Локальное развертывание больших моделей QwQ-32B: простое руководство для ПК

Сфера моделирования искусственного интеллекта (ИИ) всегда полна сюрпризов, и каждый технологический прорыв может потрепать нервы всей индустрии. Недавно команда Alibaba QwQ выпустила свою последнюю модель выводов, QwQ-32B, в ранние утренние часы, что вновь привлекло большое внимание.

Согласно официальному релизуQwQ-32B - это модель вывода с масштабом параметров всего 32 миллиарда.И все же они утверждают, что могут соперничать с DeepSeek-R1 и другие передовые модели. Объявление стало сенсацией, мгновенно всколыхнувшей технологическое сообщество: ссылки на официальный блог, библиотеку моделей Hugging Face, скачивание моделей, онлайн-демонстрации и сайт для пользователей, где они могут узнать больше о продукте и испытать его.
Хотя информация о релизе краткая и лаконичная, техническая мощь, стоящая за ней, далеко не проста. Фраза "32 миллиарда параметров, сравнимых с DeepSeek-R1" впечатляет, если знать, что в общем случае чем больше параметров в модели, тем выше производительность, но это также означает более высокую потребность в вычислительных ресурсах. QwQ-32B Достижение производительности, аналогичной мегамодели, при небольшом количестве параметров, несомненно, является большим прорывом, который, естественно, вызвал большой интерес среди энтузиастов и профессионалов в области технологий.
Чтобы продемонстрировать производительность QwQ-32B более наглядно, одновременно была опубликована официальная таблица эталонных тестов. Бенчмаркинг - это важный способ оценки возможностей модели ИИ, который измеряет производительность модели в различных задачах, тестируя ее на серии заданных, стандартизированных наборов данных, тем самым предоставляя пользователям объективный эталон производительности.

На основе этой контрольной диаграммы мы можем быстро получить следующую ключевую информацию:
- Феноменальная скорость распространения: Информацию о достига́ть релиза модели прочитали более 1,69 миллиона человек всего за 12 часов, что полностью отражает острую потребность рынка в высокопроизводительных моделях ИИ и большие ожидания от QwQ-32B.
- Отличная производительность: Имея всего 32 миллиарда параметров, QwQ-32B может конкурировать с полнопараметрической версией DeepSeek-R1, имеющей 671 миллиард параметров, в эталонном тесте, демонстрируя удивительное соотношение энергоэффективности. Этот феномен, когда маленькая модель превосходит большую, определенно ломает традиционное представление о связи между производительностью модели и размером параметров.
- Превосходит дистилляционные модели в своем классе: QwQ-32B значительно превосходит версию DeepSeek-R1 с дистилляцией 32B. Дистилляция - это техника сжатия модели, которая направлена на имитацию поведения более крупной модели путем обучения более мелкой модели, что позволяет снизить вычислительные затраты при сохранении производительности. Тот факт, что QwQ-32B превосходит 32-битную дистилляционную модель, еще раз демонстрирует сложность ее архитектуры и методики обучения.
- Многомерное лидерство по производительности: QwQ-32B превосходит закрытую модель OpenAI, o1-mini, по нескольким параметрам бенчмарка, что говорит о том, что QwQ-32B способен конкурировать с лучшими закрытыми моделями по возможностям общего назначения.
Особый интерес представляет тот факт, что QwQ-32B, имеющая всего 32 миллиарда параметров, способна превзойти гигантские модели с более чем в 20 раз большим количеством параметров, что является еще одним скачком вперед в технологии ИИ. Что еще более интересно, теперь пользователи могут легко запустить квантованную версию QwQ-32B локально с помощью потребительской видеокарты класса RTX3090 или RTX4090. Локальное развертывание не только снижает барьер для использования, но и открывает больше возможностей для безопасности данных и персонализированных приложений. Пользователи с более низкой производительностью видеокарты могут попробовать начать работу с рекомендованного облачного развертывания:Развертывание модели DeepSeek-R1 с открытым исходным кодом в режиме онлайн с использованием бесплатных мощностей GPUили подайте заявку напрямую, чтобы воспользоваться бесплатным API.Alibaba (вулкан) предоставляет 1 миллион токенов в день (в течение 180 дней), а Акаш API можно использовать бесплатно и без регистрации.
DeepSeek больше не является пони с одним фокусом, как же OpenAI удержаться на вершине?
