Слово "агент" навевает тоску, модели GPT-4 больше не стоят упоминания, а великие программисты подводят итоги "Большой модели 2024".

Эксперты сходятся во мнении, что 2024 год - это год AGI. Это год, когда индустрия большого моделирования изменится навсегда:
GPT-4 от OpenAI больше не является недосягаемой; работа над моделями генерации изображений и видео становится все более реалистичной; были сделаны прорывы в области мультимодальных моделей большого языка, моделей вывода и интеллектов (агентов); а люди все больше заботятся об ИИ .......
Итак, как изменилась индустрия больших моделей за год?
Несколько дней назад известный независимый программист, сооснователь каталога социальных конференций Lanyrd и один из создателей веб-фреймворка Django Саймон Уиллисон в докладе под названием Что мы узнали о магистратуре в 2024 году В статье подробно рассматривается Изменения, сюрпризы и недостатки в индустрии больших моделей в 2024 году.

Некоторые из них приведены ниже:
- В 2023 году обучение модели с рейтингом GPT-4 - большое дело. Однако в 2024 году это даже не особо примечательное достижение.
- За последний год мы добились невероятных успехов в обучении и создании выводов.
- Снижение цен обусловлено двумя факторами: усилением конкуренции и повышением эффективности.
- Те, кто жалуется на медленный прогресс LLM, обычно игнорируют большие достижения в области мультимодального моделирования.
- Оперативная генерация приложений стала товаром.
- Прошли времена свободного доступа к моделям SOTA.
- Интеллигенция, все еще не родившаяся по-настоящему.
- Написание хороших автоматических оценок для систем, управляемых LLM, - это навык, наиболее необходимый для создания полезных приложений на основе этих моделей.
- o1 Ведущие новые подходы к расширенным моделям: решение более сложных задач за счет большего объема вычислений на вывод.
- Американские правила экспорта китайских графических процессоров, похоже, послужили толчком к оптимизации обучения.
- За последние несколько лет потребление энергии и воздействие на окружающую среду при работе операторов значительно снизились.
- Нежелательный и нецензурируемый контент, созданный искусственным интеллектом, - это "помои".
- Ключ к получению максимальной отдачи от LLM - научиться использовать ненадежные, но мощные методики.
- LLM имеет реальную ценность, но осознание этой ценности не является интуитивным и требует руководства.
Не меняя общей направленности оригинального текста, его общее содержание было сокращено следующим образом:
В 2024 году в области моделирования больших языков (LLM) происходит много интересного. Вот обзор того, что мы узнали об этой области за последние 12 месяцев, а также мои попытки определить ключевые темы и ключевые моменты. В том числе 19 Аспекты:
1. Ров ГПТ-4 был "пробит".
В своем обзоре от декабря 2023 года я написал: "Мы пока не знаем, как построить GPT-4.-- В то время GPT-4 был выпущен уже почти год назад, но другие лаборатории искусственного интеллекта еще не создали лучшей модели. Что же OpenAI знает такого, чего не знаем мы?
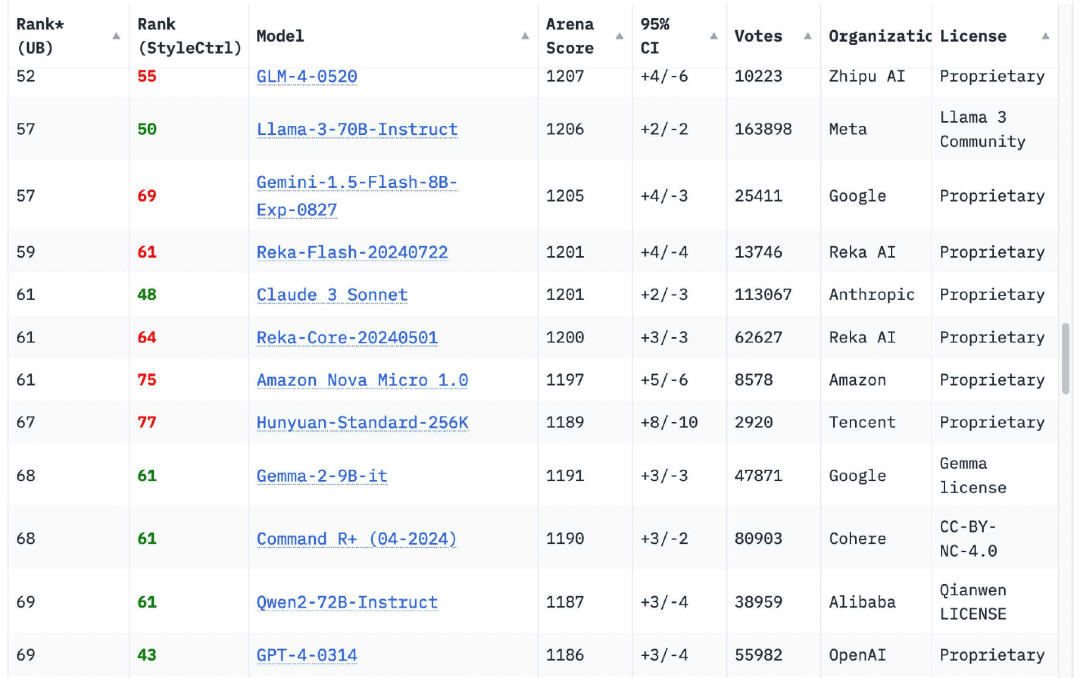
К моему облегчению, за последние 12 месяцев ситуация полностью изменилась. В таблице лидеров Chatbot Arena теперь естьМодели из 18 организацийПо сравнению с оригинальной версией GPT-4 (GPT-4-0314), выпущенной в марте 2023 года, это число достигает 70.
