Заметки ChatOllama | Реализация расширенного RAG для продуктивности и баз данных документов на основе Redis

ЧатОллама Это чатбот с открытым исходным кодом, основанный на LLM. Для получения подробного описания ChatOllama перейдите по ссылке ниже.
ChatOllama | Локальное приложение RAG на базе Ollama 100%
ЧатОллама Первоначальная цель заключалась в том, чтобы предоставить пользователям 100% родное приложение RAG.
По мере его развития все больше и больше пользователей выдвигают ценные требования. Теперь `ChatOllama` поддерживает множество языковых моделей, включая:
- Оллама Поддерживаемые модели
- OpenAI
- Azure OpenAI
- Антропология
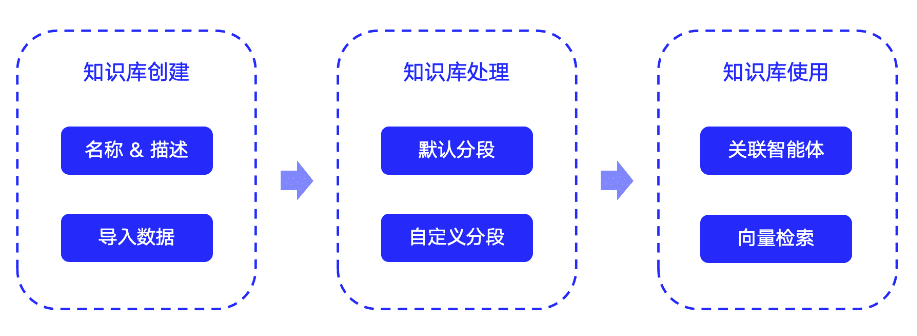
С ChatOllama пользователи могут:
- Управление моделями Ollama (извлечение/удаление).
- Управление базой знаний (создание/удаление)
- Свободный диалог с магистрантами
- Управление базой персональных знаний
- Общение с магистрантами с помощью персональной базы знаний
В этой статье я расскажу о том, как получить продвинутый RAG для производства. Я изучил базовые и продвинутые техники RAG, но для запуска RAG в производство необходимо сделать еще много вещей. Я расскажу о работе, которая была проделана в ChatOllama, и о подготовке, которая была сделана для запуска RAG в производство.

ChatOllama | RAG Constructed Runs
В платформе ChatOllama мы используемLangChain.jsдля управления процессом RAG. В базе знаний ChatOllama используются родительские ретриверы документов, выходящие за рамки оригинального RAG. Давайте подробно рассмотрим его архитектуру и детали реализации. Надеемся, вы найдете это полезным.
Утилита для поиска родительских документов
Чтобы заставить родительский ретривер документов работать в реальном продукте, необходимо понять его основные принципы и выбрать подходящие элементы хранения для производственных целей.
Основные принципы работы с родительскими документами
При разделении документов для поиска часто возникают противоречивые требования:
- Вы можете захотеть, чтобы документы были как можно меньше, чтобы их встроенное содержимое наиболее точно отражало их смысл. Если содержимое слишком длинное, встроенная информация может потерять смысл.
- Кроме того, вам нужны достаточно длинные документы, чтобы каждый абзац имел полное полнотекстовое окружение.
Работает на LangChain.jsParentDocumentRetrieverЭтот баланс достигается путем разбиения документа на фрагменты. При каждом поиске он извлекает фрагменты, а затем ищет родительский документ, соответствующий каждому фрагменту, возвращая больший диапазон документов. Как правило, родительский документ связан с фрагментами по идентификатору doc. Подробнее о том, как это работает, мы расскажем позже.
Обратите внимание, что здесьparent documentОтносится к небольшим фрагментам исходных документов.
построить
Давайте посмотрим на общую схему архитектуры ретривера родительских документов.
Каждый фрагмент будет обработан и преобразован в векторные данные, которые затем будут сохранены в базе данных векторов. Процесс извлечения этих фрагментов будет таким же, как и в оригинальной системе RAG.
Родительский документ (блок-1, блок-2, ...... block-m) разбивается на более мелкие части. Стоит отметить, что здесь используются два разных метода сегментации текста: более крупный - для родительских документов и более мелкий - для небольших блоков. Каждому родительскому документу присваивается идентификатор документа, который затем записывается в качестве метаданных в соответствующий чанк. Это гарантирует, что каждый чанк сможет найти соответствующий родительский документ по идентификатору документа, хранящемуся в метаданных.
Процесс поиска родительских документов отличается от этого. Вместо поиска по сходству указывается идентификатор документа, по которому можно найти соответствующий родительский документ. В этом случае для работы достаточно системы хранения ключевых значений.

