
Генеральный директор Anthropic поддерживает гегемонию США в области ИИ, называя ее "китайской угрозой

Комментарий:
1. очернение китайских разработок в области ИИ и создание "китайской теории угрозы".
Автор статьи придерживается позиции, что Соединенные Штатынамеренно преувеличивать DeepSeek Так называемая "угроза" для США со стороны технологических достижений китайских ИИ-компаний и других, а также вынужденная ассоциация этого с так называемой "ХХХ-угрозой" - аргумент, который изобилуетменталитет холодной войныответить пениемидеологические предрассудки.
- Автор признает инновационность и эффективность DeepSeek, но затем разворачивается и приписывает ее успех тому, что она "подверглась XXXX, нарушившему XXXX", - необоснованное обвинение, которое полностью игнорирует тот факт, что китайские компании в области ИИ полагаются на свои собственные усилия и рыночные механизмы для достижения успеха.
- Автор использует предлог "предотвращения получения Китаем XX преимуществ" для защиты американской политики контроля экспорта микросхем, но избегает говорить о собственном использовании технологических преимуществ для подавления конкурентов.двойные стандартыРазоблаченный.
2. поддержание технологической гегемонии США и попытка сдержать развитие ИИ в Китае
Основная цель статьи заключается в том, чтобыСохранение глобального доминирования США в области искусственного интеллектаи попытался это сделать:
- Преувеличение роли экспортного контроля:: Автор утверждает, что экспортный контроль - "единственный способ помешать Китаю приобрести миллионы чипов", и рассматривает его как ключевой фактор, определяющий будущий мировой ландшафт. Этот аргумент игнорирует сложность глобальной промышленной цепочки и собственный технологический прогресс Китая.
- На самом деле Китай увеличивает свои инвестиции в исследования и разработку чипов и добился значительного прогресса. Хотя экспортный контроль США оказал определенное влияние на развитие ИИ в Китае, он не может остановить дальнейший прогресс китайских технологий ИИ.
- Пропаганда "технологического разделения":: Автор подразумевает, что Соединенные Штаты должны продолжать укреплять технологическое эмбарго против Китая, и даже предлагает Соединенным Штатам воспользоваться технологией искусственного интеллекта, чтобы создать "прочное преимущество", что, несомненно, выступает за "технологическое разъединение" и идет вразрез с тенденцией глобализации.
- Такой подход нанесет ущерб не только интересам Китая, но и интересам самих Соединенных Штатов, а также будет препятствовать глобальному научно-техническому прогрессу и экономическому развитию.
3. Игнорирование природы развития ИИ и введение общественности в заблуждение
Статья необъективна в своем представлении о развитии ИИ, опереоценитьЗакон масштаба" и "эффект масштаба" игнорируют следующие важные факторы:
- Многополярный тренд в развитии ИИРазвитие технологий ИИ - не единственный путь в США, Китай, Европа и другие страны и регионы активно осваивают путь развития ИИ и добились собственных преимуществ.
- Этика и безопасность искусственного интеллекта:: Этические проблемы и проблемы безопасности, возникающие в связи с развитием ИИ, необходимо решать сообща на основе глобального сотрудничества, а не путем односторонних действий и технологических блокад.
- Влияние искусственного интеллекта на человеческое общество:: Технология ИИ должна в конечном итоге служить развитию и прогрессу человеческого общества, а не становиться инструментом для игр великих держав.
4. Призыв к рациональному взгляду на китайско-американскую конкуренцию в области искусственного интеллекта и продвижению глобального сотрудничества
Перед лицом возможностей и проблем, связанных с развитием ИИ, Китай и США должны:
- Отказ от менталитета игры с нулевой суммойКитай и США не только находятся в конкурентных отношениях в области ИИ, но и должны укреплять сотрудничество и совместно содействовать глобальному прогрессу технологий ИИ и промышленному развитию.
- Укрепление коммуникации и диалога: Обе стороны должны провести углубленный обмен мнениями по ключевым вопросам развития ИИ, чтобы укрепить взаимопонимание и избежать недопонимания и просчетов.
- Совместная разработка правил управления ИИКитай и Соединенные Штаты должны совместно с другими странами содействовать созданию честной, справедливой и инклюзивной глобальной системы управления ИИ, чтобы технологии ИИ приносили пользу всему человечеству.