Самым ранним претендентом был выпущенный Google в феврале 2024 года Близнецы 1.5 Pro. Помимо возможности выхода на уровень GPT-4, он предлагает несколько новых функций, среди которыхНаиболее примечательными являются длина контекста ввода 1 миллион (позже 2 миллиона) лексем и возможность ввода видео..
Gemini 1.5 Pro запускает одну из ключевых тем 2024 года: увеличение длины контекста.В 2023 году большинство моделей смогут принимать только 4096 или 8192 токена.Ливийская Арабская Джамахирия Клод Исключением является 2.1, которая принимает 200 000 токенов. Сегодня у каждого поставщика моделей есть модель, принимающая более 100 000 токенов. жетон Модель серии Gemini от Google может принимать до 2 миллионов токенов.
Длинные вводы значительно расширяют спектр проблем, которые можно решить с помощью LLM: теперь вы можете ввести целую книгу и задать вопросы о ее содержании, но что еще важнее, вы можете ввести большое количество примеров кода, чтобы помочь модели правильно решить проблему кодирования. Для меня сценарии использования LLM с длинным вводом данных гораздо интереснее, чем короткие подсказки, основанные исключительно на информации о весах модели. Многие из моих инструментов построены с использованием этой модели.
Переходим к моделям, которые "победили" GPT-4: серия Claude 3 компании Anthropic была представлена в марте, и модель Claude 3 Opus быстро стала моей любимой. В июне они выпустили модель Claude 3.5 Sonnet - и спустя шесть месяцев она все еще остается моей любимой! Шесть месяцев спустя она все еще остается моей любимой.
Конечно, есть и другие. Если вы просмотрите сегодняшнюю таблицу лидеров Chatbot Arena, то увидите, чтоGPT-4-0314 опустился примерно на 70-е место.. В число 18 организаций с высокими показателями модели вошли Google, OpenAI, Alibaba, Anthropic, Meta, Reka AI, Zero One Thing, Amazon, Cohere, DeepSeek, NVIDIA, Mistral, NexusFlow, Smart Spectrum, xAI, AI21 Labs, Princeton University и Tencent.
Обучение модели уровня GPT-4 в 2023 году - это большое дело. Тем не менееВ 2024 году это даже не особенно примечательное достижение.Но лично я все равно радуюсь, когда к списку присоединяется новая организация.
2. Ноутбук, готовый к запуску моделей уровня GPT-4
Мой личный ноутбук - MacBook Pro 2023 64GB M2. Это мощная машина, но ей уже почти два года - и, что более важно, это тот же самый ноутбук, которым я пользуюсь с марта 2023 года, когда я впервые запустил LLM на своем собственном компьютере.
В марте 2023 года на этом ноутбуке по-прежнему будет работать только одна модель уровня GPT-3.Модель GPT-4 теперь способна запускать несколько моделей уровня GPT-4!
Это все еще удивляет меня. Я думал, что для достижения функциональности и качества вывода GPT-4 потребуется один или несколько серверов класса дата-центра с графическими процессорами стоимостью более 40 000 долларов.
Модели занимают 64 ГБ памяти, поэтому я запускаю их нечасто - они не оставляют много места для всего остального.
Тот факт, что они работают, свидетельствует о невероятном росте производительности обучения и вывода, которого мы добились за последний год. Как оказалось, мы собрали много видимых плодов в плане эффективности модели. Надеюсь, в будущем их станет еще больше.
Модели серии Llama 3.2 от Meta заслуживают особого упоминания. Возможно, они не имеют рейтинга GPT-4, но в размерах 1B и 3B они показывают результаты, превосходящие ожидания.
3. цены на LLM значительно снизились благодаря конкуренции и повышению эффективности
За последние двенадцать месяцев стоимость обучения по программе LLM значительно снизилась.
Декабрь 2023 года, OpenAI взимает $30/миллион за входной токен GPT-4(mTok) расходыКроме того, комиссия в размере US$10/мТок взималась за недавно появившийся GPT-4 Turbo и US$1/мТок за GPT-3.5 Turbo.
Сегодня самая дорогая модель o1 от OpenAI доступна по цене $30/mTok!GPT-4o стоит 2,50 доллара (в 12 раз дешевле GPT-4), а GPT-4o mini - 0,15 доллара за тубус, что почти в семь раз дешевле GPT-3,5 и мощнее.