С учетом того, что QwQ-32B демонстрирует столь высокую конкурентоспособность, существующие продукты OpenAI, как версия Pro за 200 долларов, так и версия Plus за 20 долларов, сталкиваются с серьезным вызовом в соотношении цена/производительность. QwQ-32B дал рынку повод задуматься, особенно в свете тех колебаний производительности, которые иногда демонстрируют модели OpenAI и которые критикуются пользователями как "отупление". Тем не менее, OpenAI по-прежнему имеет глубокую историю и обширную экосистему в области ИИ, и у него все еще может быть преимущество в тонкой настройке моделей и оптимизации приложений в конкретных областях. Однако выпуск QwQ-32B, несомненно, нарушит первоначальный уклад рынка, заставив всех игроков пересмотреть свои технические преимущества и рыночные стратегии.
Для того чтобы более полно оценить реальные возможности QwQ-32B, необходимо установить его на месте и детально протестировать, особенно для того, чтобы изучить его рассуждения и уровень "IQ" в локальной операционной среде.
К счастью, благодаря Оллама С появлением таких инструментов, как Ollama, развертывание и запуск больших языковых моделей локально на персональных компьютерах стало очень простым. Ollama, фреймворк с открытым исходным кодом для запуска облегченных моделей, значительно упрощает процесс развертывания и управления большими локальными моделями.
Компания Ollama славится своей эффективностью и простотой использования. Вскоре после выпуска QwQ-32B компания Ollama быстро объявила о поддержке этой модели, что еще больше снижает барьер для пользователей при знакомстве с новейшими технологиями искусственного интеллекта и упрощает для всех возможность начать работу с возможностями QwQ-32B.
1. Установка и эксплуатация Ollama
Сначала посетите официальный сайт Ollama по адресу ollama.com и нажмите кнопку Download, чтобы загрузить подходящий установочный пакет для вашей операционной системы.
Ollama обеспечивает полную поддержку всех основных операционных систем, включая macOS (Intel и Apple Silicon), Windows и Linux, гарантируя, что модель QwQ-32B может быть легко использована на всех платформах.
После завершения загрузки дважды щелкните на программе установки и следуйте указаниям мастера, чтобы завершить процесс установки. После успешной установки вы увидите симпатичный значок альпаки в области панели задач в Windows или в строке меню в macOS, что означает, что Ollama была успешно запущена и работает в фоновом режиме, готовая служить вам.
2. Загрузка модели QwQ-32B
Обязательно к прочтению:Unsloth решает проблему дублирующего вывода в квантифицированной версии QwQ-32B
После успешной установки и запуска Ollama вы можете приступить к загрузке модели QwQ-32B.

Откройте клиент Ollama в Модели На странице "Модели" вы увидите, что модель QwQ-32B быстро поднялась в верхнюю часть списка "Горячие модели", что свидетельствует о ее популярности. Найдите запись модели "qwq" и нажмите на нее, чтобы перейти на страницу подробностей модели. На странице подробностей скопируйте команды, выделенные красной рамкой.
Откройте локальный терминал (macOS/Linux) или командную строку (Windows).
В терминале или командной строке вставьте и выполните следующую команду:ollama run qwq
ollama run qwq
Ollama автоматически начнет загрузку файлов модели QwQ-32B из облака и автоматически запустит среду выполнения модели по завершении загрузки.
Стоит отметить, чтоПроцесс загрузки модели не требует от пользователя дополнительной настройки сети. Это, несомненно, очень удобная функция для отечественных пользователей. Ведь файл модели размером почти 20 Гб значительно снизит удобство использования, если скорость загрузки будет слишком низкой или потребуется специальное сетевое окружение.
Однако в связи с тем, что модель QwQ-32B в настоящее время очень популярна и ее скачивают многие пользователи, реальная скорость загрузки может в некоторой степени пострадать, что приведет к увеличению времени загрузки, и пользователям придется терпеливо ждать.
После некоторого ожидания модель наконец загрузилась. Я запустил модель QwQ-32B на компьютере, оснащенном видеокартой RTX3060 настольного класса с 12 Гбайт видеопамяти, чтобы опробовать ее, и был приятно удивлен: модель не только успешно загрузилась, но и смогла плавно выдавать ответы на основе вводимых пользователем данных, и, что самое важное, на протяжении всего процесса не было проблем с переполнением видеопамяти. Что еще более важно, на протяжении всего процесса не возникало проблем с переполнением памяти, а это значит, что даже мейнстримовые видеокарты могут соответствовать требованиям количественной модели QwQ-32B.

С точки зрения реальной производительности умозаключений, способности QwQ-32B уже превзошли некоторые модели OpenAI, которые пользователи в шутку называют "IQ underline". Это также подтверждает превосходство QwQ-32B в плане производительности.