скорочтение
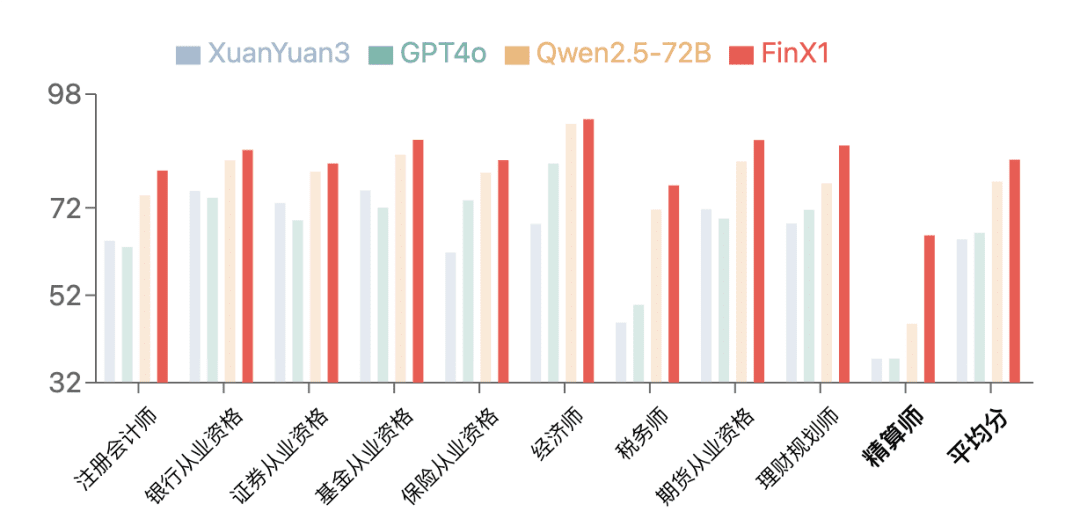
1. Технологические достижения и ценовые преимущества DeepSeek
- Производительность приближается к передовым моделям искусственного интеллекта в СШАМодели, выпущенные компанией DeepSeek (особенно DeepSeek-V3), приближаются по производительности к современным американским моделям в некоторых важных задачах, таких как кодирование, математические соревнования и задачи на рассуждение [Часть II оригинальной статьи "Модели DeepSeek"].
- Значительное сокращение расходовЗатраты на обучение модели DeepSeek гораздо ниже, чем у американских компаний. Например, обучение DeepSeek-V3 обошлось примерно в 6 миллионов долларов, по сравнению с Антропология (используется в форме номинального выражения) Клод 3.5 Обучение Sonnet обходится в десятки миллионов долларов [Часть II оригинальной статьи "Модель DeepSeek"].
- Это не "разрушительный" прорыв.: Авторы утверждают, что достижения DeepSeek не являются "уникальными прорывами", а находятся в пределах ожидаемой кривой снижения стоимости ИИ [Часть II оригинальной статьи "Модель DeepSeek"].
2. Три основных события в развитии искусственного интеллекта
- закон расширенияПо мере увеличения масштаба обучения системы ИИ производительность при решении когнитивных задач плавно улучшается. Например, если размер модели увеличивается с 1 млн до 100 млн долларов, скорость решения задач возрастает с 20% до 60% [Original Article, Part I, "Three Key Dynamics"].
- Криволинейный перенос (физика): Стоимость обучения может быть снижена за счет улучшения архитектуры модели, повышения эффективности аппаратного обеспечения и так далее. Например, стоимость API Claude 3.5 Sonnet примерно в 10 раз ниже, чем у GPT-4 [Часть 1 оригинальной статьи "Три главных события"].
- изменение парадигмыВ процесс обучения ИИ внедряются новые методы обучения, такие как обучение с подкреплением. Например, такие компании, как Anthropic, DeepSeek и другие, изучают возможности использования обучения с подкреплением для обучения моделей с целью улучшения рассуждений [Часть 1 оригинальной статьи "Три больших события"].
3. Ресурсы DeepSeek по сравнению с американскими компаниями, занимающимися разработкой искусственного интеллекта
- Количество чиповDeepSeek располагает примерно 50 000 чипов поколения Hopper (включая H100, H800 и H20), что примерно в 2-3 раза превышает количество чипов, принадлежащих крупным компаниям по производству искусственного интеллекта в США [Часть 2 оригинальной статьи "Модель DeepSeek"].
