
Инженерная академия искусственного интеллекта: 2.4 Методы объединения данных для систем дополненного поиска (RAG)

краткое содержание
Разбивка данных на части - ключевой этап в системах расширенного поиска (RAG). Она разбивает большие документы на более мелкие, управляемые части для эффективного индексирования, поиска и обработки. В данном руководстве содержится RAG Обзор различных методов разбиения на части, доступных в трубопроводе.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Data_Ingestion
Важность объединения в группы в RAG
Эффективная разбивка на части очень важна для системы RAG, поскольку она позволяет:
- Повышайте точность поиска, создавая связные самодостаточные единицы информации.
- Повышение эффективности генерации вкраплений и поиска сходства.
- Позволяет более точно выбирать контекст при генерации ответов.
- Помощь в управлении языковыми моделями и встроенными системами Токен Ограничения.
Метод разбивки на части
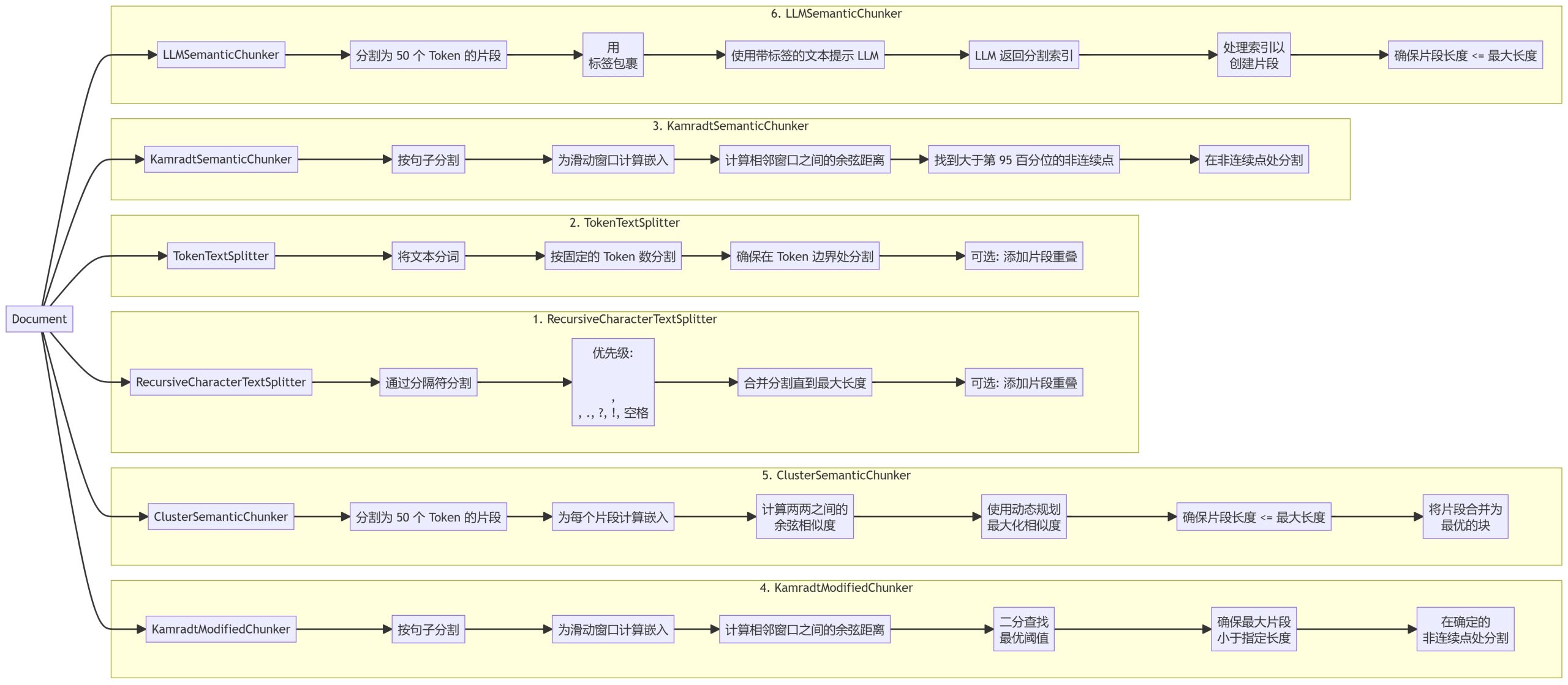
Мы реализовали шесть различных методов разбиения на части, каждый из которых имеет свои преимущества и сценарии использования:
- RecursiveCharacterTextSplitter
- TokenTextSplitter
- KamradtSemanticChunker
- KamradtModifiedChunker
- ClusterSemanticChunker
- LLMSemanticChunker
измельчение
1. RecursiveCharacterTextSplitter
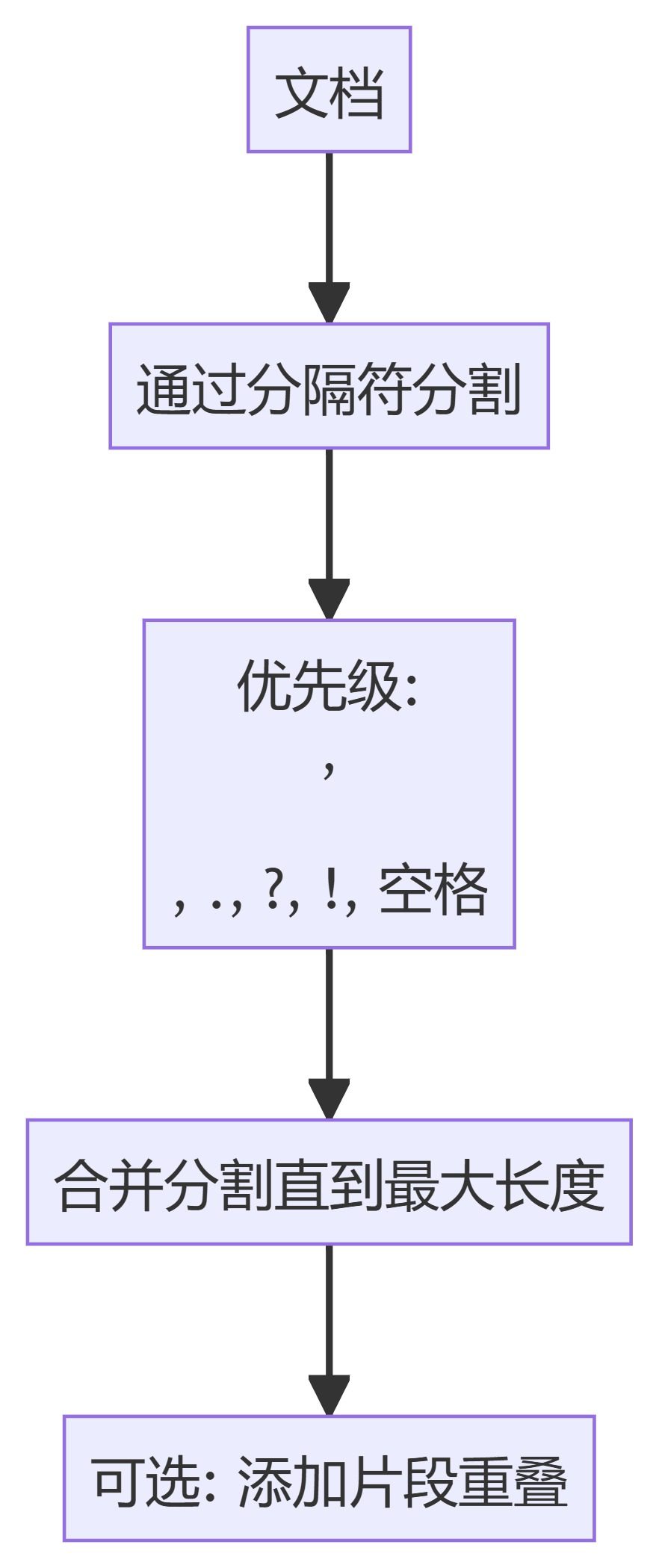
2. TokenTextSplitter

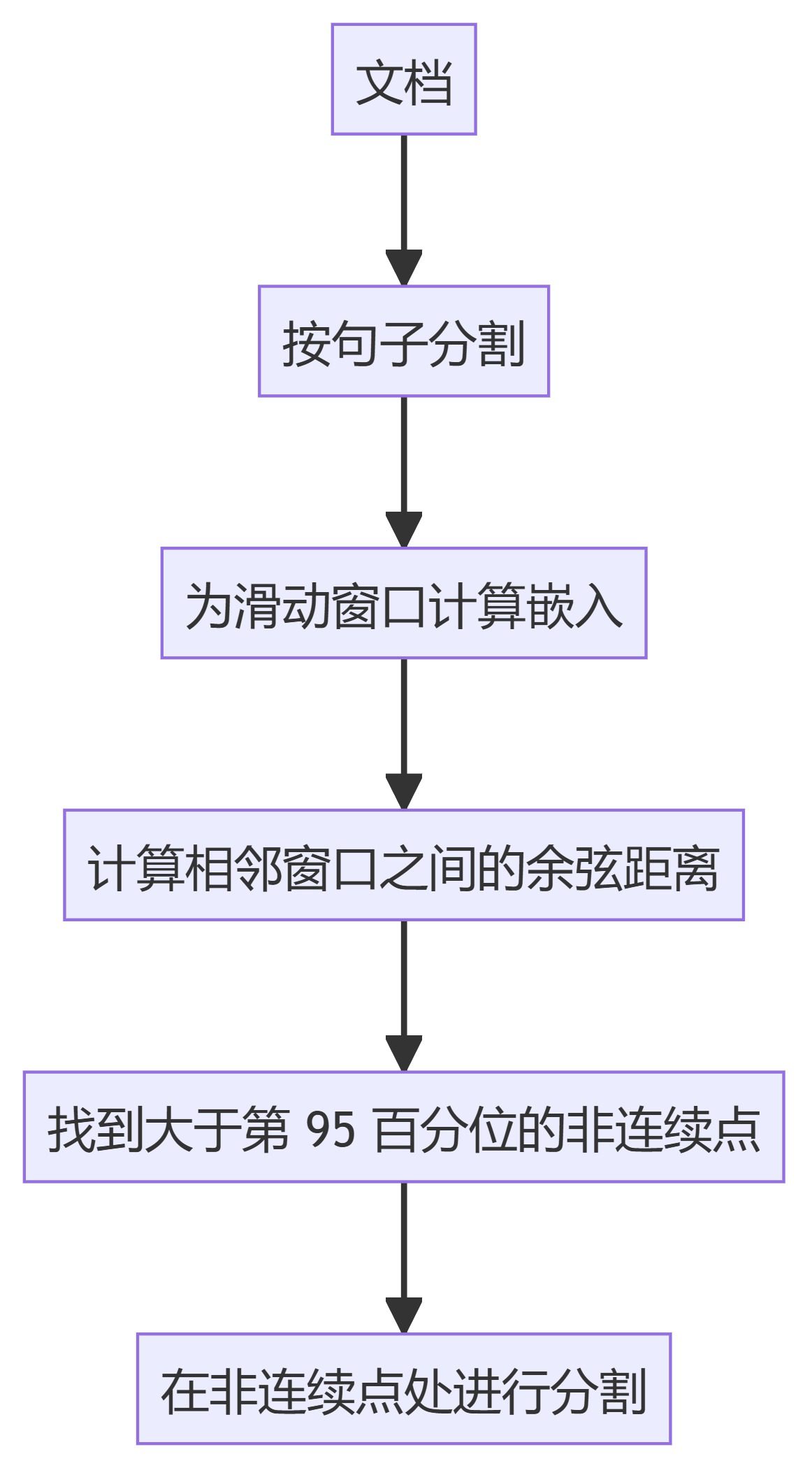
3. KamradtSemanticChunker
