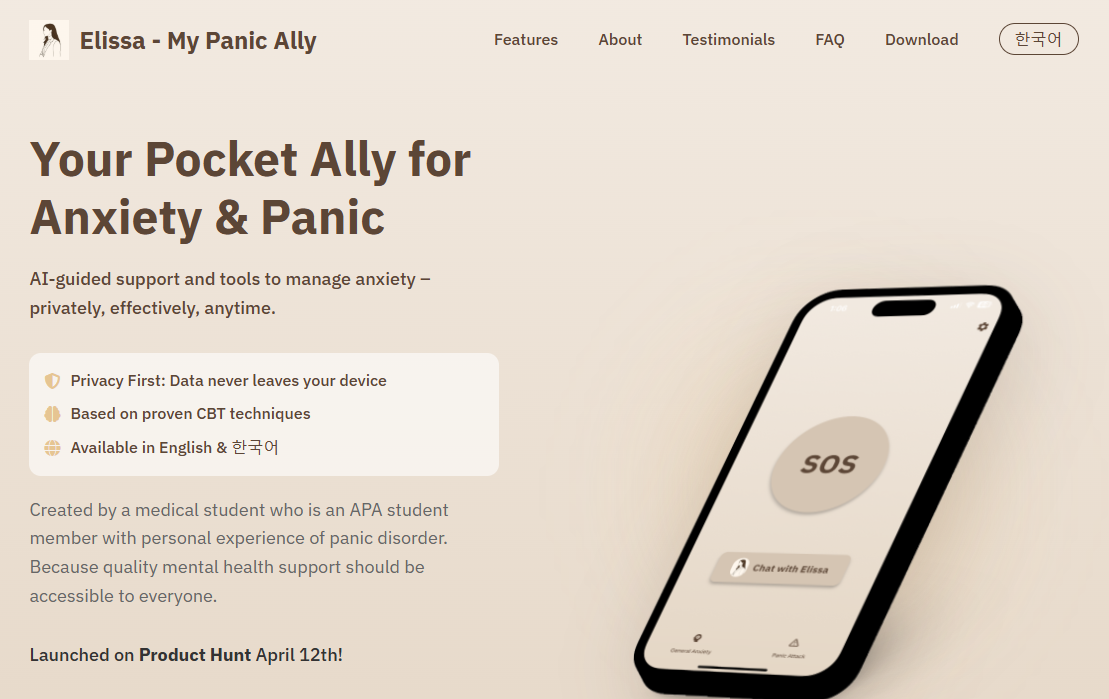
ИИ читает книги: ИИ читает PDF-книги страницу за страницей, автоматически извлекает основные моменты и создает резюме.

Общее введение
AI-reads-books-page-by-page - это интеллектуальный инструмент анализа PDF-книг, разработанный на основе Python, который позволяет автоматизировать постраничный анализ PDF-книг, извлекать ключевые моменты знаний и генерировать поэтапные резюме через заданные интервалы страниц. Проект использует технологию искусственного интеллекта для интеллектуального понимания содержания и создания резюме, что помогает пользователям быстро понять основное содержание книги. Система обладает функцией интеллектуальной фильтрации, которая позволяет автоматически пропускать страницы каталога и оглавления, а также поддерживает продолжение работы с точками останова, что позволяет продолжить обработку с позиции последнего анализа. При выводе проекта используется формат Markdown, который легко читать и распространять, а также поддерживается постоянное хранение базы знаний, чтобы результаты анализа не были потеряны.

Список функций
- Автоматизация анализа PDF книг и извлечение знаний
- Понимание контента и составление резюме на основе искусственного интеллекта
- Сводки о прохождении этапов на основе интервалов
- Система постоянного репозитория баз знаний
- Вывод резюме в формате Markdown
- Цветной вывод клемм для улучшения видимости
- Поддерживает чтение существующих баз знаний с точки останова
- Настраиваемые интервалы анализа и режимы тестирования
- Интеллектуальная фильтрация содержимого (автоматически пропускает оглавления, индексные страницы и т. д.)
- Управление структурой каталога регламентированной продукции
- Хранение базы знаний в формате JSON
- Поддержка выбора пользовательской модели искусственного интеллекта
Использование помощи
1. Подготовка окружающей среды
- Во-первых, убедитесь, что в вашей системе установлена среда Python.
- Клонирование проектов в локальную сеть:
git clone https://github.com/echohive42/AI-reads-books-page-by-page cd AI-reads-books-page-by-page - Установите пакеты зависимостей:
pip install -r requirements.txt
2. базовая конфигурация
Перед использованием необходимо настроить следующие ключевые параметры:
- Поместите анализируемый PDF-файл в корневой каталог проекта.
- показать (билет)
read_books.pyизмените следующую конфигурацию:PDF_NAME: Задайте имя файла PDF как вашеANALYSIS_INTERVAL: Установка интервала анализа (количество страниц)TEST_PAGES: Установка количества тестовых страниц (дополнительно)MODEL: Выбор моделей искусственного интеллекта для обработки страницANALYSIS_MODEL: Выбор моделей искусственного интеллекта для генерирования аналитических данных
3. Описание структуры каталога
Программа автоматически создает следующую структуру каталогов:
book_analysis/knowledge_bases/: Хранение файлов базы знаний в формате JSONbook_analysis/summaries/: Хранение сводных файлов в формате Markdownbook_analysis/pdfs/: Хранение копий файлов PDF
4. Выполнение программы
python read_books.py
5. описание использования расширенных функций
- Контроль интервального анализа
- устанавливать
ANALYSIS_INTERVAL = NoneСводка закрываемых интервалов - Если задать конкретное значение (например, 20), то резюме будет создано для каждых 20 обработанных страниц.
- устанавливать
- тестовый образец
- устанавливать
TEST_PAGES = NoneОбработка целых книг - Задание определенного количества страниц позволяет проводить частичное тестирование
- устанавливать
- возобновить чтение после перерыва
- Программа автоматически сохраняет ход обработки
- При перезапуске программы она будет продолжена с последней обработанной позиции.
- Управление выходными файлами
- Точки знаний хранятся в файлах JSON
- Сводный документ в формате Markdown
- Имена файлов включают временные метки для определения версий
- Пользовательские анализы
- Настраиваемые параметры модели искусственного интеллекта
- Поддержка настройки глубины и способа анализа
- Настраиваемый формат вывода и место хранения
6. Предостережения
- Обеспечьте правильное форматирование PDF-файлов, чтобы избежать их шифрования или повреждения
- При обработке больших PDF-файлов рекомендуется проводить небольшие испытания
- Регулярное резервное копирование документов базы знаний
- Приведение интервалов анализа в соответствие с реальными потребностями
- Мониторинг использования системных ресурсов
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи

Нет комментариев...