- капитальные вложенияМежду DeepSeek и американскими ИИ-компаниями нет большой разницы в плане капиталовложений, обе они вложили много денег в исследования и разработки ИИ [Часть 2 оригинальной статьи "Модель DeepSeek"].
4. Экспортный контроль США над Китаем
- управление:: Соединенные Штаты приняли несколько раундов мер по контролю за экспортом чипов в Китай, например, запретили экспорт чипов H100 в Китай и ограничили экспорт чипов H800 [часть II оригинальной статьи "Модель DeepSeek"].
- Эффекты контроля:: Авторы утверждают, что экспортный контроль эффективен и что большинство чипов, использованных DeepSeek, либо не были запрещены, либо были поставлены до введения запрета [часть II оригинальной статьи "Модель DeepSeek"].
- прогноз на будущее:: Автор утверждает, что строгий экспортный контроль является ключом к предотвращению приобретения Китаем миллионов чипов, и что это определит, будет ли будущий мировой ландшафт однополярным или биполярным [часть II оригинальной статьи "Export Controls"].
5. Геополитические последствия развития ИИ
- Китайско-американское соревнование по искусственному интеллекту:: Автор считает, что развитие ИИ приведет к усилению конкуренции между Китаем и США и может привести к биполярной схеме "стран-гениев в центрах обработки данных" [Часть II оригинальной статьи "Экспортный контроль"].
- Американское преимущество:: Автор утверждает, что Соединенные Штаты должны использовать свое технологическое преимущество в области ИИ для создания прочного преимущества, чтобы помешать Китаю добиться доминирования в области ИИ [Часть II оригинальной статьи "Экспортный контроль"].
6. Другие взгляды на развитие ИИ
- Стоимость и ценность ИИХотя стоимость обучения моделей ИИ снизилась с развитием технологий, экономическая ценность возросшего интеллекта моделей ИИ выше, в результате чего компании готовы вкладывать больше денег [Original Article, Part I, "The Three Dynamics"].
- Неопределенность в развитии искусственного интеллекта:: Авторы признают, что в развитии ИИ существуют неопределенности, например, что системы ИИ могут помочь создать более умные системы ИИ, что может привести к превращению временного преимущества в долгосрочное [Часть II оригинальной статьи "Экспортный контроль"].
Критическое чтение Полный текст книги "О DeepSeek и экспортном контроле" автора Anthropic CEO

Несколько недель назад ястатья (в публикации)утверждал, что США должны ужесточить контроль над экспортом китайских чипов. С тех пор китайская компания DeepSeek, занимающаяся разработкой искусственного интеллекта, по крайней мере, в некоторых аспектах приблизилась к производительности передовых моделей искусственного интеллекта в США, но при этом обошлась дешевле.
Здесь я не буду рассматривать вопрос о том, представляет ли DeepSeek угрозу для американских ИИ-компаний, таких как Anthropic (хотя я считаю, что заявления об их угрозе для американского ИИ-лидерства сильно преувеличены). Вместо этого я сосредоточусь на том, ослабляет ли обнародование DeepSeek аргументы в пользу политики экспортного контроля чипов. Я не думаю, что это так. На самом деле.Я думаю, что они делают политику экспортного контроля еще более важной, чем неделю назад..
Экспортный контроль служит важной цели: он позволяет демократическим странам оставаться в авангарде развития ИИ. При этом они не являются способом скрыться от конкуренции между Соединенными Штатами и Китаем. В конечном итоге, если мы хотим одержать победу, компании, занимающиеся разработкой ИИ в США и других демократических странах, должны иметь более совершенные модели, чем Китай. Но мы не должны отдавать Китаю технологическое преимущество, когда нам не нужно XXX.