С помощью диспетчера задач Windows мы можем отслеживать использование ресурсов модели в режиме реального времени. Результаты показывают, что процессор, память и графическая память испытывают высокую нагрузку в процессе вывода модели, что также отражает высокие требования к аппаратным ресурсам для локального запуска больших моделей.
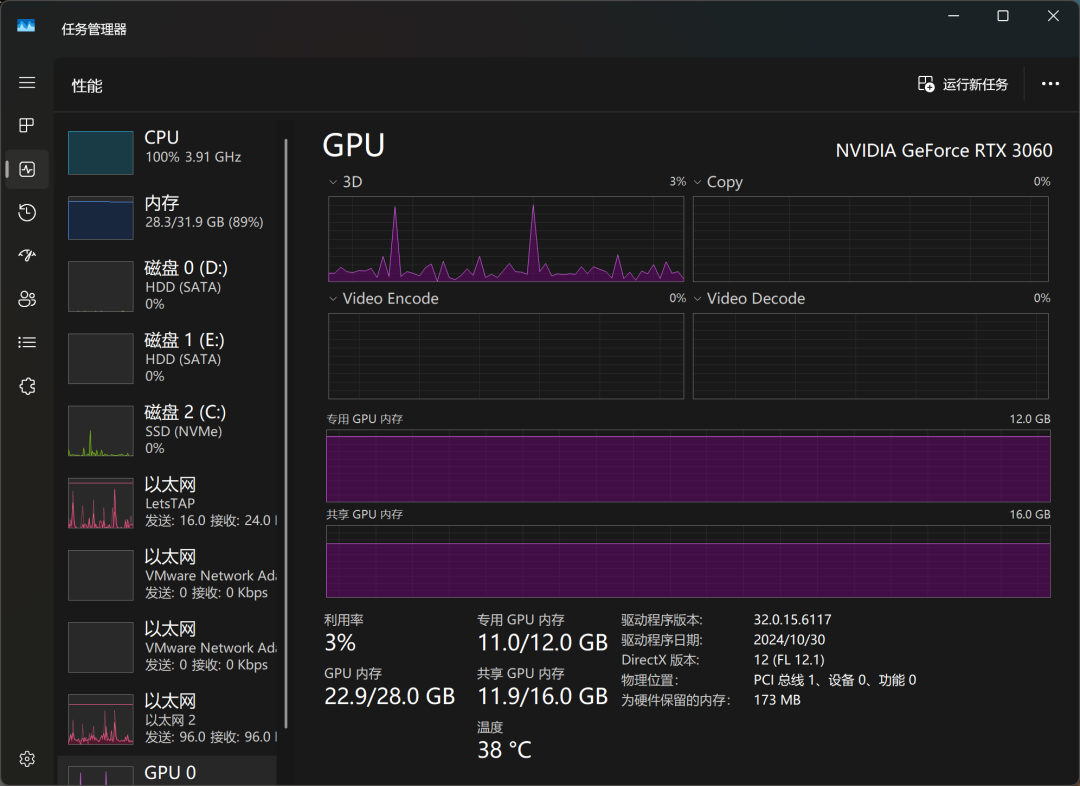
На видеокарте RTX3060 QwQ-32B отвечает примерно в темпе "да, да, да, да, да...", что может удовлетворить основные потребности использования, но в плане отзывчивости и плавности еще есть куда стремиться. Если вы ищете более экстремальные возможности работы с локальными моделями, вам может понадобиться более высокий уровень аппаратной конфигурации.
Чтобы еще больше повысить скорость работы модели, я загрузил и снова запустил модель QwQ-32B на устройстве, оснащенном топовой видеокартой RTX3090. Результаты эксперимента показали, что после замены видеокарты более высокого класса скорость работы модели значительно увеличилась, и ее можно без преувеличения назвать "быстрой, как полет". Это также подтверждает важность аппаратной конфигурации для работы локальной большой модели.
3. Интеграция QwQ-32B в клиентов
Хотя общение с моделью непосредственно из интерфейса командной строки - простой и понятный способ, для тех, кому приходится часто использовать модель или кто ищет более удобного взаимодействия, использование графического клиента, несомненно, является более удобным выбором. На рынке существует множество отличных клиентских программ для моделей искусственного интеллекта, и мы уже представляли многие из них, например ChatWise. Основной причиной выбора ChatWise является простой и интуитивно понятный дизайн интерфейса, четкая и понятная логика работы, а также способность обеспечить пользователям хороший опыт.
Ниже описаны шаги по настройке модели QwQ-32B на клиент ChatWise.
