
TalkCody - бесплатный настольный помощник с открытым исходным кодом, программируемый искусственным интеллектом, с поддержкой сложных задач
TalkCody - это бесплатное настольное приложение-помощник программирования AI с открытым исходным кодом, построенное на Rust + Tauri 2, поддерживающее три платформы - Windows, macOS и Linux, имеющее родную производительность, быстрый запуск и низкое потребление ресурсов. Поддержка более 50 основных A...
MemMachine - система памяти искусственного интеллекта с открытым исходным кодом от MemVerge
MemMachine - это система памяти ИИ с открытым исходным кодом, разработанная компанией MemVerge, предназначенная для моделей и интеллектов ИИ, которая может хранить и вызывать данные о взаимодействии, как человеческий мозг, решая проблему "потери памяти без статики" ИИ. В ней используется многоуровневая архитектура (кратковременная память, долговременная память, пользовательский образ...

PartCrafter - NU United Bytes с открытым исходным кодом для создания 3D-модели одной фигуры
PartCrafter - это передовая генеративная 3D-модель, совместно предложенная Пекинским университетом, ByteDance и Университетом Карнеги-Меллон. Она может генерировать несколько семантически явных и геометрически разнообразных 3D-частей сетки из одного RGB-изображения одновременно. Модель моделируется через комбинаторное потенциальное пространство и...

GigaWorld-0 - GigaVision Open Source World Modelling Framework
GigaWorld-0 - это фреймворк модели мира с открытым исходным кодом от отечественного стартапа GigaAI, который в основном используется для решения проблемы узких мест в области эмбодированного интеллекта (Embodied AI). Эффективно генерируя высококачественные, разнообразные и физически реалистичные обучающие данные, толчок...
Mistral 3 - Mistral AI выпускает новейшую серию мультимодальных больших моделей с открытым исходным кодом
Mistral 3 - это последняя серия мультимодальных больших моделей, выпущенная компанией Mistral AI с открытым исходным кодом. Она состоит из флагманской модели Mistral Large 3 (675B общих параметров) и более легкой версии серии Ministral (3B/8B/14B), обе из которых поддерживают восприятие изображений...

Vidi2 - мультимодальное понимание видео и генеративное макромоделирование с открытым исходным кодом от ByteHop
Vidi2 - это мультимодальная модель понимания и генерации видео второго поколения, открытая компанией ByteDance, ориентированная на понимание, анализ и создание видеоконтента. Она поддерживает совместный ввод текста, видео и аудио, может одновременно понимать содержимое изображения, звуковую информацию и команды на естественном языке для достижения кросс-модального взаимодействия и...
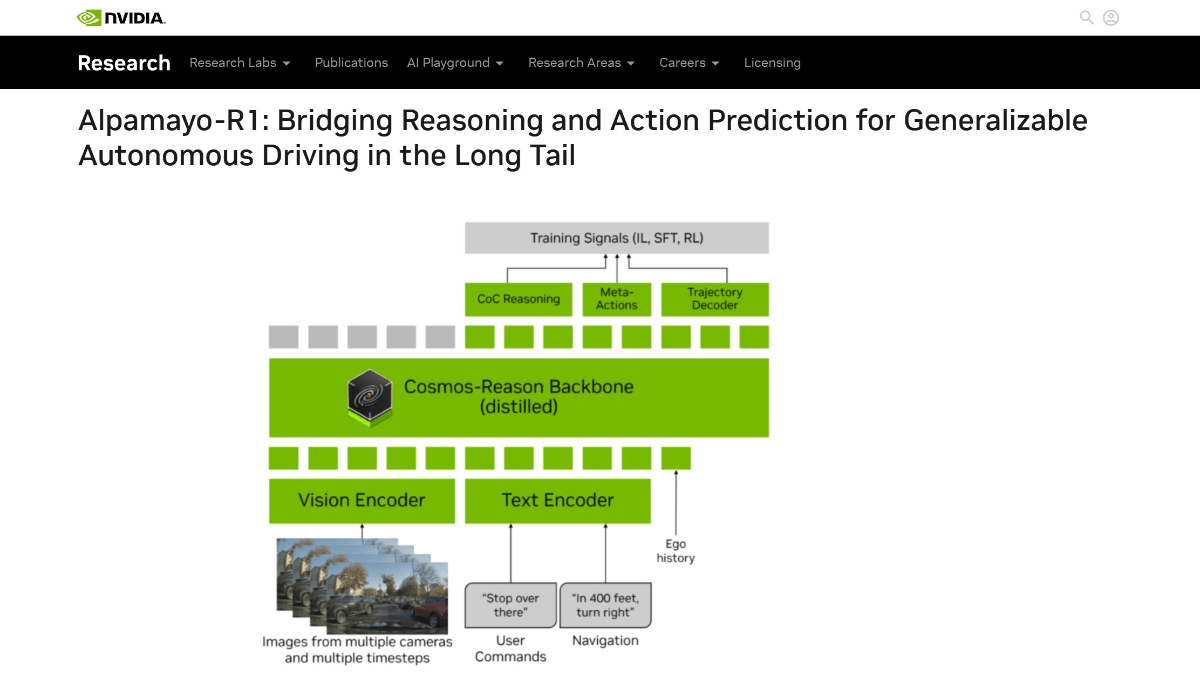
Alpamayo-R1 - открытая модель видения-языка-действия от NVIDIA с возможностями рассуждения
Alpamayo-R1 - это разработанная NVIDIA модель Vision-Language-Action (VLA) с возможностью рассуждений, предназначенная для улучшения способности автономного вождения принимать решения в сложных сценариях. Внедряя механизм рассуждений о причинно-следственных цепочках, автомобиль способен анализировать причинно-следственные связи сценария (например, "из-за предыдущего...