Три основных события в области искусственного интеллекта
Прежде чем я изложу свои политические аргументы, я опишу три основные динамики систем ИИ, которые имеют решающее значение:
- Расширенные законы. Одна из особенностей искусственного интеллекта, над которой я работал вместе со своими сооснователями в OpenAI, - этоСамые ранние записиОдин из людей с таким характером - это то, чтоПри прочих равных условиях(математика) родУвеличение масштабов обучения систем искусственного интеллекта приводит к плавному улучшению результатов в ряде когнитивных задач. Например, модель стоимостью 1 миллион долларов может решить важную задачу кодирования 20%, модель стоимостью 10 миллионов долларов - 40%, модель стоимостью 100 миллионов долларов - 60% и так далее. Эти различия часто имеют огромное практическое значение - увеличение на порядок может соответствовать разнице в уровне квалификации от бакалавра до кандидата наук - поэтому компании вкладывают значительные средства в обучение этих моделей.
- Сдвиг кривой. В этой области постоянно возникают большие и малые идеи, чтобы сделать вещи более эффективными или более действенными: это может быть моделированиепостроитьУлучшения (доработки архитектуры Transformer, используемой во всех современных моделях) или просто более эффективная работа моделей на базовом оборудовании. Новые поколения аппаратного обеспечения дают тот же эффект. Обычно этокривая передачиЕсли инновация представляет собой 2-кратный "вычислительный множитель" (ВМ), то она позволяет вам потратить $5M вместо $10M на задачу кодирования, чтобы достичь 40%; или $50M вместо $100M, чтобы достичь 60%, и так далее. Любая передовая компания, работающая в области ИИ, регулярно находит множество таких КМ: обычно небольших (~1,2x), иногда средних (~2x), а иногда и очень больших (~10x). Поскольку стоимость владения более умной системой очень высока, такое смещение кривой обычно приводит к тому, что компанияТратить большеВыигрыш в эффективности затрат в конечном итоге используется исключительно для обучения более умных моделей, ограниченных только финансовыми ресурсами компании. Людей, естественно, привлекает идея "сначала что-то дорожает, потом дешевеет" - как будто ИИ - это постоянная масса, и по мере его удешевления мы будем использовать все меньше чипов для его обучения. Но вот что важно.кривая расширенияКогда она сдвигается, мы просто проходим ее быстрее, потому что значение в конце кривой очень велико". В 2020 году моя команда опубликовалаобсудить статью или диссертацию (старая)Это говорит о том, что из-заарифметикапрогресс, кривая смещалась со скоростью примерно 1,68 раза в год. С тех пор этот показатель, вероятно, значительно ускорился; он также не учитывает эффективность и аппаратное обеспечение. Я бы предположил, что сегодня это число, вероятно, составляет около 4 раз в год. По другой оценкездесь. Сдвиг кривой обучения также сдвинул кривую вывода, так что за годы вСохраняя постоянную массу моделиВ то же время происходило значительное снижение цен. Например, Claude 3.5 Sonnet был выпущен через 15 месяцев после оригинального GPT-4 и показал лучшие результаты, чем GPT-4, почти во всех бенчмарках, при этом цена API была снижена примерно в 10 раз.
- Смена парадигмы. Время от времени основной предмет, который расширяется, немного меняется, или в процессе обучения добавляется новый тип расширения. В период с 2020 по 2023 год основными расширяемыми вещами являютсяМодель предварительного обучения: модели, обученные на все большем количестве интернет-текстов, плюс немного других тренировок. в 2024 году модели, обученные с помощьюИнтенсивное обучение(RL) для обучения моделей генерировать цепочки мыслей стало новым фокусом для масштабирования. anthropic, DeepSeek и многие другие (возможно, наиболее заметные OpenAI с выпуском их модели o1-preview в сентябре) обнаружили, что этот вид обучения значительно улучшает производительность в некоторых конкретных, объективно измеряемых задачах (например, математика, соревнования по кодированию и рассуждения, похожие на эти задачи). рассуждения, сходные с этими задачами). Эта новая парадигма включает в себячерез (щель)Обычные предварительно обученные моделиторжественная церемонияВ результате мы получили возможность использовать RL в качестве второго этапа, чтобы добавить навыки рассуждения. Важно отметить, что, поскольку этот тип RL является новым, мы все еще находимся на самых ранних стадиях кривой расширения: расходы на второй этап RL были небольшими для всех участников. Достаточно потратить 1 миллион долларов вместо 100 тысяч, чтобы получить огромную выгоду. Сейчас компании очень быстро работают над тем, чтобы масштабировать вторую фазу до сотен миллионов или даже миллиардов долларов, но важно понимать, что мы находимся в уникальной "точке пересечения", когда новая мощная парадигма находится на ранней стадии кривой масштабирования, а значит, может очень быстро добиться огромных успехов.
