
HuggingFace раскрывает технические детали, лежащие в основе o1, и делает его открытым!

Если маленьким моделям дать больше времени на размышления, они могут превзойти более крупные модели.
В последнее время в индустрии наблюдается небывалый энтузиазм по отношению к маленьким моделям, которые с помощью нескольких "практических трюков" позволяют им превзойти большие модели по производительности.
Можно утверждать, что фокусировка на улучшении производительности небольших моделей имеет следствие. При разработке больших языковых моделей доминировало масштабирование времени обучения и вычислений. Хотя эта парадигма оказалась очень эффективной, ресурсы, необходимые для предварительного обучения все более крупных моделей, стали непомерно дорогими, и появились многомиллиардные кластеры.
В результате эта тенденция вызвала большой интерес к другому дополнительному подходу, а именно к масштабированию вычислений в тестовое время. Вместо того чтобы полагаться на все большие бюджеты предварительного обучения, методы тестового времени используют динамические стратегии вывода, которые позволяют моделям "думать дольше" над более сложными задачами. Ярким примером этого является модель o1 от OpenAI, которая демонстрирует устойчивый прогресс в решении сложных математических задач по мере увеличения объема вычислений в тестовое время.
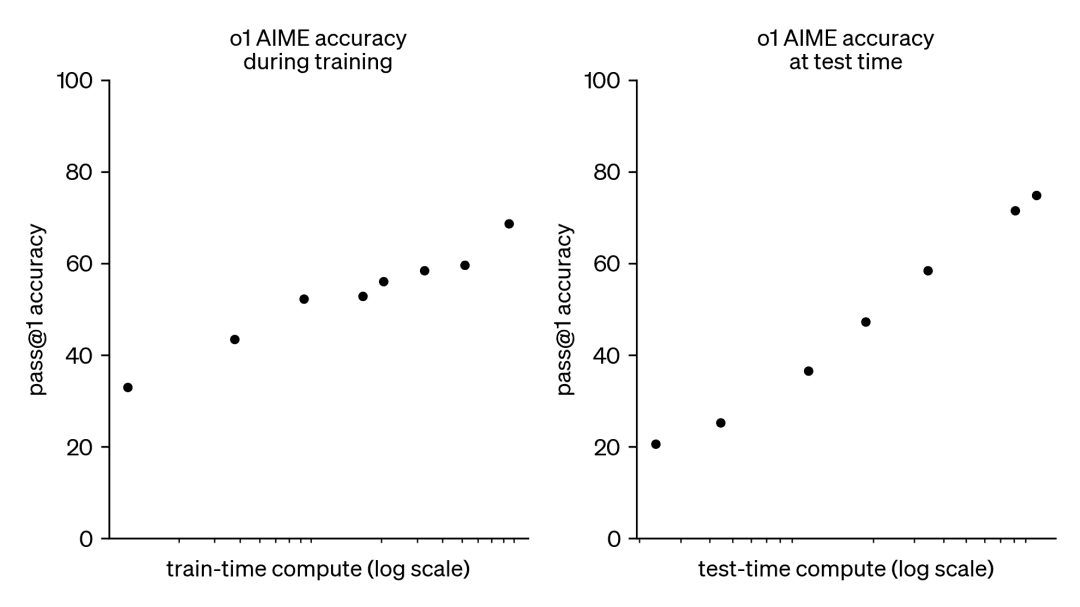
Хотя мы не знаем, как именно происходит обучение o1, недавние исследования DeepMind показывают, что оптимальное масштабирование вычислений в тестовое время может быть достигнуто с помощью таких стратегий, как итеративное самосовершенствование или поиск в пространстве решений с помощью модели вознаграждения. Благодаря адаптивному распределению вычислений в тестовое время на основе подсказок за подсказками, небольшие модели могут соответствовать, а иногда и превосходить большие, ресурсоемкие модели. Масштабирование времени вычислений особенно полезно, когда память ограничена, а имеющегося оборудования недостаточно для запуска больших моделей. Однако этот многообещающий подход был продемонстрирован на модели с закрытым исходным кодом, и никаких деталей реализации или кода не было опубликовано.