Ovis-Image - Графическая модель венчурной деятельности с открытым исходным кодом от команды Ali AIDC-AI
Ovis-Image - это модель графа с 7 миллиардами параметров, созданная командой AIDC-AI из Alibaba International Digital Commerce Group и ориентированная на высококачественную визуализацию текста. Основанная на архитектуре Ovis-U1, она унаследовала передовой визуальный декодер и двунаправленный очиститель токенов...

Wujie-Emu3.5 - Исследовательский институт Wisdom Source с открытым исходным кодом мультимодальной большой модели мира
Wujie-Emu3.5 - мультимодальная макромодель мира с открытым исходным кодом от Beijing Zhiyuan Artificial Intelligence Research Institute, имеющая 34 миллиарда ссылок и способная моделировать мир. Обученная на 10 триллионах мультимодальных токенов (включая 790 лет видеоданных), она может моделировать законы физики и достигать генерации графики, визуального руководства...
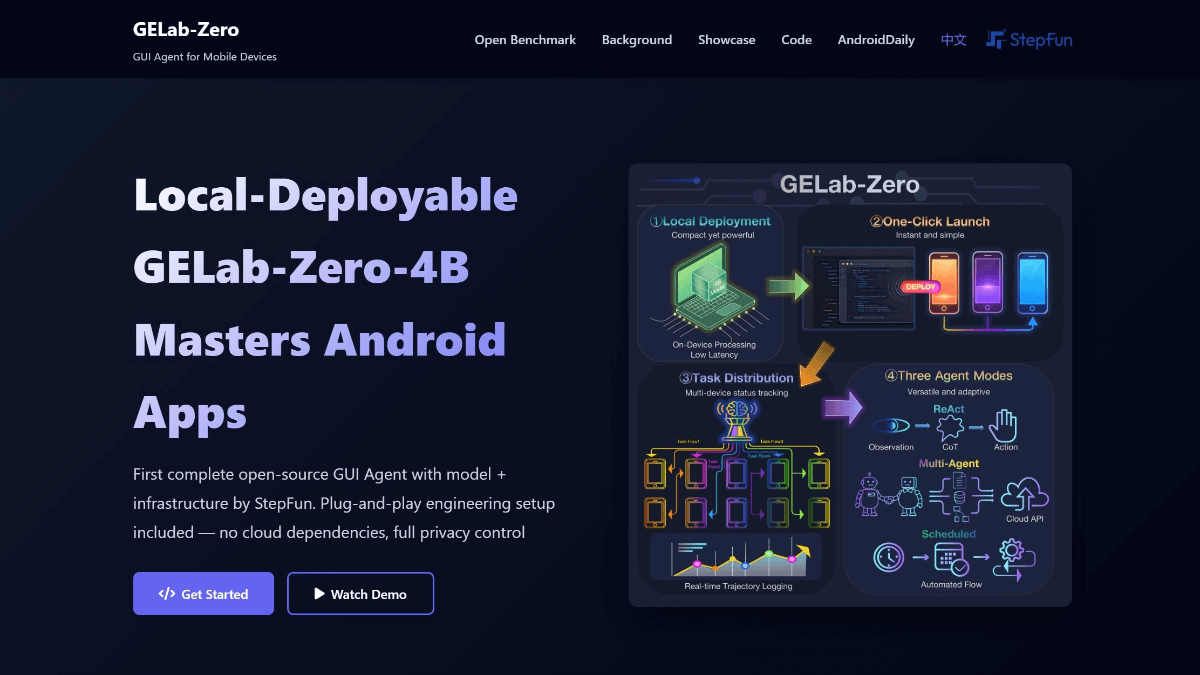
GELab-Zero - мультимодальная GUI-модель агента с открытым исходным кодом от команды Steps
GELab-Zero - это мультимодальная модель агента GUI с открытым исходным кодом от команды Step Leap, построенная на базовой модели Qwen3-VL-4B-Instruct с параметрами 4B. Она может распознавать элементы пользовательского интерфейса и выполнять такие операции, как нажатие, скольжение и т.д., а также поддерживает кросс-прикладную постановку задач...