Другие поставщики моделей берут еще меньше: Claude 3 Haiku от Anthropic стоит $0,25/mTok, Gemini 1,5 Flash от Google - $0,075/mTok, а Gemini 1,5 Flash 8B - $0,0375/mTok, что в 27 раз дешевле, чем GPT-3,5 Turbo в 2023 году. Турбо в 2023 году.
Снижение цен обусловлено двумя факторами: усилением конкуренции и повышением эффективности.. Повышение эффективности важно для всех, кто обеспокоен воздействием LLM на окружающую среду. Снижение цен напрямую связано с потреблением энергии для работы операторов.
По поводу воздействия строительства центров обработки данных с искусственным интеллектом на окружающую среду еще есть о чем беспокоиться, но опасения по поводу энергозатрат отдельных операторов уже не заслуживают доверия.
Давайте проведем интересный подсчет: сколько будет стоить создание кратких описаний для каждой из 68 000 фотографий в моей личной фототеке с помощью самого дешевого Gemini 1.5 Flash 8B от Google?
Для каждой фотографии требуется 260 входных маркеров и около 100 выходных маркеров.
260 * 68000 = 17680000 Введите маркер
17680000 * $0,0375/миллион = $0,66
100 * 68000 = 6800000 Выходной токен
6800000 * $0,15/миллион = $1,02
Общая стоимость обработки 68 000 изображений составляет $1,68. Это было так дешево, что я даже трижды посчитал, чтобы убедиться, что все правильно.
Насколько хороши эти описания? Я получил информацию из этой команды:
llm -m gemini-1.5-flash-8b-latest describe -a IMG_1825.jpeg
Это фотография бабочки из Калифорнийской академии наук:

На картинке красное неглубокое блюдо, которое может быть кормушкой для колибри или бабочек. На тарелке лежат дольки оранжевых фруктов.
В кормушке две бабочки, одна - темно-коричневая/черная с белыми/кремовыми отметинами. Другая - более крупная коричневая бабочка со светло-коричневыми, бежевыми и черными отметинами, включая заметные глазные пятна. Эта более крупная коричневая бабочка, похоже, ест фрукты с тарелки.
260 входных маркеров, 92 выходных маркера, стоимость около 0,0024 цента (менее 400 центов).
Повышение эффективности и снижение цен - вот мои любимые тренды 2024 года.Я хочу получить полезность LLM при меньших затратах энергии, и именно этого мы и добиваемся.
4. мультимодальное зрение стало обычным явлением, аудио и видео начинают "появляться
Мой пример с бабочкой, приведенный выше, иллюстрирует еще одну ключевую тенденцию 2024 года: рост мультимодальной модели большого языка (MLLM).
GPT-4 Vision, выпущенный год назад на OpenAI's DevDay в ноябре 2023 года, является самым ярким примером этого. С другой стороны, Google выпустила мультимодальный Gemini 1.0 7 декабря 2023 года.
В 2024 году почти все поставщики моделей выпустили мультимодальные модели.Мы смотрели его в марте. Антропология серии Claude 3, в апреле увидела Gemini 1.5 Pro (изображение, аудио и видео), а в сентябре - Gemini 1.5 Pro (изображение, аудио и видео). Мистраль Pixtral 12B, а также визуальные модели Llama 3.2 11B и 90B от Meta. В октябре мы получили входные и выходные аудиоданные от OpenAI, в ноябре - SmolVLM от Hugging Face, а в декабре - модели изображений и видео от Amazon Nova.
Я думаю.Те, кто жалуется на медленный прогресс LLM, обычно игнорируют значительные достижения в этих мультимодальных моделях.. Возможность запускать подсказки на основе изображений (а также аудио и видео) - это новый интересный способ применения этих моделей.
5. голосовой режим и режим видео в реальном времени для воплощения фантастики в реальность
Особо следует отметить появление моделей аудио и видео в реальном времени.
вместе с ChatGPT Функция диалога появится в сентябре 2023 года, но это в основном иллюзия: OpenAI использует свои превосходные Шепот модель преобразования речи в текст и новая модель преобразования текста в речь (названная tts-1) для обеспечения диалога с ChatGPT, но реальная модель может видеть только текст.
В выпущенном 13 мая OpenAI GPT-4o демонстрируется новая модель речи, действительно мультимодальная модель GPT-4o ("o" означает "omni"), которая может принимать аудиосигнал и выдавать невероятно невероятно реалистичную речь без необходимости использования отдельной модели TTS или STT.
Когда в ChatGPT наконец появился расширенный голосовой режим, результаты были потрясающими.Я часто использую этот режим, когда выгуливаю собаку, и тон стал настолько лучше, что это просто потрясающе!. Я также получил массу удовольствия от использования OpenAI Audio API.
OpenAI - не единственная команда с мультимодальной аудиомоделью. Gemini от Google также принимает аудиосигнал и может говорить в манере, похожей на ChatGPT. Amazon также анонсировала голосовую модель для Amazon Nova раньше срока, но эта модель будет доступна в первом квартале 2025 года.
Google NotebookLM Выпущенная в сентябре, она вывела вывод звука на новый уровень: два "ведущих подкаста" могли вести реалистичные разговоры обо всем, что вы набирали, а позже были добавлены пользовательские команды.