Ретривер родительских документов
Секция хранения
Существует два типа данных, которые необходимо хранить:
- Мелкомасштабные векторные данные
- Строковые данные родительского документа, содержащие его ID
Доступны все основные векторные базы данных. Из `ChatOllama` я выбрал Chroma.
Для данных родительских документов я выбрал Redis, самую популярную и масштабируемую систему хранения ключевых значений.
Чего не хватает в LangChain.js
LangChain.js предоставляет несколько способов интеграции хранения байтов и документов:
Поддержка `IORedis`:
Недостающей частью RedisByteStore являетсяcollectionМеханизмы.
При обработке документов из разных баз знаний каждая база знаний будет обрабатываться по отдельности.collectionКоллекции организованы в виде собраний, а документы в одной библиотеке будут преобразованы в векторные данные и сохранены в векторной базе данных, такой как Chroma, в одном изcollectionВ сборе.
Предположим, мы хотим удалить базу знаний? Мы, конечно, можем удалить коллекцию `collection` в базе данных Chroma. Но как нам очистить хранилище документов в соответствии с размерами базы знаний? Поскольку такие компоненты, как RedisByteStore, не поддерживают функциональность `коллекции`, мне пришлось реализовать ее самостоятельно.
ChatOllama RedisDocStore
В Redis нет встроенной функции под названием `коллекция`. Разработчики обычно реализуют функциональность `коллекции` с помощью префиксных ключей. На следующем рисунке показано, как префиксы могут использоваться для идентификации различных коллекций:

Представления ключей Redis с префиксами
Теперь давайте посмотрим, как это было реализовано.Redisфункция хранения документов для фона.
Ключевое сообщение:
- Каждое `RedisDocstore` инициализируется параметром `namespace`. (В настоящее время именование пространств имен и коллекций может быть не стандартизировано).
- Ключи сначала обрабатываются в `пространстве имен` для операций get и set.
import { Document } из "@langchain/core/documents".
import { BaseStoreInterface } из "@langchain/core/stores" ;
Импортируйте { Redis } из "ioredis".
import { createRedisClient } из "@/server/store/redis" ;export class RedisDocstore implements BaseStoreInterface
{
_namespace: string;
_клиент: Redis.constructor(namespace: string) {
this._namespace = namespace;
this._client = createRedisClient();
}serializeDocument(doc: Document): string {
return JSON.stringify(doc);
}deserializeDocument(jsonString: string): Document {
const obj = JSON.parse(jsonString);
return new Document(obj);
}getNamespacedKey(key: string): string {
return `${this._namespace}:${key}`;
}getKeys(): Promise {
return new Promise((resolve, reject) => {
const stream = this._client.scanStream({ match: this._namespace + '*' });const keys: string[] = [];
stream.on('data', (resultKeys) => {
keys.push(... .resultKeys);
});stream.on('end', () => {
resolve(keys).
});stream.on('error', (err) => {
reject(err);
});
});
}addText(key: string, value: string) {
this._client.set(this.getNamespacedKey(key), value);
}async search(search: string): Promise {
const result = await this._client.get(this.getNamespacedKey(search));
if (!result) {
throw new Error(`ID ${search} not found.`);
} else {
const document = this.deserializeDocument(result);
вернуть документ;
}
}/**
* :: Добавляет новые документы в хранилище.
* @param texts Объект, в котором ключами являются идентификаторы документов, а значениями - сами документы.
* @returns Void
*/
async add(texts: Record): Promise {
for (const [key, value] of Object.entries(texts)) {
console.log(`Добавление ${key} в хранилище: ${this.serializeDocument(value)}`);
}const keys = [... .await this.getKeys()];
const Перекрытие = Object.keys(texts).filter((x) => keys.includes(x));если (overlapping.length > 0) {
throw new Error(`Попытка добавить идентификаторы, которые уже существуют: ${перекрытие}`);
}for (const [key, value] of Object.entries(texts)) {
this.addText(key, this.serialiseDocument(value)); this.
}
}async mget(keys: string[]): Promise {
return Promise.all(keys.map((key) => {
const document = this.search(key);
вернуть документ;
}));
}async mset(keyValuePairs: [string, Document][]): Promise {
await Promise.all(
keyValuePairs.map(([key, value]) => this.add({ [key]: value }))
);
}async mdelete(_keys: string[]): Promise {
throw new Error("Не реализовано.");
}// eslint-disable-next-line require-yield
async *yieldKeys(_prefix?: string): AsyncGenerator {
throw new Error("Не реализовано");
}async deleteAll(): Promise {
return new Promise((resolve, reject) => {
пусть курсор = '0';const scanCallback = (err, result) => {
if (err) {
reject(err);
возвращение;
}const [nextCursor, keys] = result;
// Удаление ключей, соответствующих префиксу
keys.forEach((key) => {
this._client.del(key);
});// Если курсор равен '0', мы перебрали все клавиши.
if (nextCursor === '0') {
resolve().
} else {
// Продолжить сканирование со следующим курсором
this._client.scan(nextCursor, 'MATCH', `${this._namespace}:*`, scanCallback);
}
};// Запуск начальной операции SCAN
this._client.scan(cursor, 'MATCH', `${this._namespace}:*`, scanCallback);
});
}
}
Вы можете использовать этот компонент вместе с ParentDocumentRetriever:
retriever = new ParentDocumentRetriever({
vectorstore: chromaClient.
docstore: новый RedisDocstore(collectionName),
parentSplitter: new RecursiveCharacterTextSplitter({
chunkOverlap: 200,
chunkSize: 1000,
}),
childSplitter: new RecursiveCharacterTextSplitter({
chunkOverlap: 50,
chunkSize: 200,
}),
childK: 20.
parentK: 5.
});
Теперь у нас есть масштабируемое решение для хранения расширенного RAG, Parent Document Retriever, а также `Chroma` и `Redis`.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...