Документ DeepMind: https://arxiv.org/pdf/2408.03314
В течение последних нескольких месяцев HuggingFace занималась тем, что пыталась перепрограммировать и воспроизвести эти результаты. Они собираются представить их в этой записи в блоге:
- Вычислительно-оптимальное масштабирование (compute-optimal scaling):Улучшите математическую мощь открытых моделей во время тестирования, внедрив трюки DeepMind.
- Diversity Validator Tree Search (DVTS):Это расширение, разработанное для техники поиска бутстрап-дерева валидатора. Этот простой и эффективный подход увеличивает разнообразие и обеспечивает лучшую производительность, особенно при тестировании с большим вычислительным бюджетом.
- Ищите и учитесь:Легкий набор инструментов для реализации поисковых стратегий с использованием LLM с vLLM Добейтесь увеличения скорости.
Насколько хорошо оптимальное с вычислительной точки зрения масштабирование работает на практике? На приведенном ниже графике очень маленькие модели Llama Instruct размером 1B и 3B превосходят гораздо более крупные модели размером 8B и 70B в сложном бенчмарке MATH-500, если дать им достаточно "времени на размышление".
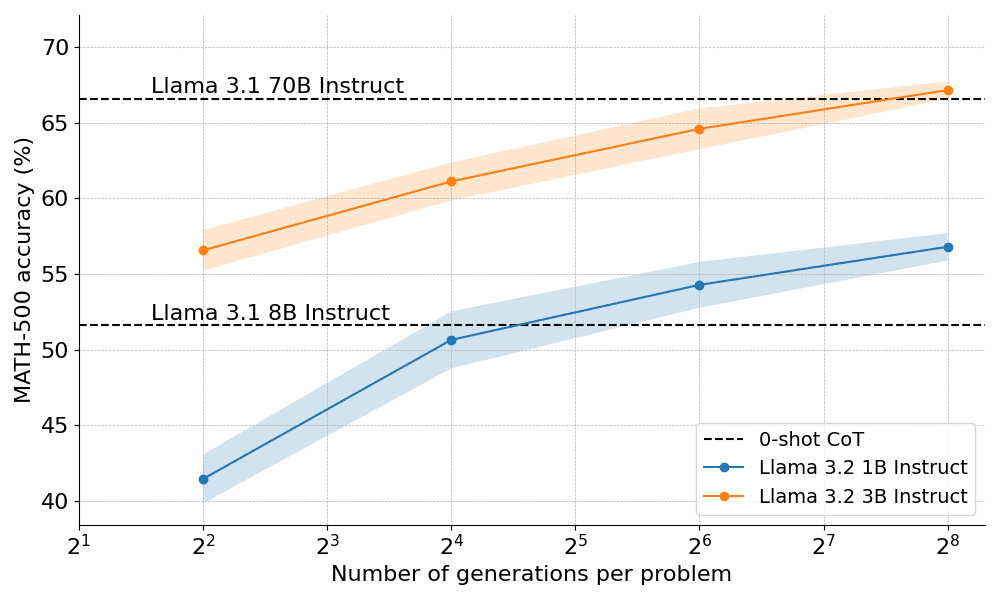
Спустя всего 10 дней после публичного дебюта OpenAI o1 мы с радостью представляем версию с открытым исходным кодом прорывной технологии, лежащей в основе ее успеха: Extended Test-Time Computing", - говорит Клем Деланг, сооснователь и генеральный директор HuggingFace. Благодаря увеличению времени на обдумывание модель 1B может победить 8B, а модель 3B - 70B. Разумеется, полный рецепт - с открытым исходным кодом".
Нетизены из всех слоев общества не успокаиваются при виде этих результатов, называя их невероятными и считая это победой миниатюр.

Далее HuggingFace углубляется в причины этих результатов и помогает читателям понять практические стратегии реализации вычислительного масштабирования при тестировании.
Расширенная стратегия вычислений в тестовое время
Существует две основные стратегии расширения вычислений во время тестирования:
- Самосовершенствование: модель итеративно улучшает свой результат или "идею", выявляя и исправляя ошибки в последующих итерациях. Хотя эта стратегия эффективна в некоторых задачах, она обычно требует, чтобы модель имела встроенный механизм самосовершенствования, что может ограничить ее применимость.