Самое последнее изменение, также появившееся в декабре, - это видео в реальном времени. Голосовой режим ChatGPT теперь позволяет делиться с моделями записями с камеры и обсуждать увиденное в режиме реального времени. Gemini от Google также запустила предварительную версию с теми же функциями.
6. быстрое создание приложений, которые стали товаром
GPT-4 может достичь этого уже в 2023 году, но его ценность станет очевидной только в 2024 году.
Известно, что у LLM потрясающий талант к написанию кода. Если вы сможете правильно написать подсказку, они смогут создать для вас полноценное интерактивное приложение с использованием HTML, CSS и JavaScript - часто за одну подсказку.
Anthropic поднял эту идею на новый уровень, выпустив Claude ArtifactsArtifacts - это принципиально новая функция. С помощью Artifacts Claude может написать для вас интерактивное приложение по требованию, а затем позволить вам использовать его непосредственно в интерфейсе Claude.
Это приложение для извлечения URL-адресов, полностью созданное Клодом:
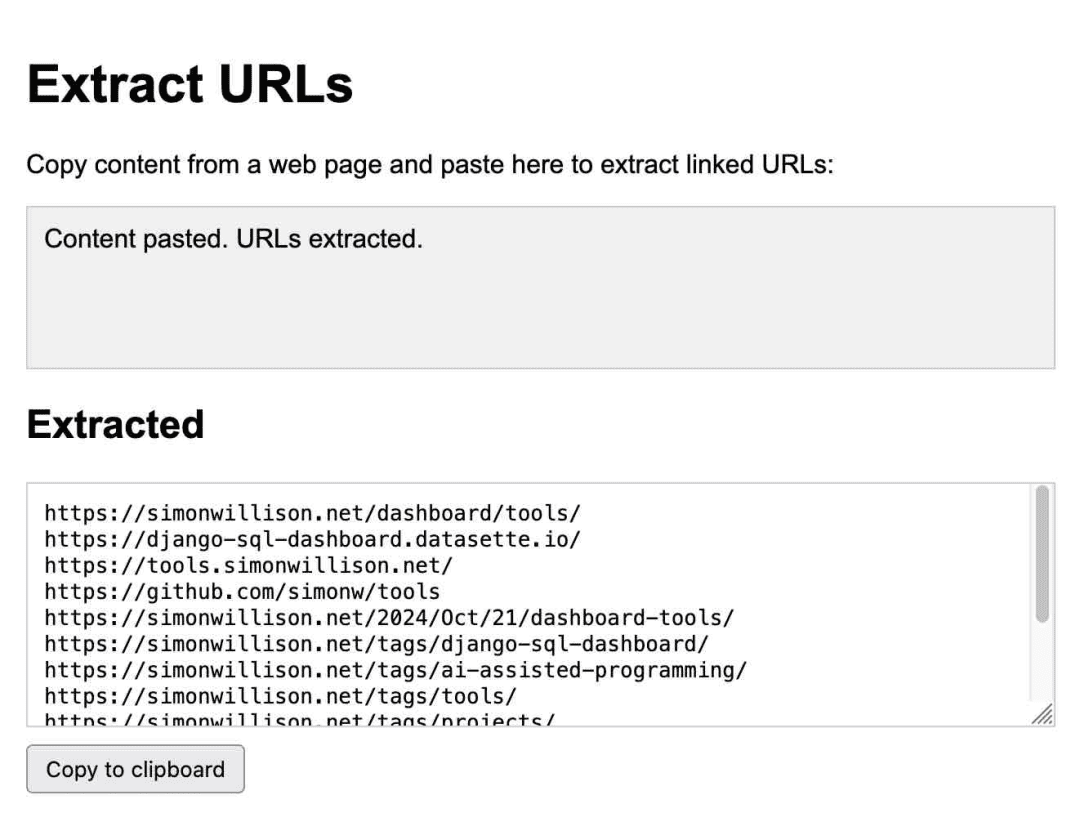
Я пользуюсь им регулярно. В октябре я заметил, как сильно я полагаюсь на него, какЯ создал 14 гаджетов за семь дней с помощью артефактов!.

С тех пор множество других команд создали подобные системы, и в октябре GitHub выпустил свою версию, GitHub Spark, а в ноябре Mistral Chat добавил ее в качестве функции под названием Canvas.
Стив Краузе из Вэлтауна ответил на Cerebras Была создана версия, демонстрирующая, как LLM с 2000 токенов в секунду может итерировать приложение и видеть изменения менее чем за секунду.
А в декабре команда Chatbot Arena запустила новую таблицу лидеров для этой функции, где пользователи дважды создают одно и то же интерактивное приложение, используя две разные модели, и голосуют за ответы. Трудно привести более убедительные аргументы в пользу того, что эта функция теперь является товаром, который может эффективно конкурировать со всеми ведущими моделями.
Я размышлял над этой версией для своего проекта Datasette, цель которого - позволить пользователям использовать prompt для создания и итерации пользовательских гаджетов и визуализации данных на основе собственных данных. Я также нашел похожий паттерн для написания одноразовых программ на Python с помощью uv.
