
Open-o3 Video - модель рассуждений о видео с открытым исходным кодом Пекинского университета Объединенные байты
Open-o3 Video - это модель вывода видео с открытым исходным кодом, разработанная совместно Пекинским университетом и ByteDance и направленная на улучшение вывода видео с помощью временных и пространственных данных. Явное обозначение ключевых свидетельств временными метками и ограничительными рамками помогает модели лучше понимать и интерпретировать видеоконтент.
Handy - бесплатный инструмент для преобразования речи в текст с открытым исходным кодом на основе искусственного интеллекта
Handy - это бесплатный локальный инструмент преобразования речи в текст с открытым исходным кодом, поддерживающий системы Windows, MacOS и Linux, разработанный на Rust и React. Обрабатывая голосовые данные локально, без загрузки в облако, он гарантирует конфиденциальность и безопасность, а также подходит для быстрой транскрипции и ввода текста.
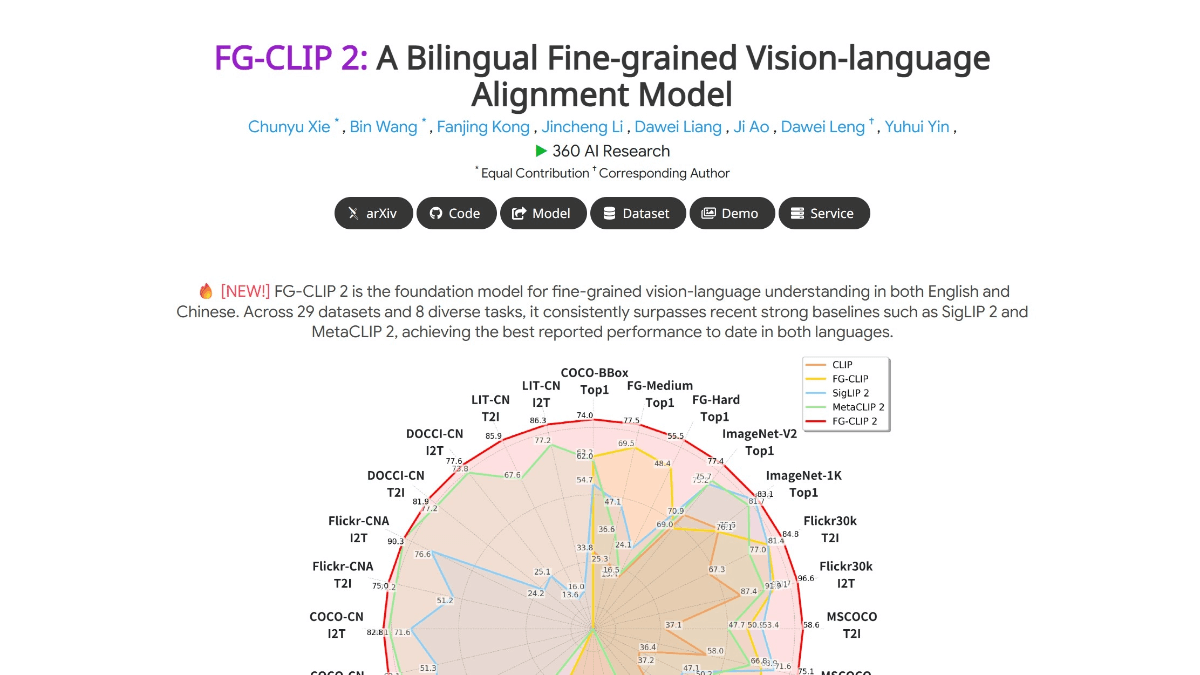
FG-CLIP 2 - 360 Open Source Cross-Modal Visual Language Model for Graphics
FG-CLIP 2 - ведущая в мире графическая кросс-модальная модель визуального языка (VL-M), созданная 360 Artificial Intelligence Research Institute, превосходящая аналогичные модели от Google и Meta в 29 авторитетных бенчмарках, что делает ее самой мощной VL-M на сегодняшний день.Она способна точно определить грубые...

Micro Opinion BettaFish - мультиинтеллектуальная система анализа мнений с открытым исходным кодом
BettaFish - это мультиинтеллектуальная система анализа мнений с открытым исходным кодом. Используя многоинтеллектуальную архитектуру, агенты Query, Media, Insight, Report и другие работают вместе, чтобы достичь замкнутого цикла поиска, извлечения и отчетности. Система поддерживает управляемую искусственным интеллектом полную ...