- Поиск по валидатору: этот подход направлен на генерацию нескольких ответов-кандидатов и использование валидатора для выбора лучшего ответа. Валидаторы могут быть основаны на жестко закодированной эвристике или на обучаемых моделях вознаграждения. В этой статье мы сосредоточимся на обучаемых валидаторах, которые включают такие техники, как выборка Best-of-N и древовидный поиск. Такие стратегии поиска более гибкие и могут адаптироваться к сложности задачи, хотя их производительность ограничена качеством валидатора.
HuggingFace специализируется на методах поиска, которые являются практичными и масштабируемыми решениями для вычислительной оптимизации во время тестирования. Вот три стратегии:
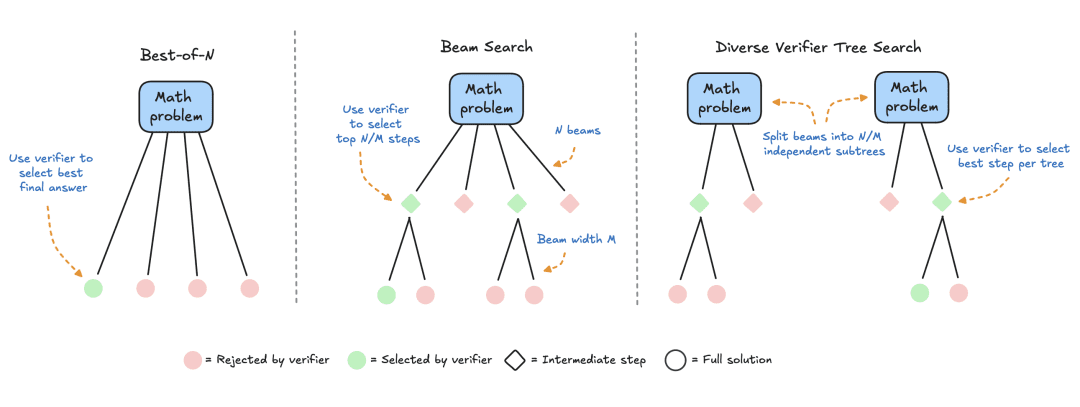
- Best-of-N: обычно использует модель вознаграждения для создания нескольких ответов на каждый вопрос и присваивает оценку каждому ответу-кандидату, а затем выбирает ответ с наибольшим вознаграждением (или взвешенный вариант, о котором речь пойдет ниже). Этот подход делает акцент на качестве ответов, а не на их частоте.
- Кластерный поиск: метод систематического поиска для изучения пространства решений, часто используемый в сочетании с моделями вознаграждения за процесс (PRM) для оптимизации выборки и оценки промежуточных этапов решения задачи. В отличие от традиционных моделей вознаграждения, которые дают один балл за окончательный ответ, PRM предоставляют серию оценок, по одной за каждый этап процесса рассуждения. Такая возможность тонкой обратной связи делает PRM естественным выбором для методов поиска LLM.
- Diversity Validator Tree Search (DVTS): расширение кластерного поиска, разработанное HuggingFace, которое разбивает исходный кластер на отдельные поддеревья, а затем жадно расширяет эти поддеревья с помощью PRM. Этот подход улучшает разнообразие и общую производительность решения, особенно если вычислительный бюджет на момент тестирования велик.
