
Mureka V7.5 - усовершенствованные модели создания музыки с искусственным интеллектом от Quintessence
Mureka V7.5 - это современная модель генерации музыки с помощью искусственного интеллекта от Kunlun World Wide, ориентированная на создание китайских песен. Модель точно воспроизводит тембр и технику игры для создания естественного, плавного и эмоционального вокала. Основанная на оптимизированной технологии автоматического распознавания речи (ASR), Mureka V...

Skywork Deep Research Agent v2 - обновленная версия разведчика глубоких исследований от Kunlun
Skywork Deep Research Agent v2 - это интеллектуальный орган для глубоких исследований, созданный компанией Kunlun Wave и ориентированный на интеграцию и анализ мультимодальной информации. Skywork Deep Research Agent v2 может обрабатывать текст, граф...

Hunyuan-GameCraft - фреймворк с открытым исходным кодом от Tencent Hunyuan для создания интерактивного видео для игр нового поколения.
Hunyuan-GameCraft является открытым исходным кодом Tencent Hunyuan команды интерактивных игр видео генерации рамки. Фреймворк из одной картинки и подсказок генерирует высокодинамичное игровое видео, поддерживая пользователя с помощью клавиатуры и мыши для управления видеоконтентом в реальном времени.

Skywork UniPic 2.0 - эффективное мультимодальное моделирование с открытым исходным кодом от KunlunWanwei
Skywork UniPic 2.0 - это эффективная мультимодальная модель с открытым исходным кодом от Quintessence, ориентированная на создание, редактирование и понимание изображений. Модель основана на 2B-параметрической архитектуре SD3.5-Medium и реализуется с помощью предварительного обучения, прогрессивной стратегии двухзадачного усиления и совместного обучения...

RynnRCP - первый контекстный протокол для робототехники с открытым исходным кодом от Института Али Дхарма
RynnRCP - это протокол контекста робота (RCP) с открытым исходным кодом от Ali Dharma Institute, который снижает порог для разработки встроенного интеллекта и открывает весь процесс разработки.RynnRCP состоит из фреймворка RCP и модуля RobotMotion.Фреймворк RCP, благодаря абстрагированию возможностей и поддержке нескольких протоколов,...

RynnEC - модель понимания мира с открытым исходным кодом Института Али Дхармы
RynnEC - это модель понимания мира, представленная Alibaba Dharma Institute и ориентированная на задачи воплощенного интеллекта. Модель основана на технологии мультимодального слияния, объединяющей видеоданные и естественный язык, и может анализировать объекты в сцене по нескольким измерениям, поддерживая такие функции, как понимание объектов, пространственное восприятие и сегментация видеоцелей.

Matrix-3D - фреймворк с открытым исходным кодом для генерации 3D-миров в Kunlun World Wide Web
Matrix-3D - это фреймворк с открытым исходным кодом от команды Skywork AI, ориентированный на создание панорамных 3D-миров. Фреймворк сочетает в себе технологии генерации панорамного видео и 3D-реконструкции для создания высококачественных, всенаправленных изучаемых 3D-миров из одного изображения или текстовой подсказки...
GLM-4.5V - мультимодальная модель визуального мышления с открытым исходным кодом от Smart Spectrum
GLM-4.5V - ведущая в мире модель визуального вывода с открытым исходным кодом, представленная компанией Smart Spectrum, с 106 миллиардами общих параметров и 12 миллиардами активированных параметров. Модель обучена на основе текстовой базовой модели нового поколения GLM-4.5-Air, обладает мощными возможностями визуального понимания и рассуждения, способна работать с изображениями, видео...
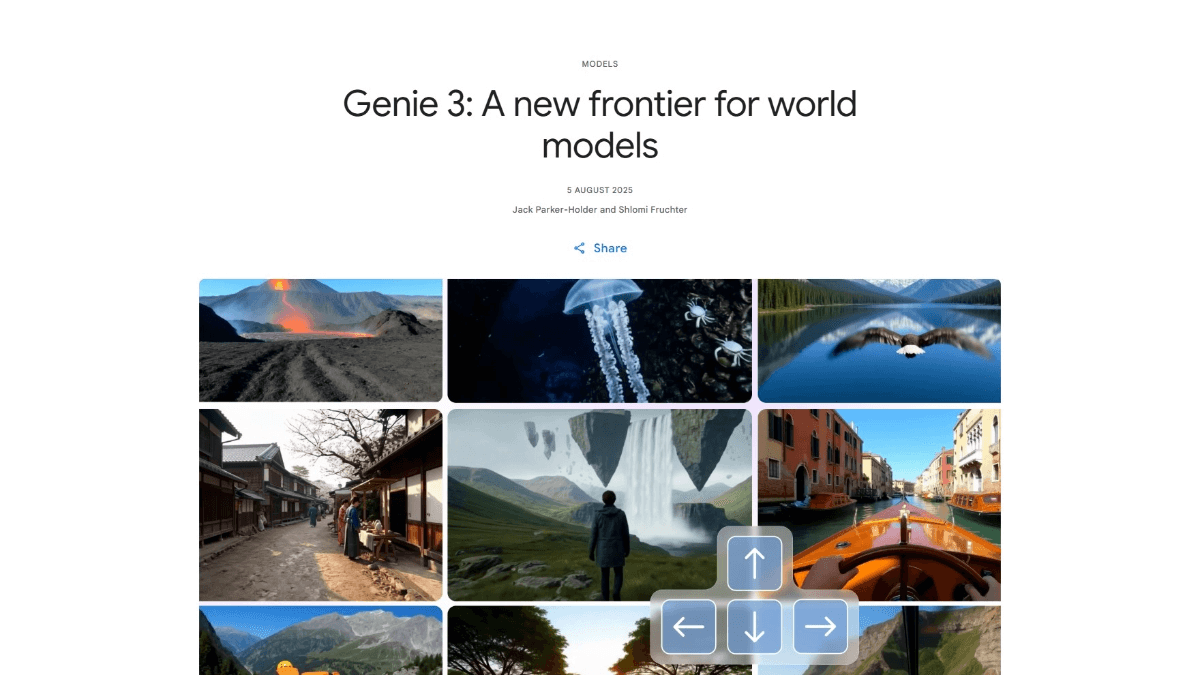
Genie 3 - общая модель мира от Google
Genie 3 - это новое поколение универсальных моделей мира от Google DeepMind, позволяющих создавать высокодинамичные и целостные виртуальные миры в режиме реального времени. Genie 3 моделирует физические явления, природные экосистемы и поддерживает создание фантастических и исторических сценариев. С помощью текстовых подсказок пользователи могут...
Claude Opus 4.1 - самая мощная модель программирования от Anthropic
Claude Opus 4.1 - это современная крупномасштабная языковая модель от компании Anthropic, предназначенная для эффективной обработки сложных задач. Модель отлично зарекомендовала себя в области программирования, генерируя высококачественный код, поддерживая до 32k единичного вывода и адаптируясь к широкому спектру стилей программирования...