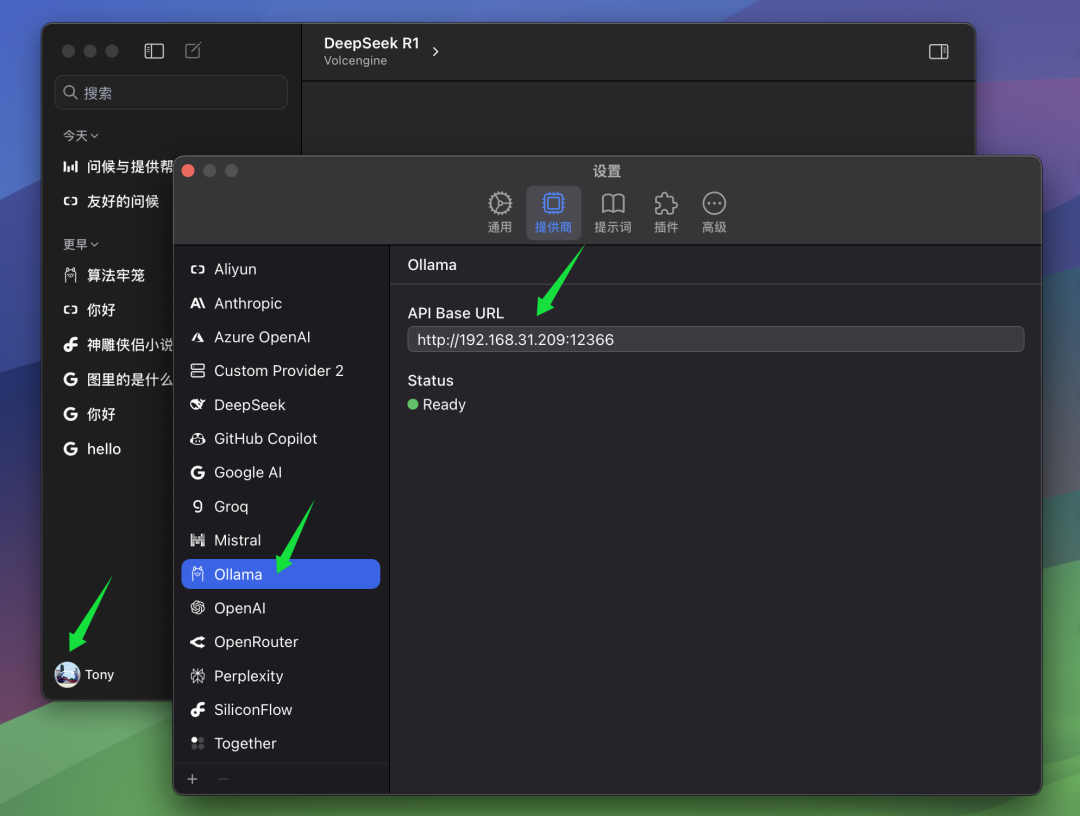
Если клиент ChatWise и служба Ollama запущены на одном компьютере, обычно можно открыть клиент ChatWise и использовать модель QwQ-32B напрямую, без дополнительной настройки. Так поступает большинство пользователей, т.е. и служба Ollama, и клиентское приложение установлены на одном устройстве.
Однако если вы, как и автор, установили службу Ollama на другом компьютере (например, на сервере), а клиент ChatWise запущен на вашем локальном компьютере, вам придется вручную изменить ChatWise BaseURL настройки, чтобы клиенты могли подключаться к удаленной службе Ollama. В BaseURL В настройках необходимо указать IP-адрес компьютера, на котором запущена служба Ollama, и номер порта, который вы настроили на сервере Ollama. Порт по умолчанию для Ollama - 13434, поэтому, если вы не настраивали его специально, можете просто использовать порт по умолчанию.
выполнить BaseURL После настройки вы можете выбрать модель, которую хотите использовать в клиенте ChatWise.