Экспериментальная установка
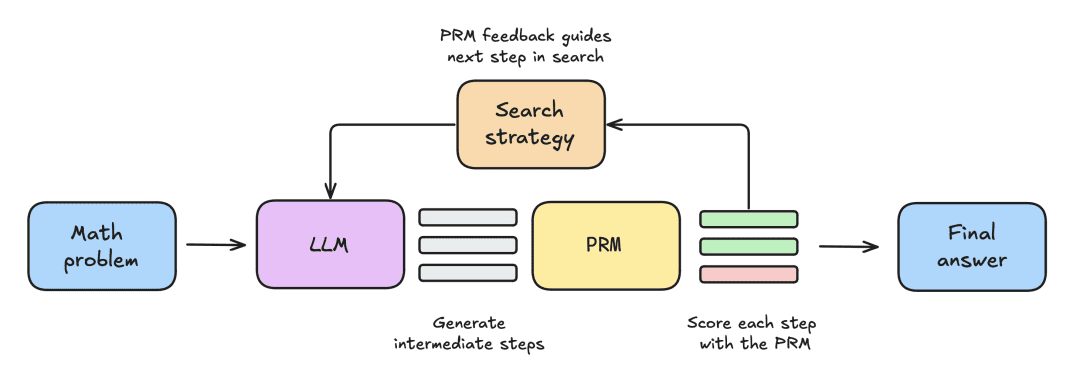
Экспериментальная установка состояла из следующих этапов:
- Сначала LLM задается математическая задача, для решения которой необходимо сгенерировать N частичных решений, например, промежуточных шагов в процессе деривации.
- Каждый шаг оценивается PRM, который оценивает вероятность того, что каждый шаг закончится правильным ответом.
- После завершения стратегии поиска окончательные решения-кандидаты сортируются PRM для получения окончательного ответа.
Для сравнения различных стратегий поиска в данной работе используются следующие модели и наборы данных из открытых источников:
- Модели: используйте meta-llama/Llama-3.2-1B-Instruct в качестве основной модели для расчетов расширенного времени тестирования;
- Процессуальная модель вознаграждения PRM: Для управления стратегией поиска в данной работе используется RLHFlow/Llama3.1-8B-PRM-Deepseek-Data, обученная 8-ми миллиардная модель вознаграждения под наблюдением процесса. Контроль процесса - это метод обучения, при котором модель получает обратную связь на каждом этапе процесса рассуждений, а не только по конечному результату;
- Набор данных: Эта работа была оценена на подмножестве MATH-500, эталонном наборе данных MATH, выпущенном OpenAI в рамках исследования, проводимого под контролем процесса. Эти математические задачи охватывают семь тем и являются сложными как для человека, так и для большинства моделей больших языков.
В этой статье мы начнем с простого базового уровня, а затем постепенно включим другие техники для улучшения производительности.
большинство голосов
Голосование по большинству голосов - наиболее простой способ агрегирования результатов LLM. Для заданной математической задачи генерируется N решений-кандидатов и выбирается ответ с наибольшей частотой встречаемости. Во всех экспериментах в данной работе было отобрано до N=256 решений-кандидатов, с параметром температуры T=0.8, и сгенерировано до 2048 лексем для каждой задачи.
Вот как большинство голосов проявило себя при применении к инструкции Llama 3.2 1B:
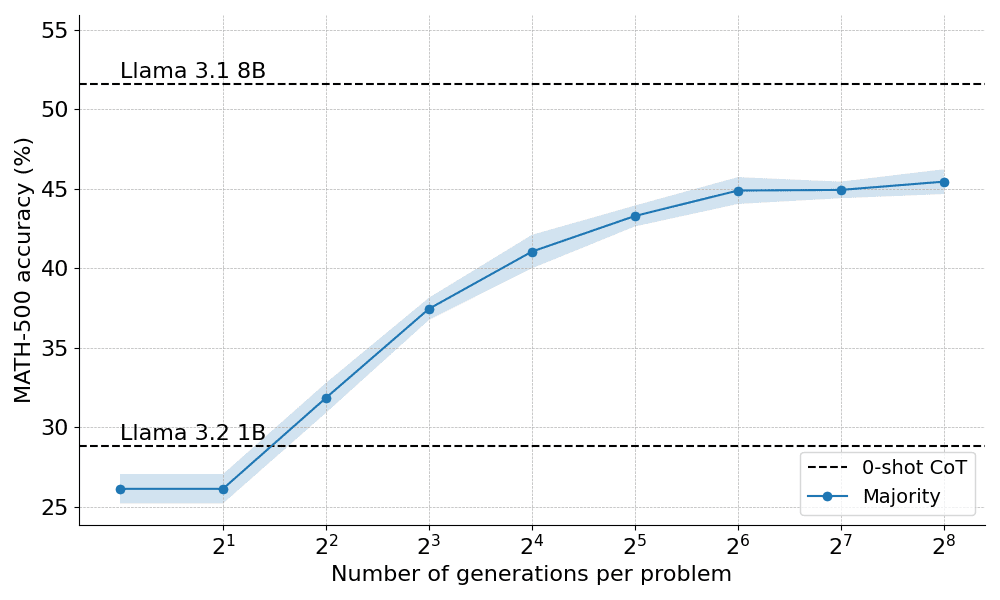
Результаты показывают, что мажоритарное голосование обеспечивает значительное улучшение по сравнению с жадным декодированием, но его преимущества начинают сходить на нет примерно после N=64 поколений. Это ограничение возникает потому, что мажоритарное голосование с трудом решает задачи, требующие тщательных рассуждений.