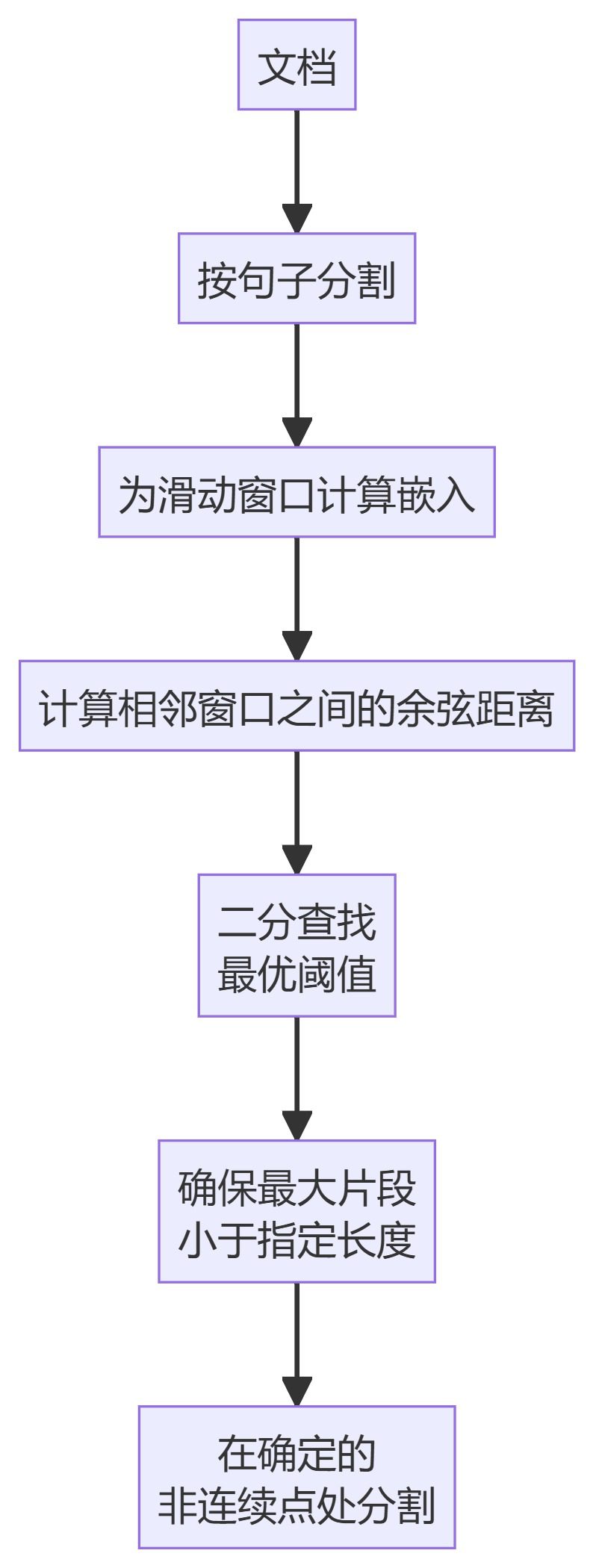
4. KamradtModifiedChunker
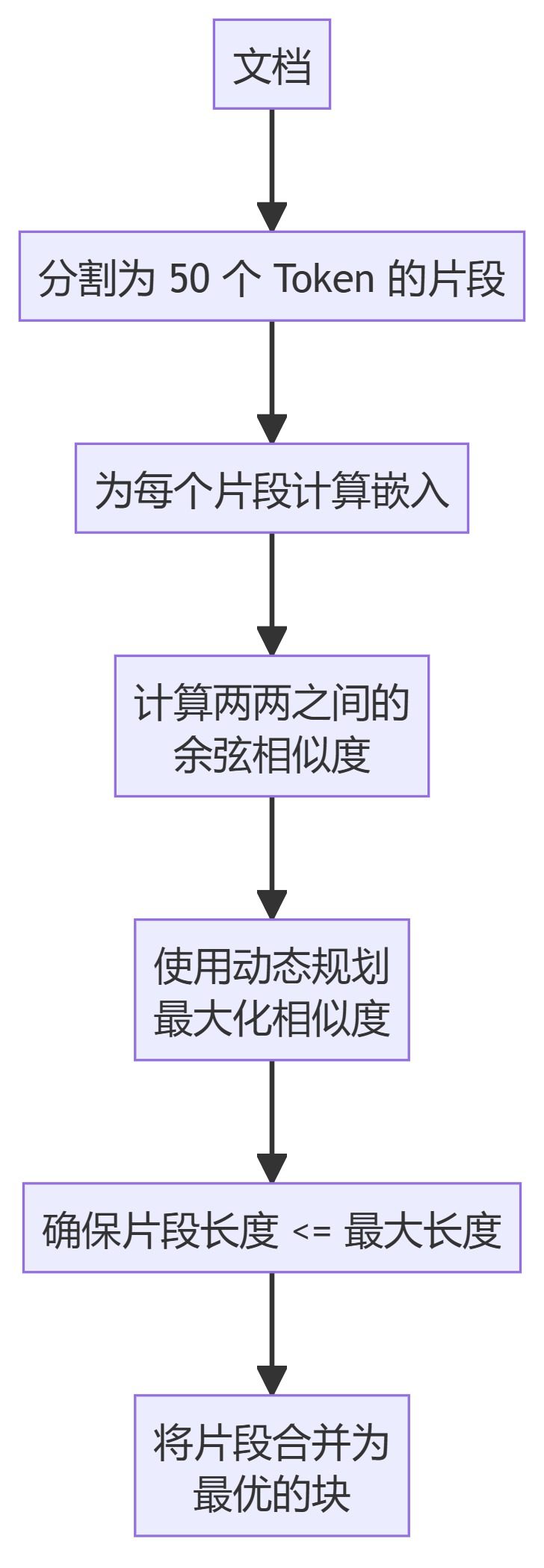
5. ClusterSemanticChunker
6. LLMSemanticChunker
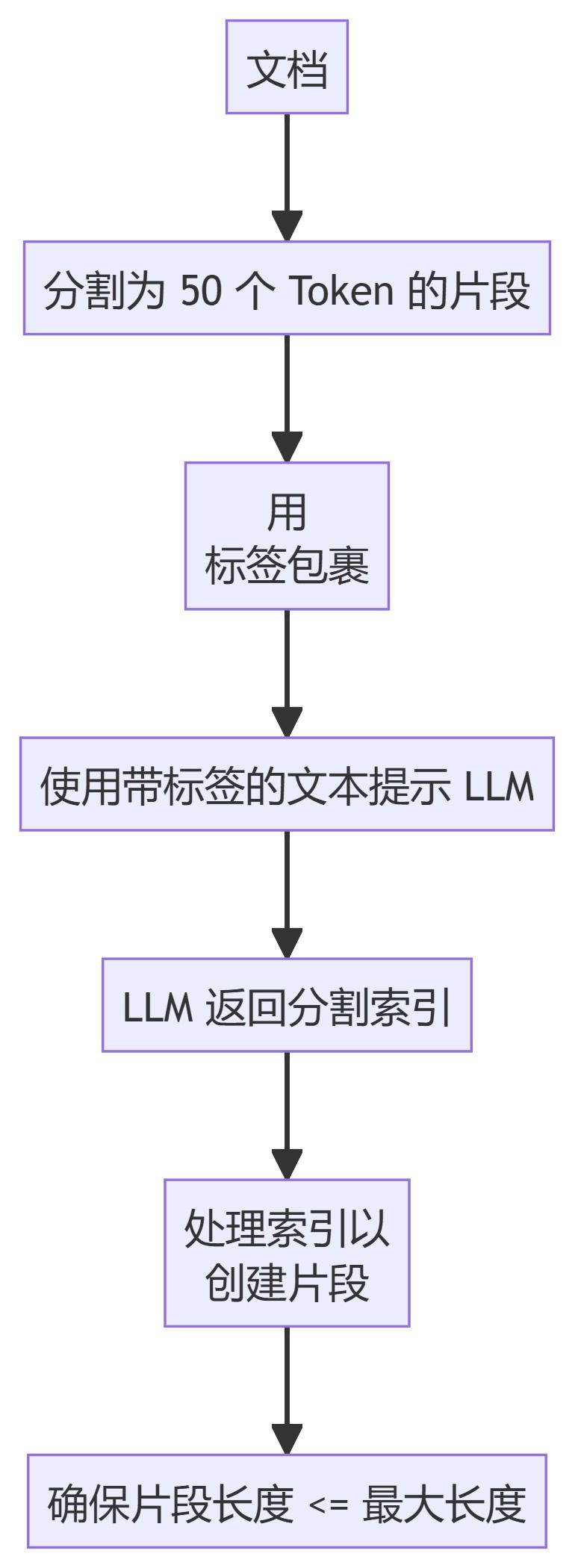
Описание метода
- RecursiveCharacterTextSplitter: Разделите текст на основе иерархии разделителей, отдавая предпочтение естественным точкам разрыва в документе.
- TokenTextSplitter: Разбивает текст на блоки с фиксированным количеством лексем, гарантируя, что разбиение происходит на границах лексем.
- KamradtSemanticChunker: Использование вкраплений со скользящим окном для выявления семантических разрывов и соответствующего сегментирования текста.
- KamradtModifiedChunker: Улучшенная версия KamradtSemanticChunker, которая использует поиск по бисекции для нахождения оптимального порога сегментации.