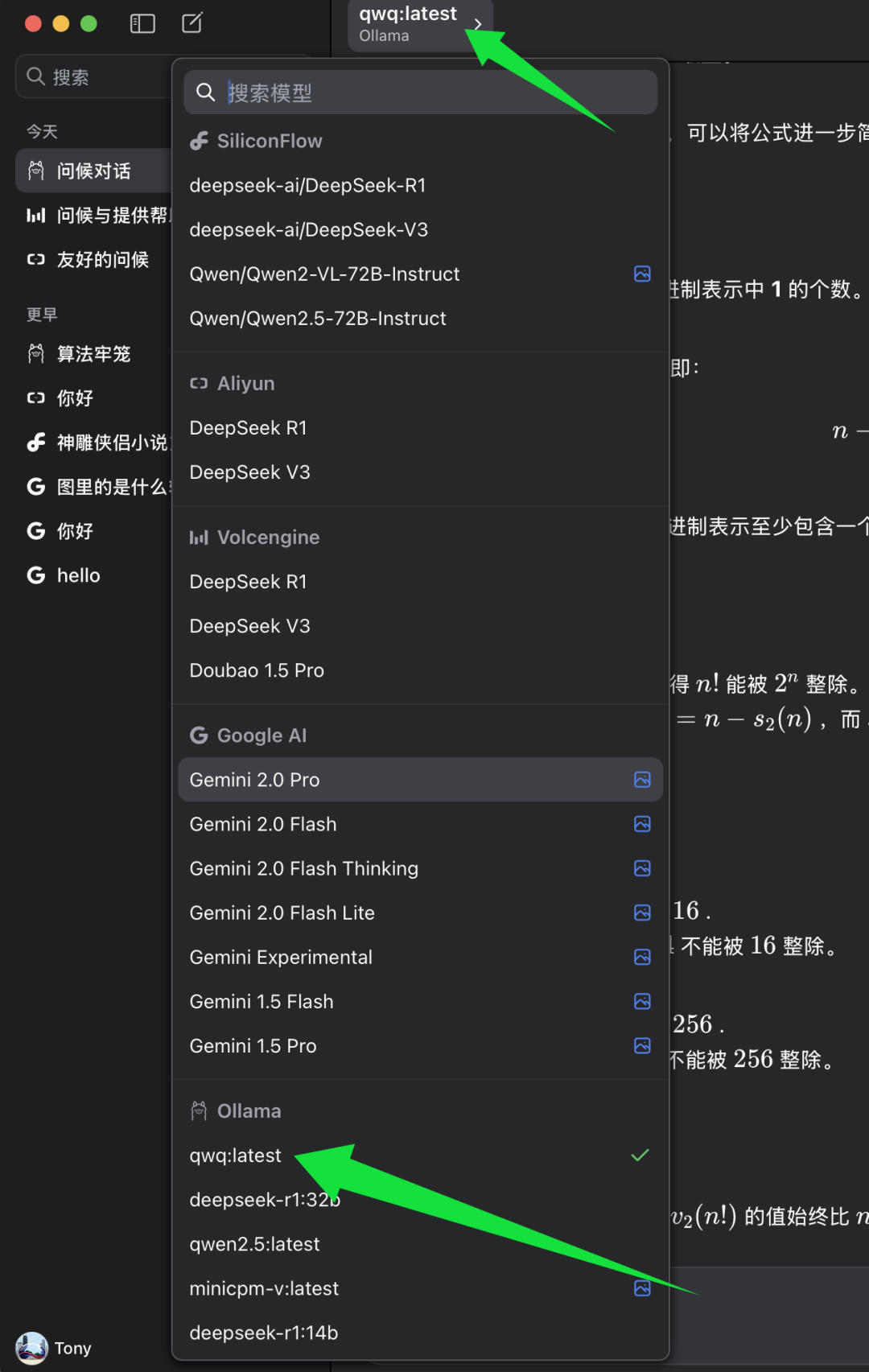
В списке выбора моделей ChatWise найдите категорию моделей Ollama и под ней выберите qwq:latest. qwq:latest Представляет собой последнюю версию модели QwQ-32B, обычно также 4-битную квантованную версию. Выберите qwq:latest После этого вы сможете испытать возможности модели QwQ-32B в клиенте ChatWise.
4. тест уровня интеллекта модели QwQ-32B
Чтобы более объективно оценить уровень интеллекта модели QwQ-32B, мы использовали набор классических вопросов, ранее разработанных для тестирования проблемы "сниженного интеллекта" модели OpenAI. Этот набор состоит из четырех тщательно отобранных вопросов, которые, как было показано эмпирическим путем, могут быть полезны, если ChatGPT (особенно для моделей GPT-3 или GPT-4), часто бывает трудно правильно ответить на эти вопросы, если пользователь отзывается о "пониженном интеллекте". Поэтому этот набор вопросов можно использовать в качестве эталона для проверки уровня интеллекта больших моделей.
Далее мы поочередно протестируем локально запущенную модель QwQ-32B, чтобы проверить, сможет ли она успешно ответить на все вопросы.