Исходя из ограничений мажоритарного голосования, давайте посмотрим, как мы можем использовать модель вознаграждения для повышения эффективности работы.
За гранью большинства: Лучшие из N
Best-of-N - это простое и эффективное расширение алгоритма голосования по большинству голосов, которое использует модель вознаграждения для определения наиболее разумного ответа. Существует два основных варианта метода:
Обычный Best-of-N: сгенерируйте N независимых ответов и выберите в качестве окончательного ответа тот, который имеет наибольшую награду RM. Это гарантирует, что будет выбран ответ с наибольшей уверенностью, но не учитывает согласованность между ответами.
Взвешенный Best-of-N: суммирует баллы всех одинаковых ответов и выбирает тот, который имеет наибольшую общую награду. Этот метод отдает предпочтение ответам высокого качества, увеличивая их оценку за счет повторных повторений. Математически ответы взвешиваются по a_i:
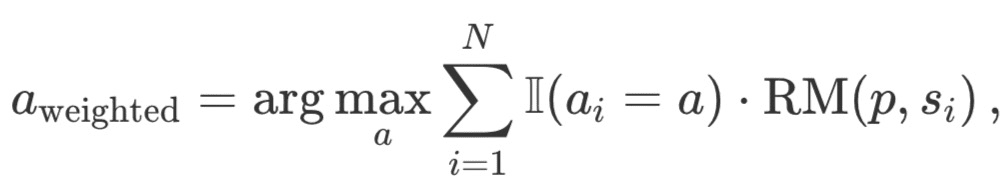
где RM (p,s_i) - оценка модели вознаграждения для i-го решения s_i задачи p.
Обычно для получения индивидуальных оценок на уровне решений используется модель вознаграждения за результат (Outcome Reward Model, ORM). Однако для корректного сравнения с другими стратегиями поиска та же PRM используется для оценки Best-of-N решений. Как показано на рисунке ниже, PRM генерирует кумулятивную последовательность оценок на уровне шагов для каждого решения, и поэтому для получения индивидуальных оценок на уровне решений шаги должны быть статистически (редуктивно) оценены:
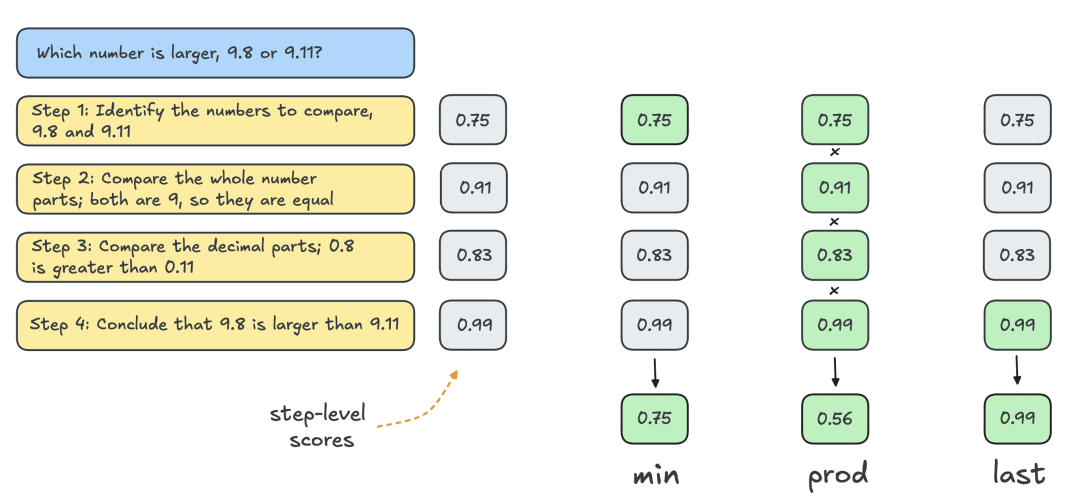
Ниже перечислены наиболее распространенные статуты:
- Min: Используйте наименьший результат из всех этапов.
