
CogView3: модель изображения с открытым исходным кодом Wisdom Spectrum с каскадной диффузией для генерации текста

Общее введение
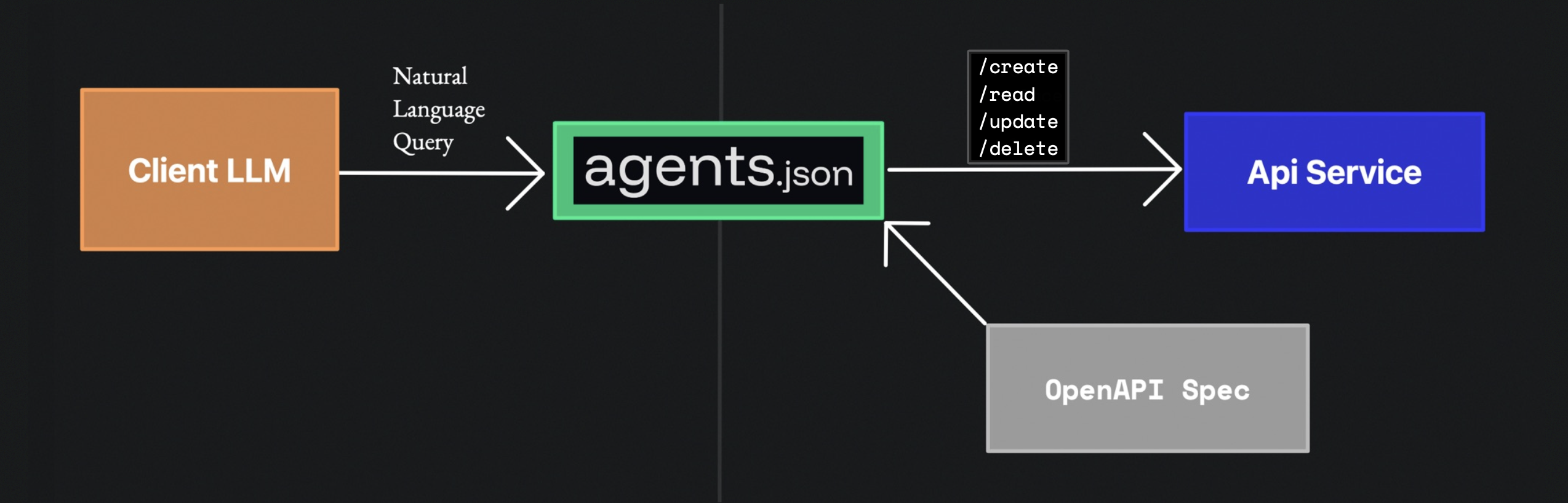
CogView3 - это передовая система создания изображений с текстом, разработанная Университетом Цинхуа и командой Think Tank Team (Chi Spectrum Qingyan). Она основана на модели каскадной диффузии и генерирует изображения высокого разрешения в несколько этапов. Ключевые особенности CogView3 включают многоступенчатую генерацию, инновационную архитектуру и эффективную производительность, которые применимы во многих областях, таких как создание искусства, дизайн рекламы, разработка игр и так далее.
Возможности моделей этой серии теперь доступны онлайн на сайте "Chi Spectrum Clear Words" (chatglm.cn) и могут быть испытаны на Clear Words.


Вверху: автомобиль розового цвета. Внизу: стопка из 3 кубиков. Красный кубик находится вверху и сидит на красном кубике. Красный кубик находится в середине и сидит на зеленом кубике. Зеленый кубик находится внизу.
Список функций
- Многоступенчатая генерация: сначала создаются изображения низкого разрешения, а затем разрешение изображения постепенно увеличивается с помощью процесса релейной диффузии, в результате чего получаются изображения высокого разрешения до 2048x2048.
- Эффективная производительность: CogView3 значительно снижает затраты на обучение и вывод, генерируя при этом высококачественные изображения. По сравнению с SDXL, текущей современной моделью с открытым исходным кодом, время вычисления у CogView3 составляет всего 1/10 часть.
- Инновационная архитектура: CogView3 представляет новейшую архитектуру DiT (Diffusion Transformer), которая использует планирование диффузионного шума Zero-SNR и сочетает механизмы совместного внимания текста и изображения для дальнейшего повышения общей производительности.
- Открытый исходный код: код и модель CogView3 были открыты на GitHub и могут свободно загружаться и использоваться пользователями.
Использование помощи
Установка и регистрация
- Посетите веб-сайт: откройте официальный веб-сайт CogView3. GitHub.
- Загрузите код: нажмите кнопку "Код" на странице и выберите "Загрузить ZIP", чтобы загрузить файл проекта, или воспользуйтесь командой git для его загрузки:
git<span> </span>clone<span> </span>https://github.com/THUDM/CogView3.git. - Установите зависимости: убедитесь, что библиотека diffusers установлена из исходного кода:
pip install git+https://github.com/huggingface/diffusers.git
Процесс использования
- Оптимизация кия :
- Хотя семейство моделей CogView3 обучено на длинных описаниях изображений, мы настоятельно рекомендуем переписывать подсказки с помощью больших языковых моделей (LLM) перед генерацией текста к изображениям, что значительно улучшит качество генерации.
- Запустите следующий скрипт, чтобы оптимизировать подсказку:
python prompt_optimize.py --api_key "Zhipu AI API Key"--prompt {your prompt} --base_url "https://open.bigmodel.cn/api/paas/v4"--model "glm-4-plus"
- Модели рассуждений (диффузоры) :
- Во-первых, убедитесь, что вы установили библиотеку diffusers из исходного кода:
pip install git+https://github.com/huggingface/diffusers.git - Затем выполните следующий код:
fromdiffusers importCogView3PlusPipeline importtorch pipe = CogView3PlusPipeline.from_pretrained("THUDM/CogView3-Plus-3B", torch_dtype=torch.float16).to("cuda") pipe.enable_model_cpu_offload() pipe.vae.enable_slicing() pipe.vae.enable_tiling() prompt = "A vibrant cherry red sports car sits proudly under the gleaming sun, its polished exterior smooth and flawless, casting a mirror-like reflection. The car features a low, aerodynamic body, angular headlights that gaze forward like predatory eyes, and a set of black, high-gloss racing rims that contrast starkly with the red. A subtle hint of chrome embellishes the grille and exhaust, while the tinted windows suggest a luxurious and private interior. The scene conveys a sense of speed and elegance, the car appearing as if it's about to burst into a sprint along a coastal road, with the ocean's azure waves crashing in the background." image = pipe( prompt=prompt, guidance_scale=7.0, num_images_per_prompt=1, num_inference_steps=50, width=1024, height=1024, ).images[0] image.save("cogview3.png")
- Во-первых, убедитесь, что вы установили библиотеку diffusers из исходного кода:
- Модели рассуждений (SAT) :
- Пошаговые инструкции по выводу модели см. в учебнике SAT.
общие проблемы
- Неудачная установка: Убедитесь, что версия Python соответствует требованиям, и обратите внимание на совместимость версий при установке PyTorch.
- Качество изображения: Специфика текстового описания и богатство обучающего набора данных влияют на результаты генерируемых изображений, поэтому рекомендуется использовать подробное текстовое описание и разнообразные наборы данных для обучения.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...