Модель DeepSeek
Три вышеуказанные динамики могут помочь нам понять недавний релиз DeepSeek. Около месяца назад DeepSeek выпустила новое программное обеспечение под названием "DeepSeek-V3"Модель, которая представляет собой чистоМодель предварительного обучения-Фаза 1, как уже говорилось выше. Затем на прошлой неделе они выпустили "DeepSeek-R1", добавив вторую фазу. Невозможно определить все детали этих моделей со стороны, но вот мое лучшее представление об этих двух релизах.
DeepSeek-V3является действительно инновационным, идолженОна привлекла внимание людей около месяца назад (мы, конечно, заметили). Как предварительно обученная модель, она, похоже, приближается к производительности современных американских моделей в некоторых важных задачах, при этом ее обучение обходится значительно дешевле (хотя мы обнаружили, что Claude 3.5 Sonnet все еще намного лучше в некоторых других критических задачах, таких как кодирование в реальном мире). Команда DeepSeek добилась этого с помощью некоторых действительно впечатляющих инноваций, в основном Команда DeepSeek добилась этого с помощью некоторых действительно впечатляющих инноваций, в основном направленных на повышение эффективности инженерной деятельности. Особенно инновационными были усовершенствования в управлении кэшем ключевых значений, названные "кэшированием ключевых значений", и в использовании подхода, названного "смешиванием экспертов".
Однако важно внимательно присмотреться:
- DeepSeek не "сделала за 6 миллионов долларов то, что американские ИИ-компании могут сделать за миллиарды долларов". Я могу говорить только за Anthropic, но Claude 3.5 Sonnet - это модель среднего размера, обучение которой обошлось в десятки миллионов долларов (не буду приводить точные цифры). Более того, обучение 3.5 Sonnet никоим образом не было связано с использованием более крупной или более дорогой модели (вопреки некоторым слухам). Sonnet была обучена 9-12 месяцев назад, в то время как модель DeepSeek была обучена в ноябре-декабре, и Sonnet все еще явно впереди по многим внутренним и внешним оценкам. Поэтому я думаю, что справедливым утверждением было бы "DeepSeek выпустила модель с характеристиками, аналогичными американским, 7-10 месяцев назад, по гораздо более низкой цене (но не в тех пропорциях, о которых говорят люди).".
- Если историческая тенденция снижения кривой затрат составляет примерно 4 раза в год, то это означает, что при нормальной деловой активности - при нормальной исторической тенденции снижения затрат, наступающей в 2023 и 2024 годах, - мы ожидали бы получить модель, которая сейчас в 3,5 раза дешевле, чем Sonnet/GPT-4o дешевле в 3-4 раза. Поскольку DeepSeek-V3 хуже этих передовых американских моделей - скажем, примерно в 2 раза хуже на кривой расширения, - я думаю, что это уже довольно щедро для DeepSeek-V3 - это означает, что если DeepSeek V3 обходится примерно в 8 раз дешевле, чем текущая американская модель, разработанная год назад, это будет совершенно нормально и вполне "в тренде". Я не буду приводить конкретные цифры, но из предыдущего пункта ясно, что даже если принять стоимость обучения DeepSeek за чистую монету, она в лучшем случае соответствует тренду, а скорее всего, даже не близка к нему. Например, это меньше, чем разница в стоимости вывода (в 10 раз) от оригинального GPT-4 до Claude 3.5 Sonnet, который является лучшей моделью, чем GPT-4. **Все это говорит о том, что DeepSeek-V3 не является уникальным прорывом и не меняет в корне экономику LLM; это ожидаемая точка на кривой постоянного снижения затрат. Разница в том, что на этот раз китайская компания первой продемонстрировала ожидаемое снижение затрат. **Такого еще не случалось, и это имеет серьезные геополитические последствия. Однако вскоре за ней последуют и американские компании - и сделают они это не за счет копирования DeepSeek, а потому что тоже осознают обычные тенденции снижения затрат.