- Prod: используйте произведение степенных дробей.
- Последний: Используйте итоговую оценку этого шага. Эта оценка содержит совокупную информацию со всех предыдущих шагов, что позволяет рассматривать PRM как ORM, способный оценивать частичные решения.
Ниже приведены результаты, полученные при использовании двух вариантов Best-of-N:
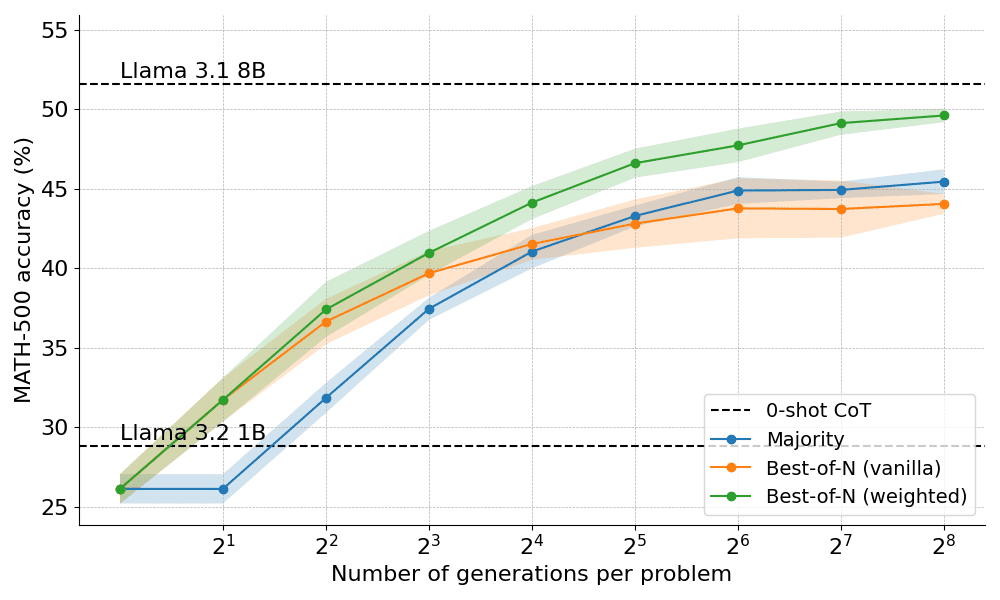
Результаты показывают явное преимущество: взвешенный Best-of-N постоянно превосходит обычный Best-of-N, особенно при больших бюджетах на генерацию. Его способность суммировать оценки одинаковых ответов гарантирует, что даже менее частые, но более качественные ответы будут эффективно приоритизированы.
Однако, несмотря на эти улучшения, он все еще не дотягивает до производительности, достигнутой моделью Llama 8B, и метод Best-of-N начинает стабилизироваться при N=256.
Можно ли расширить границы, постепенно контролируя процесс поиска?
Поиск кластеров с помощью PRM
Как метод структурированного поиска, кластерный поиск позволяет систематически исследовать пространство решений, что делает его мощным инструментом для улучшения результатов моделирования во время тестирования. При использовании в сочетании с PRM кластерный поиск может оптимизировать генерацию и оценку промежуточных шагов в решении задачи. Кластерный поиск работает следующим образом:
- Несколько решений-кандидатов генерируются итеративно, сохраняя фиксированное количество "кластеров" или активных путей N.
- На первой итерации берется N независимых шагов из LLM с температурой T, чтобы внести разнообразие в ответы. Эти шаги обычно определяются критерием остановки, например, завершением на новом ряду n или двойным новым рядом nn.