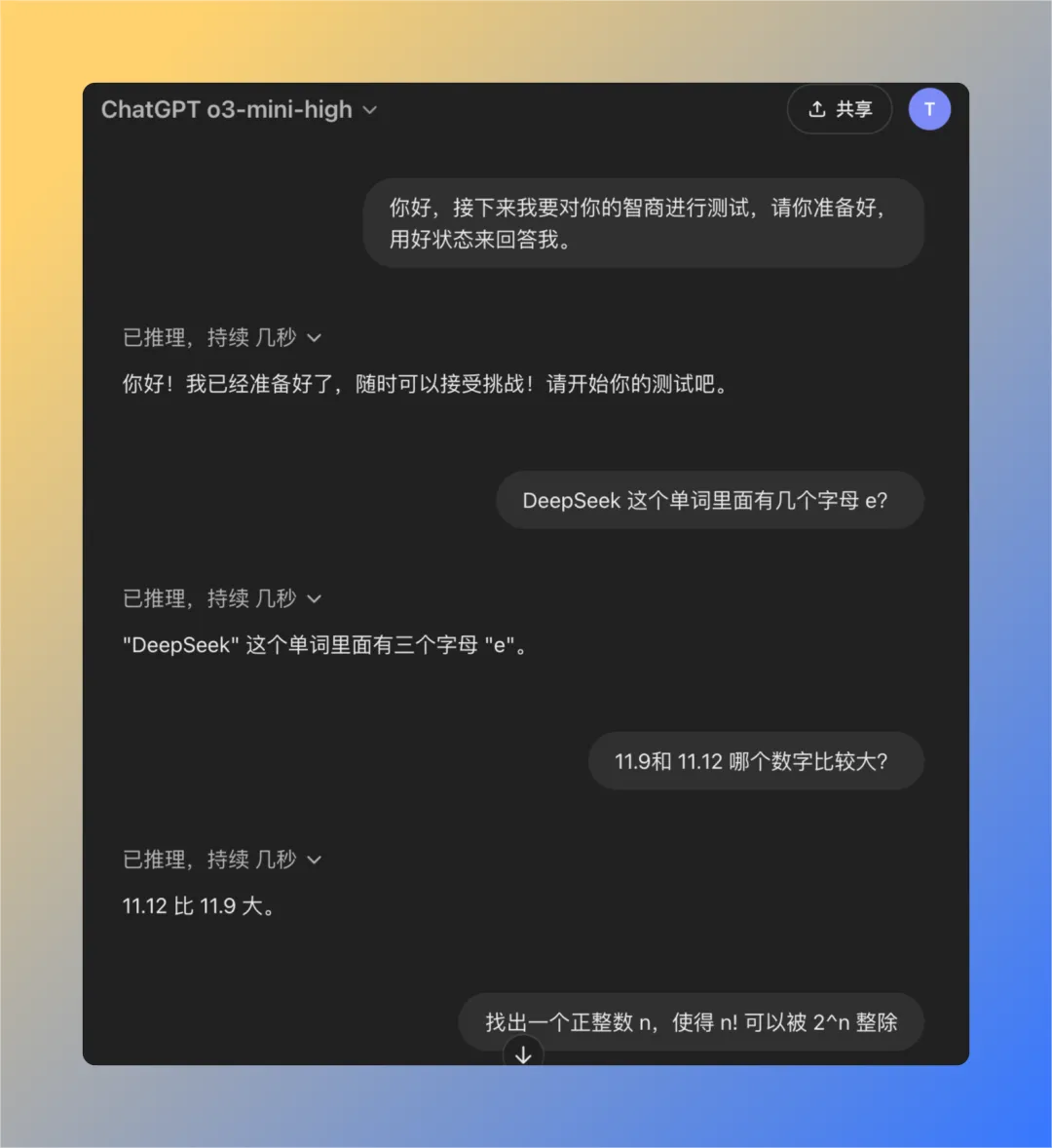
Вопрос 1: Сколько букв е в слове deepseek?