Подобный пользовательский интерфейс, управляемый подсказками, настолько мощный и простой в создании (как только вы разберетесь в хитросплетениях браузерной песочницы), что я ожидаю его появления в качестве функции в различных продуктах к 2025 году.
7. всего за несколько месяцев были популяризированы мощные модели
Всего через несколько месяцев, в 2024 году, мощные модели будут доступны бесплатно для большей части мира.
В мае OpenAI сделал GPT-4o бесплатным для всех пользователей, а Claude 3.5 Sonnet стал бесплатным с его релизом в июне. Это значительное изменение, поскольку в течение последнего года бесплатные пользователи могли использовать модели только уровня GPT-3.5, что в прошлом приводило к неясности для новых пользователей относительно реальных возможностей LLM.
С запуском ChatGPT Pro от OpenAI, похоже, эта эпоха закончилась, скорее всего, навсегда!Подписка за 200 долларов в месяц - единственный способ получить доступ к самой мощной модели o1 Pro. Подписка стоимостью 200 долларов в месяц - единственный способ получить доступ к самой мощной модели o1 Pro.
Ключ к созданию серии o1 (и будущих моделей, которые, несомненно, вдохновят ее) заключается в том, чтобы тратить больше вычислительного времени для получения лучших результатов. Поэтому я думаю, что дни свободного доступа к моделям SOTA прошли.
8. разумные тела, еще не родившиеся по-настоящему
По моему личному мнению.Слово "агент" очень разочаровывает.. У него нет единого, четкого и широко понимаемого значения ....... Но те, кто использует этот термин, похоже, никогда не признают этого.
Если вы говорите мне, что создаете "агента", то вы ничего мне не сообщаете. Не читая ваших мыслей, я никак не могу понять, о каком из десятков возможных определений вы говорите.
Есть два основных типа людей, с которыми я встречаюсьОдна группа считает, что агент - это нечто, действующее от вашего имени, - агент-путешественник, а другая - что агент - это LLM с доступом к инструментам, которые можно запустить в цикл для решения проблемы. Термин "автономия" также часто используется, но четкого определения опять же нет. (Несколько месяцев назад я даже опубликовал в твиттере коллекцию из 211 определений агента, и gemini-exp-1206 попытался обобщить их).
Что бы ни означал этот термин.У агента все еще есть ощущение вечного "скоро будет".. Терминология в сторону.Я все еще скептически отношусь к их практичностиЭто проблема, основанная на доверчивости: магистранты поверят всему, что вы им скажете. Любая система, которая пытается принимать осмысленные решения от вашего имени, сталкивается с тем же препятствием: насколько полезен туристический агент, или цифровой помощник, или даже исследовательский инструмент, если он не может отличить истинное от ложного?
Всего несколько дней назад в поиске Google было обнаружено совершенно ложное описание несуществующего фильма Encanto 2.
Своевременная инъекция - естественное следствие этой доверчивости. Я вижу очень небольшой прогресс в 2024 году в решении этого вопроса, который мы обсуждаем с сентября 2022 года.
Атаки с быстрым внедрением - естественное следствие такой "доверчивости". Я не вижу большого прогресса в отрасли в 2024 году для решения этой проблемы, которую мы обсуждаем с сентября 2022 года.
Я начинаю думать, что самая популярная концепция агента будет опираться на AGI.Создание моделей, устойчивых к "доверчивости", - это действительно высокая задача!.
9. Оценка, очень важно
Аманда Аскелл из Anthropic (для Claude's). Персонаж который в основном и создал эту книгу) сказал:
За хорошей системной подсказкой скрывается скучный, но жизненно важный секрет - это разработка, ориентированная на тестирование. Вы не пишете системную подсказку, а потом думаете, как ее протестировать. Вы пишете тесты, а затем находите системную подсказку, которая проходит эти тесты.
В течение 2024 года стало совершенно очевидно, чтоНапишите отличные автооценки для систем, управляемых LLMИменно эти навыки наиболее необходимы для создания полезных приложений на основе этих моделей. Если у вас есть сильный набор оценочных средств, вы сможете внедрять новые модели быстрее, чем ваши конкуренты, проводить итерации лучше и создавать более надежные и полезные функции продукта.
Мальте Убль, директор по технологиям компании Vercel, считает:
Когда v0 (агент для веб-разработки) только появился, мы были параноидально настроены на защиту подсказок с помощью всевозможных сложных предварительных и последующих обработок.
Мы полностью перешли к тому, чтобы дать ему свободу действий. Без оценки, моделирования и особенно подсказок UX - это как сломанная машина ASML без инструкции.
Я все еще пытаюсь найти лучшую модель для своей работы. Все знают, что оценки важны, но дляПо-прежнему не хватает хорошего руководства о том, как лучше проводить оценку.
10. Apple Intelligence - отстой, но MLX - это здорово!
Как пользователь Mac, я теперь гораздо лучше отношусь к выбранной платформе.