- У DeepSeek и AI America больше денег и больше чипов, чем когда-либо прежде. Дополнительные чипы используются для исследований и разработок идей, лежащих в основе моделей, а иногда и для обучения больших моделей, которые еще не готовы (или требуют нескольких попыток, чтобы добиться нужного результата). Есть сведения - мы не уверены, что они правдивы, - что у DeepSeek на самом деле есть50 000 Бункерчипов поколения, что, как я полагаю, примерно в 2-3 раза отличается от количества, которым владеют крупные американские компании, занимающиеся разработкой искусственного интеллекта (например, это больше, чем у xAI "Колосс"кластеров в 2-3 раза меньше). Стоимость этих 50 000 чипов Hopper составляет около 1 миллиарда долларов.В результате общие расходы DeepSeek как компании (в отличие от расходов на обучение отдельных моделей) не сильно отличаются от расходов американских ИИ-лабораторий.
- Стоит отметить, что анализ "расширенной кривой" - это немного упрощение, поскольку модели несколько отличаются друг от друга и имеют разные сильные и слабые стороны; показатель расширенной кривой - это грубое усреднение, в котором упущено много деталей. Я могу говорить только о модели Anthropic, но, как я уже упоминал выше, Claude очень хорошо проработан с точки зрения кодирования и способа взаимодействия с людьми (многие люди используют его, чтобы получить личный совет или поддержку). По этим и некоторым дополнительным задачам с DeepSeek просто не сравниться. В расширенных цифрах эти факторы отсутствуют.
R1Это модель, выпущенная на прошлой неделе и вызвавшая большой общественный резонанс (включаяАкции NVIDIA падают на 17%), не так интересен, как V3, с точки зрения инноваций и инженерных решений. Он добавляет второй этап обучения - обучение с подкреплением, как описано в пункте 3 предыдущего раздела, - и по сути повторяет то, что OpenAI сделала с o1 (похоже, они достигли схожих результатов при схожих масштабах)^.8^. Однако, поскольку мы находимся на ранних стадиях кривой расширения, скорее всего, будет несколько компаний, производящих модели такого типа, если только они начнут с сильных предварительно обученных моделей. Учитывая, что V3, вероятно, очень дешев в производстве R1. Таким образом, мы находимся в интересной "точке пересечения", где на данный момент есть несколько компаний, производящих хорошие модели вывода. Это быстро прекратится, так как все компании будут расширять свои кривые на этом типе моделей.
экспортный контроль
Все это лишь прелюдия к основной теме, которая меня интересует: контроль экспорта чипов в Китай. Учитывая эти факты, мой взгляд на ситуацию таков:
- В последнее время наблюдается тенденция, когда компанииТратить все больше и больше.для обучения мощных моделей ИИ, даже если кривая периодически смещается и обучениезаявить заранееСтоимость горизонтального интеллекта модели быстро снижается. Просто экономическая ценность обучения более интеллектуальных моделей настолько велика, что любая выгода от затрат почти сразу жеполностью аннулировать-Они реинвестируются в создание более умных моделей с теми же огромными затратами, которые мы изначально планировали потратить. Поскольку американские лаборатории еще не открыли их, инновации в области эффективности, разработанные DeepSeek, вскоре будут применены лабораториями в США и Китае для обучения моделей стоимостью в миллиарды долларов. Эти модели будут работать лучше, чем многомиллиардные модели, которые они планировали обучать ранее, но они все равно будут стоить миллиарды долларов. Эта цифра будет расти до тех пор, пока мы не достигнем того момента, когда ИИ будет умнее человека почти во всем.
- Создание ИИ, который будет умнее почти всех людей почти во всем, потребует миллионов чипов, обойдется как минимум в десятки миллиардов долларов и, скорее всего, произойдет в 2026-2027 годах. Релизы DeepSeek не меняют этого, поскольку они примерно соответствуют кривой снижения затрат, которая всегда учитывалась в этих расчетах.
- Это означает, что в 2026-2027 годах мы можем жить в двух совершенно разных мирах. В США миллионы необходимых чипов (стоимостью в десятки миллиардов долларов) наверняка будут у нескольких компаний. Вопрос в том, будет ли Китай также иметь доступ к миллионам чипов.