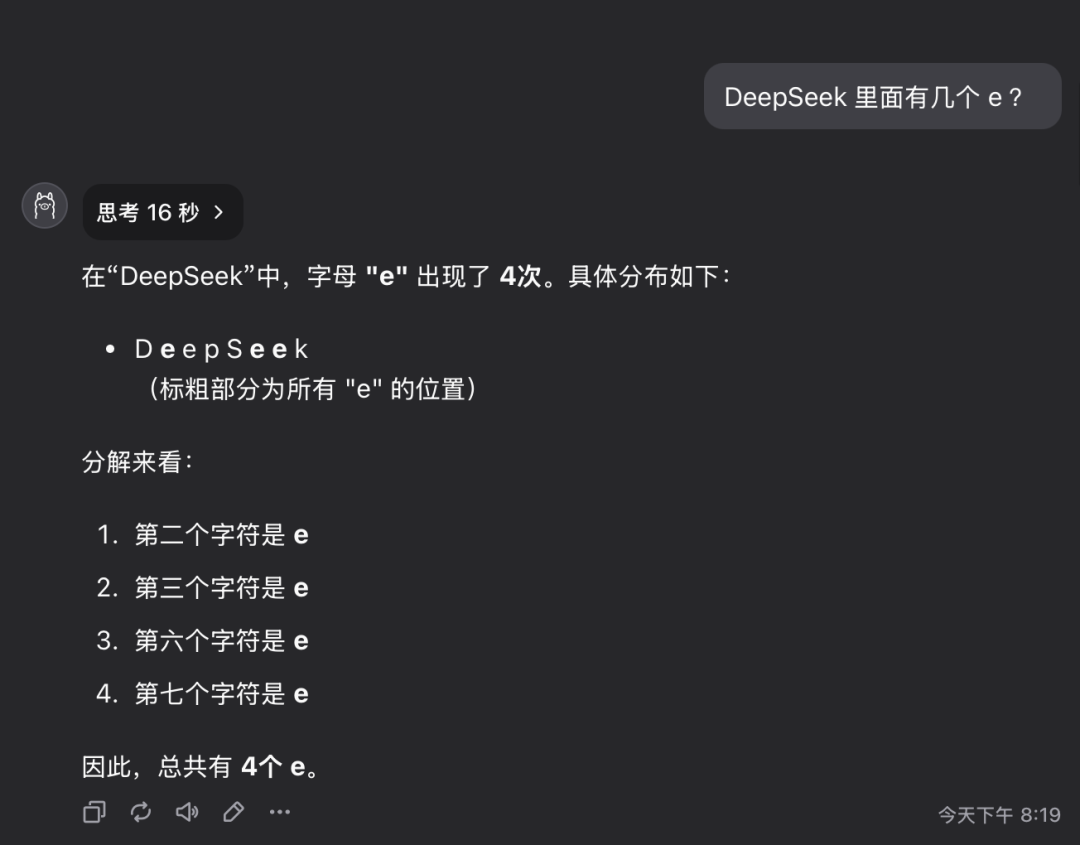
Модель QwQ-32B дала правильный ответ за 16 секунд: 3. Ответ правильный..
Этот вопрос может показаться простым, но на самом деле он проверяет способность модели точно понимать и извлекать детальную информацию. Удивительно, но до сих пор существует значительное количество крупных моделей, которые не могут точно ответить на подобные вопросы.
Вопрос 2: Какое значение больше - 11,9 или 11,12?

Модель QwQ-32B дала правильный ответ за 47 секунд: 11,12 больше. Ответ правильный..
И снова это, казалось бы, элементарная, но классическая проблема. Многие крупные модели путаются или неправильно оценивают простые числовые сравнения, что отражает возможные недостатки в логическом обосновании модели.
Задача 3: Найдите целое положительное число n такое, что факториал n (n!) кратен n-й степени 2 (2^n).

Модель QwQ-32B дает правильный ответ за 121 секунду: такого целого положительного числа n не существует. Ответ правильный..
Смысл этого вопроса не в том, чтобы найти конкретный числовой ответ, а в том, чтобы проверить, обладает ли модель способностью абстрактно и логически мыслить, понимать суть проблемы и в конечном итоге прийти к выводу, что "этого не существует". QwQ-32B смог правильно ответить на этот вопрос, продемонстрировав некоторую способность к логическим рассуждениям.
Вопрос 4: Классическое логическое рассуждение - головоломка цвета шляпы
"В ряд выстроились 5 человек, и у каждого из них на голове надета шляпа, которая может быть красного или синего цвета. Каждый человек может видеть только цвет шляпы того, кто стоит перед ним в ряду, но не цвет шляпы на своей голове". Ведущий заранее говорит группе: "Из этих 5 человек есть хотя бы одна красная шляпа". Теперь, начиная с человека в конце ряда и продвигаясь вперед по очереди, каждого спрашивают: "Знаете ли вы, какого цвета ваша шляпа?" Каждый может ответить только "да" или "нет". Если предположить, что пятый человек отвечает "нет", а четвертый - "да", каково распределение всех возможных цветов шляп?"
По сравнению с первыми тремя вопросами, этот вопрос на логические рассуждения был значительно сложнее и требовал от модели большего логического анализа и умения рассуждать.