В 2023 году я чувствую, что у меня нет машины с Linux/Windows и графическим процессором NVIDIA, что является огромным недостатком для опробования новых моделей.
Теоретически, Mac с 64 ГБ памяти должен быть хорошей машиной для работы с моделями, поскольку CPU и GPU могут использовать один и тот же объем памяти. На практике многие модели публикуются в виде модельных весов и библиотек, при этом NVIDIA CUDA предпочтительнее других платформ.
llama.cpp Экосистема во многом помогла в этом, но настоящим прорывом стала библиотека MLX от Apple, которая просто фантастична.
Поддержка Apple mlx-lm Python запускает множество mlx-совместимых моделей на моем Mac с отличной производительностью. mlx-сообщество на Hugging Face предоставляет более 1000 моделей, которые были преобразованы в необходимые форматы. Проект принца Канумы mlx-vlm превосходен и быстро развивается, а также приносит визуальные LLM в Apple Проект mlx-vlm принца Канума превосходен и быстро развивается, а также приносит визуальные LLM в Apple Silicon.
В то время как MLX стал переломным моментом в игре, собственные функции Apple Intelligence в основном разочаровали.. Я написал статью об их первоначальном выпуске еще в июне, и тогда я был оптимистично настроен, что Apple сосредоточилась на защите конфиденциальности пользователей и минимизации введения их в заблуждение относительно приложений LLM.
Теперь, когда эти функции доступны, они все еще относительно неэффективны. Как опытный пользователь LLM, я знаю, на что способны эти модели, а функции LLM от Apple - это лишь бледная имитация передовых функций LLM. Вместо этого мы получаем сводки уведомлений, которые искажают заголовки новостей, а инструмент Writing Assistant я вообще не считаю полезным. Тем не менее, Genmoji - это довольно забавно.
11. масштабирование выводов, появление "рассуждающих" моделей
Самым интересным событием последнего квартала 2024 года стало появление новой морфологии LLM, примером которой стали модели o1 от OpenAI - o1-preview и o1-mini были выпущены 12 сентября. Эти модели можно рассматривать как продолжение техники подсказки цепочки мыслей.
Хитрость заключается главным образом в том, чтоЕсли заставить модель хорошенько подумать (проговорить вслух) о проблеме, которую она решает, вы, как правило, получите результат, который модель не смогла бы получить в противном случае..
o1 встраивает этот процесс в модель. Детали немного расплывчаты: модель o1 тратит "жетоны рассуждений" на обдумывание проблемы, которые пользователь не может увидеть напрямую (хотя пользовательский интерфейс ChatGPT покажет сводку), а затем выводит окончательный результат.
Самым большим новшеством здесь является то, что это открывает новый способ расширения модели: теперь модели могут решать более сложные задачи, затрачивая больше вычислительных усилий на вывод.Вместо того чтобы улучшать производительность модели только за счет увеличения объема вычислений во время обучения.
Преемник o1, o3, был выпущен 20 декабря и показал впечатляющие результаты в бенчмарках ARC-AGI, несмотря на то, что затраты на вычислительное время составили более 1 миллиона долларов!
Выход o3 ожидается в январе. Я сомневаюсь, что найдется много людей с реальными проблемами, которые выиграют от такого уровня вычислительных затрат, я точно не знаю! Но, похоже, это реальный следующий шаг в архитектуре LLM для решения более сложных задач.
OpenAI - не единственный игрок здесь: 19 декабря Google выпустила своего первого участника в этом пространстве, gemini-2.0-flash-thinking-exp.
Команда Alibaba Qwen выпустила модель QwQ 28 ноября под лицензией Apache 2.0. Затем, 24 декабря, они выпустили модель визуальных выводов под названием QvQ.
DeepSeek Модель DeepSeek-R1-Lite-Preview была доступна для тестирования через чат-интерфейс 20 ноября.
Примечание редактора: "Спектр мудрости" также был выпущен в последний день 2024 года.Модели глубокого рассуждения GLM-Zero.
Anthropic и Meta еще не достигли прогресса, но я буду очень удивлен, если у них не будет собственной модели расширения выводов.
12. Лучший ли LLM в настоящее время обучается в Китае??
Не совсем, но почти! Это отличный заголовок, который привлекает внимание.
DeepSeek v3 - это огромная параметрическая модель объемом 685 ББ - одна из самых больших публично лицензируемых моделей и гораздо больше, чем самая большая из семейства Llama от Meta, Llama 3.1 405 ББ.
Бенчмарки показывают, что она находится на одном уровне с Claude 3.5 Sonnet, а в бенчмарках Vibe она занимает 7-е место, уступая моделям Gemini 2.0 и OpenAI 4o/o1. На сегодняшний день это самая высокая позиция среди публично лицензированных моделей.
Что действительно впечатляет, так это то, чтоDeepSeek v3Расходы на обучениеНа обучение модели было затрачено 2788000 часов работы H800 GPU при оценочной стоимости $5576000. Модель была обучена за 2788000 часов работы H800 GPU при оценочной стоимости $5576000. Llama 3.1 405B была обучена за 30840000 часов работы GPU, что в 11 раз больше, чем у DeepSeek v3, но базовая производительность модели была несколько хуже.
