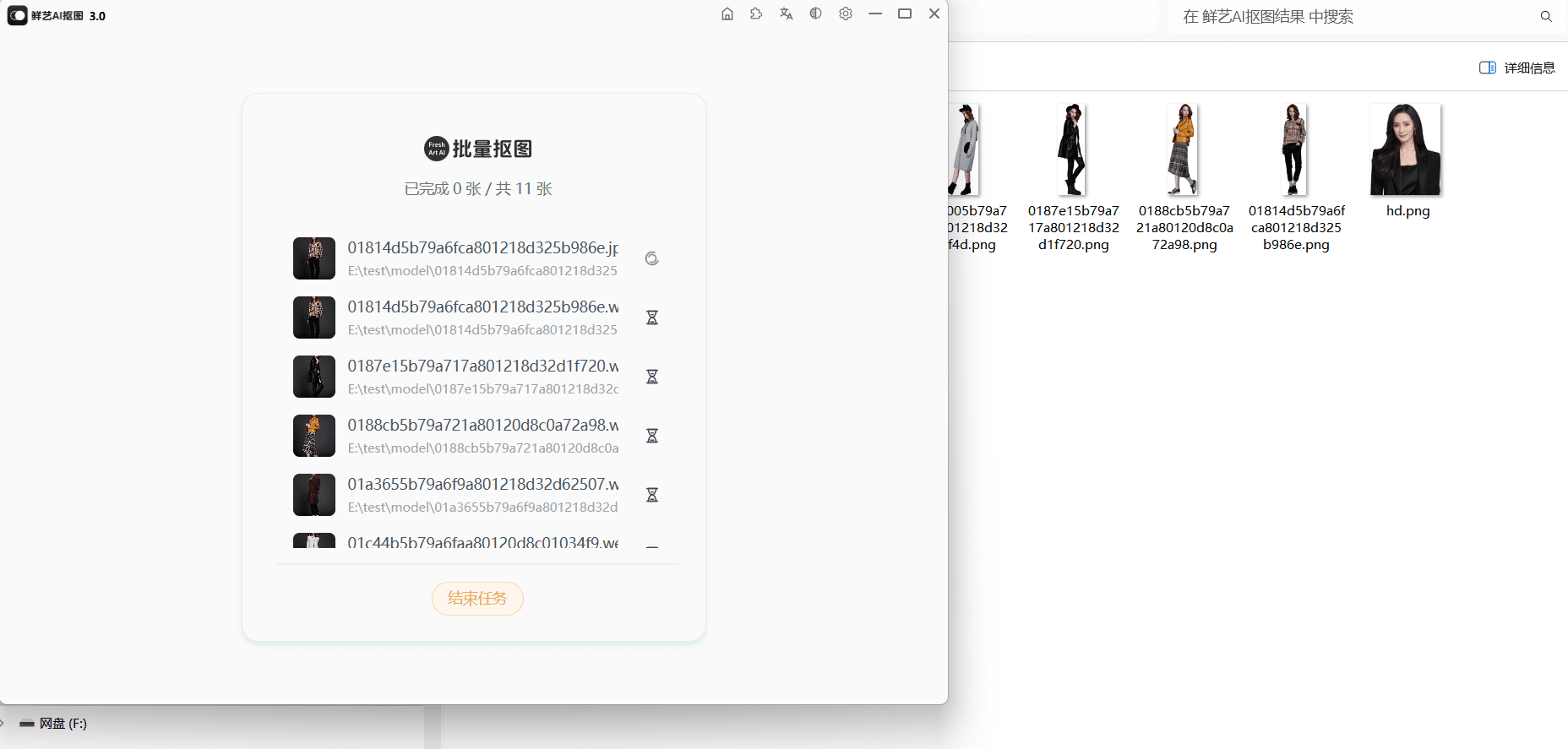
CogVLM2: мультимодальная модель с открытым исходным кодом для поддержки понимания видео и многораундового диалога

Общее введение
CogVLM2 - мультимодальная модель с открытым исходным кодом, разработанная исследовательской группой Tsinghua University Data Mining Research Group (THUDM), основанная на архитектуре Llama3-8B и призванная обеспечить производительность, сравнимую или даже превосходящую GPT-4V. Модель поддерживает понимание изображений, многораундовый диалог и понимание видео, способна обрабатывать контент длиной до 8K и поддерживать разрешение изображений до 1344x1344. Семейство CogVLM2 состоит из нескольких подмоделей, оптимизированных для различных задач, таких как текстовые вопросы и ответы, вопросы и ответы к документам и видео. Модели не только двуязычны, но и предлагают разнообразные онлайн-опыты и методы развертывания, которые пользователи могут протестировать и применить.
Сопутствующая информация:Как долго видео может быть понятно большой модели? Smart Spectrum GLM-4V-Plus: 2 часа
Список функций
- графическое понимание: Поддержка понимания и обработки изображений высокого разрешения.
- многоуровневый диалог: Возможность ведения диалога в несколько раундов, подходит для сложных сценариев взаимодействия.
- Видеопонимание: Поддерживает понимание видеоматериалов длиной до 1 минуты путем извлечения ключевых кадров.
- Поддержка нескольких языков: Поддержка китайского и английского билингвизма для адаптации к различным языковым средам.
- открытый исходный код (вычислительная техника): Полный исходный код и весовые коэффициенты модели предоставляются для облегчения вторичной разработки.
- Опыт работы в Интернете: Предоставляет онлайн-демонстрационную платформу, где пользователи могут непосредственно ознакомиться с функциональностью модели.
- Несколько вариантов развертывания: Поддерживает Huggingface, ModelScope и другие платформы.
Использование помощи
Установка и развертывание
- склад клонов::
git clone https://github.com/THUDM/CogVLM2.git
cd CogVLM2
- Установка зависимостей::
pip install -r requirements.txt
- Скачать модельные веса: Загрузите соответствующие веса моделей и поместите их в указанную директорию.
Пример использования
графическое понимание
- Модели для погрузки::
from cogvlm2 import CogVLM2
model = CogVLM2.load('path_to_model_weights')
- изображение процесса::
image = load_image('path_to_image')
result = model.predict(image)
print(result)
многоуровневый диалог
- Инициализация диалога::
conversation = model.start_conversation()
- вести диалог::
response = conversation.ask('你的问题')
print(response)
Видеопонимание
- Загрузить видео::
video = load_video('path_to_video')
result = model.predict(video)
print(result)
Опыт работы в Интернете
Пользователи могут получить доступ к онлайн-демонстрационной платформе CogVLM2, чтобы ознакомиться с функциональностью модели в режиме онлайн без локального развертывания.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

Нет комментариев...