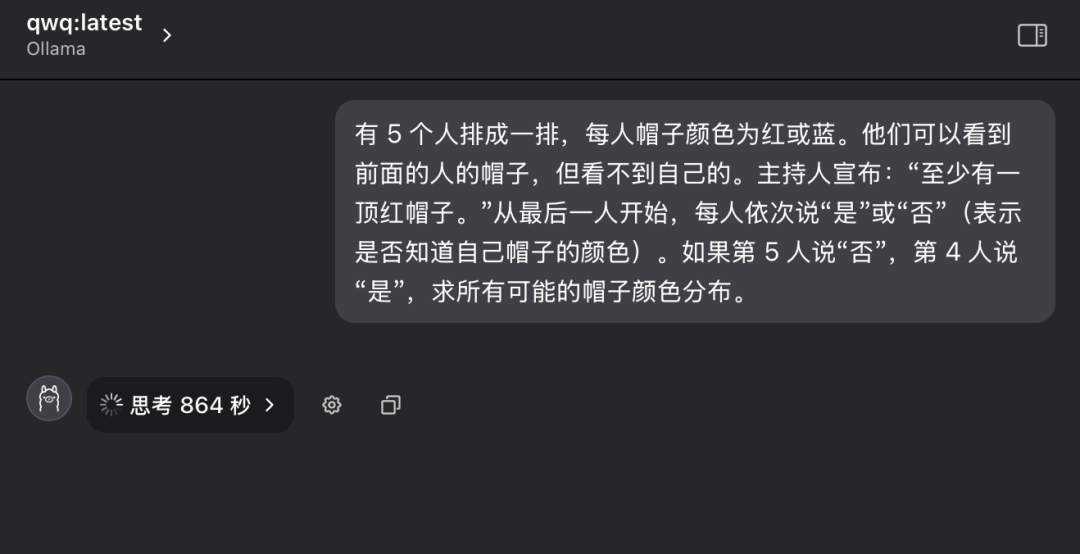
Во время первого допроса модель QwQ-32B вошла в состояние длительного размышления, на экране мигала надпись "Thinking...", как будто "мозг" работал на высокой скорости, что даже заставило людей задуматься о том, выдержит ли аппаратное обеспечение такую интенсивную вычислительную нагрузку. Это даже заставило людей забеспокоиться о том, выдержит ли оборудование такую интенсивную вычислительную нагрузку. Учитывая время и условия работы оборудования, после более чем десяти минут ожидания я вручную прервал процесс обдумывания модели.
Затем автор вновь открыл новую сессию диалога и снова задал те же вопросы модели QwQ-32B.

На этот раз модель QwQ-32B дала полностью правильный ответ через 196 секунд и подробно объяснила свои рассуждения. Ответ правильный..
Посмотрев на запись процесса рассуждений модели, мы можем почувствовать, что, несмотря на относительно небольшой размер параметра QwQ-32B, она все же демонстрирует очень "тяжелый" процесс мышления и анализа, когда сталкивается со сложной логической задачей. Модель выполняет множество логических вычислений и вычислений вероятности в фоновом режиме, прежде чем прийти к правильному выводу.
После вышеприведенной серии тщательных и подробных IQ-тестов мы можем сделать предварительный вывод, что квантифицированная версия 4-битной модели QwQ-32B продемонстрировала впечатляющую общую производительность, особенно в логических рассуждениях и викторинах, и превзошла другие модели в своем классе. Есть основания полагать, что производительность неквантованной версии QwQ-32B будет еще выше. Отчет об оценке производительности модели 32B Full Blood Edition QwQ-32B предоставляет более полные данные о производительности и анализе. Таким образом, мы можем с уверенностью судить о том, что реклама производительности, сделанная командой Alibaba QwQ при выпуске модели QwQ-32B, не преувеличена, и QwQ-32B действительно является отличной новой моделью вывода, которая достигает силы конкуренции с моделью DeepSeek-R1 с 671 миллиардом параметров и шкалой параметров в 32 миллиарда параметров.
Стремительный рост отечественных больших моделей с открытым исходным кодом в полной мере демонстрирует энергичные инновации и огромный потенциал развития Китая в области технологий ИИ.
Что еще лучше, так это то, что для плавной и впечатляющей работы модели QwQ-32B 32B требуется только видеокарта с 24 ГБ оперативной памяти. Если несколько лет назад для запуска такой высокопроизводительной крупномасштабной модели потребовались бы миллионы долларов на специализированном оборудовании, то теперь, благодаря таким достижениям в технологиях, как QwQ-32B и Ollama, пользователи могут развернуть и испытать ее локально на ПК стоимостью 10 000 долларов. Выпуск модели QwQ-32B свидетельствует о том, что высокопроизводительные модели ИИ становятся все более популярными, а эра "ИИ для всех" ускоряется, и высокопроизводительные технологии ИИ будут иметь более широкие перспективы применения в персональных терминальных устройствах и различных отраслях промышленности.
Сейчас самое время действовать, изучить все подробности и максимально использовать мощные возможности QwQ-32B! Давайте вместе встретим светлое будущее технологии искусственного интеллекта!
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...