- Каждый шаг оценивается с помощью PRM, и N/M лучших шагов выбираются в качестве кандидатов для следующего раунда генерации. Здесь M обозначает "ширину кластера" для данного пути деятельности. Как и в случае с Best-of-N, "последний" статут используется для оценки частичных решений для каждой итерации.
- Расширьте шаги, выбранные на шаге (3), выбрав M последующих шагов в решении.
- Повторяйте шаги (3) и (4) до тех пор, пока не будет достигнута EOS жетон или превышает максимальную глубину поиска.
Позволяя PRM оценивать правильность промежуточных шагов, кластерный поиск может выявлять и приоритизировать перспективные пути на ранних этапах процесса. Эта стратегия пошаговой оценки особенно полезна для сложных задач рассуждения, таких как математика, поскольку проверка частичных решений может значительно улучшить конечный результат.
Детали реализации
В экспериментах HuggingFace следовал гиперпараметрам DeepMind и выполнял поиск кластеров следующим образом:
- Вычислите N кластеров при масштабировании до 4, 16, 64, 256
- Фиксированная ширина кластера M=4
- Отбор проб при температуре T=0,8
- До 40 итераций, т.е. дерево с максимальной глубиной 40 шагов
Как показано на рисунке ниже, результаты поражают: при бюджете времени тестирования N=4 кластерный поиск достигает той же точности, что и Best-of-N при N=16, т. е. в 4 раза повышает вычислительную эффективность! Более того, производительность кластерного поиска сопоставима с производительностью Llama 3.1 8B, требующей всего N=32 решения для каждой задачи. Средняя производительность аспирантов, изучающих математику, составляет около 40%, поэтому для модели 1B близкая к 55% является достаточно хорошей!
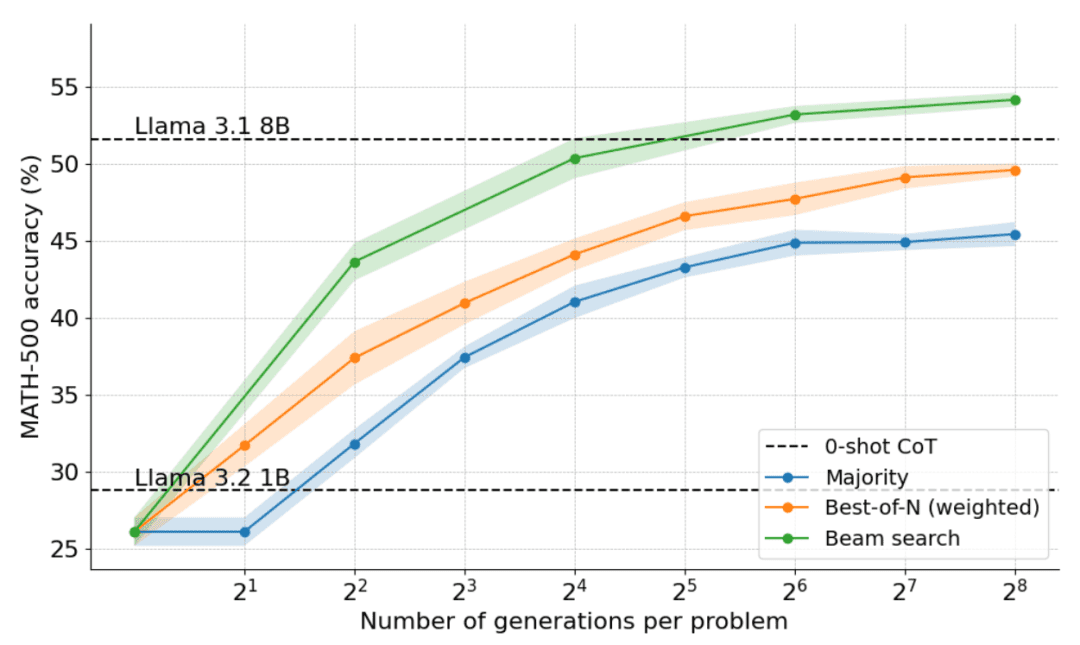
Какие проблемы лучше всего решать с помощью кластерного поиска
Хотя в целом очевидно, что кластерный поиск является лучшей стратегией поиска, чем Best-of-N или мажоритарное голосование, работа DeepMind показывает, что для каждой стратегии есть свои компромиссы, зависящие от сложности задачи и вычислительного бюджета на момент тестирования.
