios/modelscope/OpenR_Inference.
07 Заключение
Рассмотренные нами выше работы о многошаговых рассуждениях показывают, что если позволить LLM рассуждать пошагово, а не пропускать промежуточные процессы, это может значительно повысить его точность при решении логических задач. Чтобы позволить LLM рассуждать шаг за шагом, мы можем точно настроить его, используя некоторые наборы данных с промежуточными процессами, в дополнение к тому, чтобы направлять его с помощью простой инженерии слов-подсказок. Более эффективно обучать верификатор, который может пошагово проверять точность Генератора для поиска результатов, сгенерированных Генератором.
Судя по догадкам и документам, вероятная технология перехода к o1 основана именно на сотрудничестве между мощным генератором LLM и верификатором LLM. Подобные самоитерации "левая нога на правую ногу" не впервые встречаются в глубоком обучении, но OpenAI впервые вводит такую модель в область LLM, которая очень дорога только для обучения Генератора, что является действительно большой проблемой.
Поэтому мы считаем, что если мы хотим воспроизвести o1, то в первую очередь нам нужен верификатор, который может оказать помощь и подсказать генератору, а чтобы сгенерировать данные, необходимые для обучения верификатора, мы можем обратиться к главам CoT + Supervised Fine-Tune и Monte Carlo Tree Search выше, чтобы получить данные более высокого качества по низкой цене. Чтобы получить данные, необходимые для обучения верификатора, можно обратиться к главам CoT + Supervised Fine-Tune и Monte Carlo Tree Search, описанным выше, для получения данных более высокого качества с меньшими затратами. Именно поэтому мы также представили эти задачи.
Наконец, мы представили готовый проект с открытым исходным кодом, и на основе их работы смогли упорядочить свои мысли и идеи.
08 Ссылка
Цепочка мыслей побуждает к рассуждениям в больших языковых моделях
Большие языковые модели - это рассуждения с нулевым выстрелом
STaR: Bootstrapping Reasoning With Reasoning
Взаимное рассуждение делает маленькие LLM более сильными решателями проблем
Обучение верификаторов решению словесных задач по математике
Давайте проверим шаг за шагом
Оптимальное масштабирование вычислений времени тестирования LLM может быть более эффективным, чем масштабирование параметров модели
Сравнительное исследование моделей рассуждений модели o1 от OpenAI
OpenR: фреймворк с открытым исходным кодом для расширенных рассуждений с использованием больших языковых моделей
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...