Американские правила экспорта китайских графических процессоров, похоже, послужили толчком к оптимизации обучения.
13. Улучшено воздействие операционных подсказок на окружающую среду.
Независимо от того, является ли эта модель хостинговой или локальной, одним из приятных результатов повышения эффективности является то, что за последние несколько лет потребление энергии и воздействие на окружающую среду при работе prompt значительно снизились.
Собственные оперативные расходы OpenAI в 100 раз ниже, чем у GPT-3 на тот момент.По моим сведениям, ни Google Gemini, ни Amazon Nova (два самых дешевых поставщика моделей) не работают себе в убыток.
Это означает, что нам, как индивидуальным пользователям, не нужно испытывать чувство вины за энергию, потребляемую подавляющим большинством подсказок. По сравнению с ездой по улице или просмотром видео на YouTube это влияние может быть незначительным.
То же самое касается и обучения. Обучение deepSeek v3 обошлось менее чем в 6 миллионов долларов, что является очень хорошим признаком того, что стоимость обучения может и должна продолжать снижаться.
14. Новые центры обработки данных, нужны ли они еще?
И еще более важная проблема заключается в том, что в будущем возникнет значительное конкурентное давление на создание инфраструктуры, которая понадобится этим моделям.
Такие компании, как Google, Meta, Microsoft и Amazon, тратят миллиарды долларов на строительство новых центров обработки данных, что оказывает огромное влияние на энергосистему и окружающую среду. Поговаривают даже о строительстве новых атомных электростанций, но на это уйдут десятилетия.
Необходима ли эта инфраструктура? Расходы на обучение DeepSeek v3 в размере $6 млн и продолжающееся снижение цен на LLM могут быть достаточными аргументами в пользу этого. Но хотели бы вы оказаться на месте руководителя крупного технологического подразделения, который выступал против этой инфраструктуры, а через несколько лет ему доказали, что он не прав?
Интересным контрастом является развитие железных дорог по всему миру в XIX веке. Строительство этих железных дорог потребовало огромных инвестиций, оказало огромное влияние на окружающую среду, а многие из построенных линий оказались ненужными.
Возникшие пузыри привели к нескольким финансовым крахам, оставив после себя множество полезных объектов инфраструктуры, а также банкротства и экологический ущерб.
15.2024, год "неряхи"
2024 год - год, когда слово "помои" станет художественным термином. написал @deepfates в своем твиттере:
Подобно тому, как "спам" стал нарицательным для обозначения нежелательной электронной почты, "помои" появятся в словаре как нарицательное обозначение нежелательного контента, созданного искусственным интеллектом.
Еще в мае я написал пост, в котором немного расширил это определение:
Под "помоями" понимается нежелательный и нецензурный контент, созданный искусственным интеллектом.
Мне нравится слово "помои", потому что оно вкратце описывает один из способов, с помощью которого мы не должны использовать генеративный ИИ!
16. Синтетические учебные данные, очень эффективно
Удивительно, но понятие "краха модели" - то есть того, что модели ИИ разрушаются при обучении на рекурсивно генерируемых данных, - похоже, глубоко укоренилось в общественном сознании. .
Идея соблазнительна: по мере того как генерируемые ИИ "отбросы" заполоняют Интернет, сами модели будут деградировать, питаясь собственными результатами, что приведет к их неизбежной гибели!
Очевидно, что этого не произошло. Вместо этого мы видим, как лаборатории ИИ все чаще тренируются на синтетическом контенте - создавая искусственные данные, которые помогают направлять их модели в нужное русло.
Одно из лучших описаний, которое я видел, взято из технического отчета Phi-4Ниже перечислены некоторые элементы программы:
Синтетические данные становятся все более распространенной важной частью предварительного обучения, а семейство моделей Phi всегда подчеркивало важность синтетических данных. Синтетические данные не являются дешевой альтернативой реальным данным, а имеют ряд прямых преимуществ перед ними.
Структурированное прогрессивное обучение. В реальных массивах данных связи между лексемами часто бывают сложными и непрямыми. Для того чтобы связать текущую лексему со следующей, может потребоваться множество шагов вывода, что затрудняет эффективное обучение модели на основе предсказания следующей лексемы. В отличие от этого, каждая лексема, генерируемая языковой моделью, предсказывается предыдущей лексемой, что упрощает для модели следование полученному шаблону умозаключений.
Другая распространенная техника - использование больших моделей для создания обучающих данных для меньших, менее дорогих моделей, и все больше лабораторий используют эту технику.
DeepSeek v3 использует DeepSeek-R1 Созданные данные для "умозаключений".При тонкой настройке Meta's Llama 3.3 70B используется более 25 миллионов синтетически сгенерированных примеров.
Тщательная разработка обучающих данных, используемых для LLM, похоже, является ключом к созданию таких моделей. Давно прошли те времена, когда мы брали все данные из Интернета и без разбора подавали их в обучающие программы.
17. Правильно использовать LLM не так-то просто!