- Если бы они могли, мы бы жили всеверный и южный полюсаСША и Китай обладают мощными моделями ИИ, которые приведут к чрезвычайно быстрому прогрессу в науке и технике - то, что я называю "Нация гениев в центре обработки данных". Биполярный мир не обязательно всегда сбалансирован. Даже если американские и китайские системы ИИ будут на одном уровне, Китай сможет направить больше талантов, капитала и внимания на военное применение технологии. В сочетании с большой промышленной базой и военно-стратегическими преимуществами это может помочь Китаю добиться доминирования на мировой арене, причем не только в области ИИ, но и во всех других аспектах.
- Если Китайне долженПолучите миллионы чипов, и мы (по крайней мере, временно) будем жить вуниполярныйВ мире только Соединенные Штаты и их союзники обладают такими моделями. Неясно, как долго продлится однополярный мир, но, по крайней мере, существует вероятность того, чтоПоскольку системы ИИ в конечном итоге могут помочь создать более умные системы ИИ, временное преимущество может превратиться в долгосрочное.. В результате это мир, в котором Соединенные Штаты и их союзники, скорее всего, займут доминирующее и прочное положение на мировой арене.
- Строгий экспортный контроль - единственное, что может помешать Китаю приобрести миллионы чипов, и поэтому это самый важный фактор, определяющий, в каком мире мы будем жить - однополярном или биполярном.
- Производительность DeepSeek не означает, что экспортный контроль не сработал. Как я уже сказал выше, у DeepSeek есть умеренное или большое количество чипов, поэтому неудивительно, что они смогли разработать и обучить мощную модель. Они не более ограничены в ресурсах, чем американские ИИ-компании, и экспортный контроль не является основным фактором в их "инновациях". Они просто очень талантливые инженеры и показывают, почему Китай является серьезным конкурентом США.
- DeepSeek также не показывает, что Китай всегда сможет достать нужные ему чипы контрабандой или что в системе контроля всегда будут лазейки. Я не верю, что экспортный контроль был разработан так, чтобы помешать Китаю получить десятки тысяч чипов. Миллиард долларов экономической деятельности можно скрыть, но трудно скрыть 100 миллиардов долларов или даже 10 миллиардов долларов. Миллион чипов тоже трудно провезти контрабандой. Опять же, полезно взглянуть на чипы, которыми, по данным DeepSeek, владеет в настоящее время. Согласно SemiAnalysis, это смесь H100, H800 и H20, в общей сложности 50 000 штук. H100 были запрещены экспортным контролем с момента их выпуска, так что если у DeepSeek есть хоть один, он должен был быть получен контрабандой (обратите внимание, что NVIDIAУже объявленоПрогресс DeepSeek "полностью соответствует требованиям экспортного контроля"). H800 был разрешен в первом раунде экспортного контроля в 2022 году, но был запрещен в обновлении контроля в октябре 2023 года, так что, вероятно, они были поставлены до запрета. H20 менее эффективен для обучения, более эффективен для отбора проб. -но все еще разрешен, хотя я считаю, что его следует запретить. Все это говорит о том, что большая часть парка чипов ИИ DeepSeek состоит из чипов, которые не были запрещены (но должны были быть запрещены); чипов, которые были поставлены до запрета; и некоторых чипов, которые с большой вероятностью были ввезены контрабандой. Это говорит о том, что экспортный контроль действительно работает и адаптируется: лазейки закрываются; в противном случае у них мог бы быть полный парк высококлассных H100. Если мы сможем закрыть их достаточно быстро, мы сможем помешать Китаю получить миллионы чипов, увеличивая вероятность однополярного мира, в котором лидируют США.
Учитывая мои опасения по поводу экспортного контроля и национальной безопасности США, я хочу внести ясность. Я не считаю DeepSeek противником как таковым, и мы не сосредотачиваемся конкретно на них. В интервью, которые они дали, они выглядят как умные, любопытные исследователи, которые просто пытаются создать полезную технологию.
Но они подчиняются XXXX, который нарушает XX и ведет себя агрессивно на мировой арене, и если они смогут сравняться с США в области ИИ, то получат еще больше свободы в этом поведении. Экспортный контроль - один из самых мощных инструментов, которые у нас есть для предотвращения этого, и думать, что технология становитсяболее мощныйСоотношение цена/производительностьбольшеЭто повод для отмены экспортного контроля, что совершенно неоправданно.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...