- ClusterSemanticChunker: Разделите текст на фрагменты, вычислите вкрапления и используйте динамическое программирование для создания оптимальных фрагментов на основе семантического сходства.
- LLMSemanticChunker: Используйте языковое моделирование для определения соответствующих точек сегментации в тексте.
Использование
Чтобы использовать эти методы разбивки на части в процессе RAG:
- через (щель)
chunkersмодуль для импорта необходимых чанкеров. - Инициализируйте чанкер с соответствующими параметрами (например, максимальный размер чанка, перекрытие).
- Передайте документ в чанкер для получения результатов чанкинга.
Пример:
from chunkers import RecursiveCharacterTextSplitter
chunker = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = chunker.split_text(your_document)
Как выбрать метод разбивки на части
Выбор метода разбивки зависит от конкретного случая использования:
- Для простого разделения текста можно использовать RecursiveCharacterTextSplitter или TokenTextSplitter.
- Если требуется сегментация с учетом семантики, рассмотрите варианты KamradtSemanticChunker или KamradtModifiedChunker.
- Для более продвинутого семантического чанкинга используйте ClusterSemanticChunker или LLMSemanticChunker.
Факторы, которые необходимо учитывать при выборе метода:
- Структура документа и типы содержимого
- Требуемый размер куска и перекрытие
- Доступные вычислительные ресурсы
- Специфические требования к поисковой системе (например, векторная или основанная на ключевых словах)
Можно попробовать разные методы и найти тот, который наилучшим образом соответствует вашим потребностям в документировании и поиске информации.
Интеграция с системами RAG
После завершения разбивки на группы обычно выполняются следующие действия:
- Генерируйте вкрапления для каждого фрагмента (для векторных поисковых систем).
- Проиндексируйте эти фрагменты в выбранной поисковой системе (например, в векторной базе данных, в инвертированном индексе).
- При ответе на запрос используйте индексные фрагменты на этапе поиска.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи



Нет комментариев...