Я всегда подчеркивал, что LLM - это мощный пользовательский инструмент, это бензопила, замаскированная под вертолет. Они выглядят простыми в использовании - разве сложно ввести информацию в чат-бот? Но на самом деле.Чтобы извлечь из них максимум пользы и избежать многочисленных подводных камней, необходимо иметь глубокое понимание и большой опыт работы с ними.
В 2024 году эта проблема усугубится.
Мы создали компьютерные системы, с которыми можно разговаривать на человеческом языке, которые могут отвечать на ваши вопросы и, как правило, отвечают правильно! ...... Зависит от того, что это за вопрос, как он задан и может ли он быть точно отражен в неучтенном секретном обучающем наборе.
Сегодня количество доступных систем постоянно растет. В разных системах есть разные инструменты, которые можно использовать для решения вашей задачи, например Python, JavaScript, веб-поиск, генерация изображений и даже запросы к базе данных ....... Поэтому вам лучше понять, что это за инструменты, что они могут делать и как определить, использует ли их LLM.
Знаете ли вы, что в ChatGPT теперь есть два совершенно разных способа запуска Python?
Если вы хотите создать артефакт Claude, который общается с внешним API, вам стоит узнать о HTTP-заголовках CSP и CORS.
Возможно, возможности этих моделей улучшились, но большинство ограничений осталось. o1 от OpenAI, возможно, наконец-то сможет (в основном) вычислять "r" в клубнике, но его возможности все еще ограничены его природой как LLM и его харнессами времени выполнения. o1 не может выполнять веб-поиск или использовать интерпретатор кода, но GPT-4o может - оба находятся в одном и том же пользовательском интерфейсе ChatGPT. GPT-4o может - оба находятся в одном пользовательском интерфейсе ChatGPT.
Что мы сделали для этого? Ничего. Большинство пользователей - "новички". Стандартный пользовательский интерфейс чата LLM - это всё равно, что бросить новичка в терминал Linux и ожидать, что он сможет сделать всё сам.
В то же время все чаще конечные пользователи создают неточные ментальные модели работы и функционирования этих устройств. Я видел множество примеров этого, когда люди пытались выиграть спор с помощью скриншотов ChatGPT - что по своей сути является смехотворным предложением, учитывая ненадежность этих моделей, а также тот факт, что вы можете заставить их сказать что угодно, если дадите правильную подсказку.
Есть и обратная сторона: многие "бывалые" вообще отказались от LLM, потому что не понимают, как можно извлечь пользу из инструмента, у которого так много недостатков. Ключ к получению максимальной отдачи от LLM - научиться использовать эту ненадежную, но мощную технику. Это явно не очевидный навык!
Несмотря на то, что в мире существует огромное количество полезного образовательного контента, мы должны работать лучше, а не отдавать все это на откуп искусственному интеллекту, который яростно пишет в Твиттере.
18. Плохое познание, все еще присутствует
Сейчас.Большинство людей слышали о ChatGPT, но многие ли слышали о Клоде?
Между теми, кто активно озабочен этими вопросами, и теми, кто не озабочен, 99% существуетВеликий разрыв в знаниях.
В прошлом месяце мы наблюдали популярность интерфейсов реального времени, в которых вы можете навести камеру телефона на что-то и рассказать об этом голосом ....... Есть также возможность заставить его притвориться Дедом Морозом. Большинство самоутверждающихся людей (sic "nerd") еще не пробовали это.
Учитывая постоянное (и потенциальное) влияние этой технологии на общество, я считаю, что в настоящее времяЭто разделение нездорово. Я хотел бы видеть больше усилий для улучшения ситуации.
19.LLM, нужна лучшая критика
Многие люди действительно ненавидят LLM. На некоторых сайтах, которые я часто посещаю, даже предположения о том, что "LLM очень полезен", достаточно, чтобы начать войну.
Я понимаю. Есть много причин, по которым людям не нравится эта технология - воздействие на окружающую среду, недостаточная достоверность данных о тренировках, непозитивные приложения, потенциальное влияние на работу людей.
LLM определенно заслуживает критики.Нам необходимо обсудить эти вопросы, найти способы их решения и помочь людям научиться ответственно использовать эти инструменты, чтобы их положительное применение перевешивало негативное воздействие.
Мне нравятся люди, которые скептически относятся к этой технологии. Уже более двух лет шумиха нарастает, и в эфире появляется много дезинформации. На основе этой шумихи было принято множество неверных решений.Критика - это добродетель.
Если мы хотим, чтобы люди, обладающие правом принятия решений, принимали правильные решения о том, как применять эти инструменты, мы должны сначала признать, что существуют действительно хорошие варианты их применения, а затем помочь объяснить, как использовать их на практике, избегая при этом многих непрактичных подводных камней.
Я думаю.Говорить людям, что вся область - это экологически вредная машина плагиата, которая постоянно что-то выдумывает, независимо от того, сколько в этом правды, - значит оказывать этим людям плохую услугу... Здесь есть реальная ценность, но осознание этой ценности не является интуитивным и требует руководства.
Те из нас, кто разбирается в этих вещах, обязаны помочь другим разобраться в них.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи


Нет комментариев...