Ouro - новая циклическая языковая модель с открытым исходным кодом от команды ByteHopper Seed
Ouro - это новый тип Looped Language Models (LLMs), разработанный командой ByteDance Seed, основной инновацией которого является непосредственное построение возможностей вывода на этапе предварительного обучения с помощью рекуррентной вычислительной структуры с общим доступом к параметрам. Модель использует 24 слоя в качестве базового блока, через...
ChronoEdit - ИИ-фреймворк для редактирования изображений с открытым исходным кодом от NVIDIA и Университета Торонто
ChronoEdit, система редактирования изображений с открытым исходным кодом, разработанная NVIDIA совместно с Университетом Торонто, переопределяет задачу редактирования изображений как задачу генерации видео, чтобы обеспечить временное и физическое соответствие результатов редактирования. Путем дистилляции предварительно обученной модели генерации видео с 14B параметрами из...

LongCat-Flash-Omni - полностью модальная модель большого языка для Meituan с открытым исходным кодом
LongCat-Flash-Omni - это полностью модальная модель большого языка с открытым исходным кодом, выпущенная командой LongCat из Meituan. С масштабом параметров 560 миллиардов (27 миллиардов активированных параметров) она позволяет достичь миллисекундного уровня взаимодействия в реальном времени с аудио и видео при сохранении большого количества параметров.
Petri - система аудита безопасности ИИ с открытым исходным кодом от Anthropic
Petri - это система аудита безопасности ИИ с открытым исходным кодом, разработанная компанией Anthropic, которая систематически оценивает безопасность и поведенческую согласованность моделей ИИ. Имитируя реальный сценарий, в котором автоматический аудитор проводит несколько раундов диалога с целевой моделью, а затем агент-судья действует на...
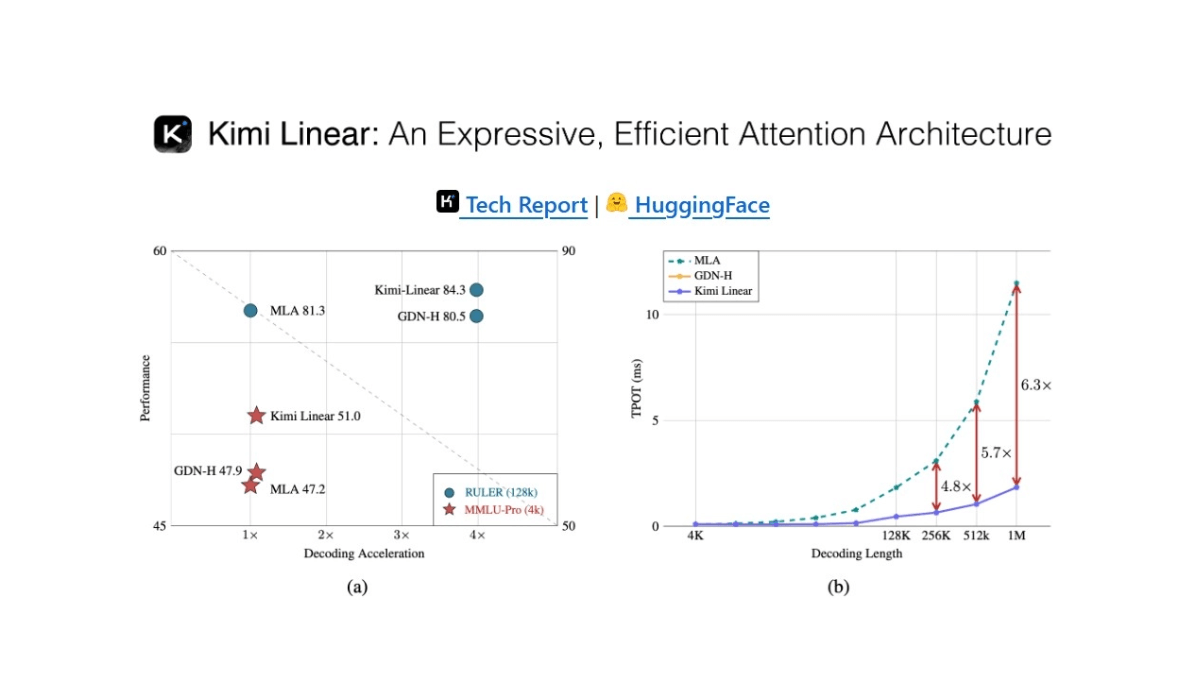
Kimi Linear - новая гибридная архитектура линейного внимания с открытым исходным кодом на темной стороне Луны
Kimi Linear - это новая гибридная архитектура линейного внимания с открытым исходным кодом от Dark Side of the Moon, в основе которой лежит Kimi Delta Attention (KDA), оптимизирующая традиционную модель внимания за счет более тонкого механизма регулировки, значительно повышающего эффективность аппаратного обеспечения и возможности управления памятью...

FIBO - первая в мире программа с открытым исходным кодом, поддерживающая JSON-текст для создания моделей изображений.
FIBO - это первая в мире модель изображений для генерации текста с открытым исходным кодом и поддержкой JSON, разработанная компанией Bria AI. Основанная на архитектуре DiT (Diffusion Transformer) с 8B параметрами, она использует метод обучения Flow Matching...