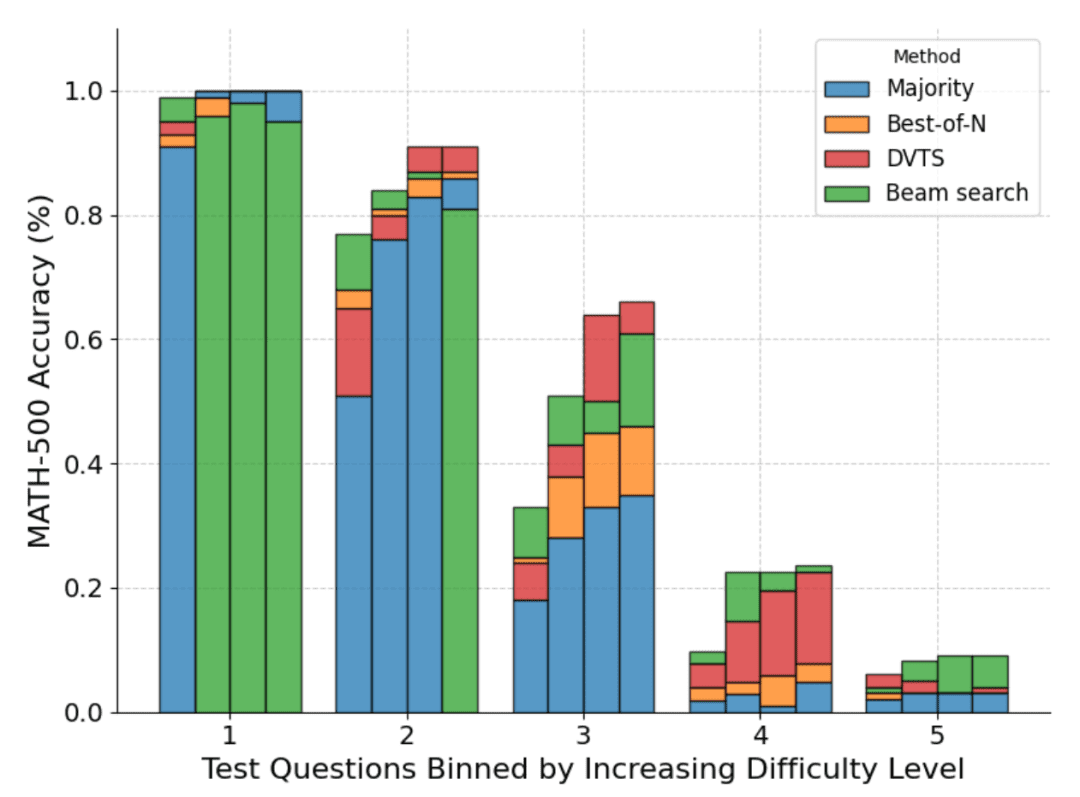
Чтобы понять, какие задачи лучше всего подходят для той или иной стратегии, DeepMind вычислила распределение предполагаемой сложности задач и разделила результаты на квинтили. Другими словами, каждая проблема была отнесена к одному из пяти уровней, где уровень 1 обозначал более легкие проблемы, а уровень 5 - самые сложные. Чтобы оценить сложность задачи, DeepMind сгенерировал 2048 решений-кандидатов для каждой задачи с помощью стандартной выборки, а затем предложил следующие эвристики:
- Oracle: Оцените количество баллов за проход@1 для каждого вопроса, используя основные метки фактов, и классифицируйте распределение баллов за проход@1, чтобы определить квинтили.
- Моделирование: квинтили определяются с помощью распределения средних баллов PRM для каждой задачи. Интуиция подсказывает, что более трудные вопросы будут иметь более низкие оценки.
На рисунке ниже показано распределение различных методов на основе оценки pass@1 и бюджета N=[4,16,64,256], рассчитанного для четырех тестов:
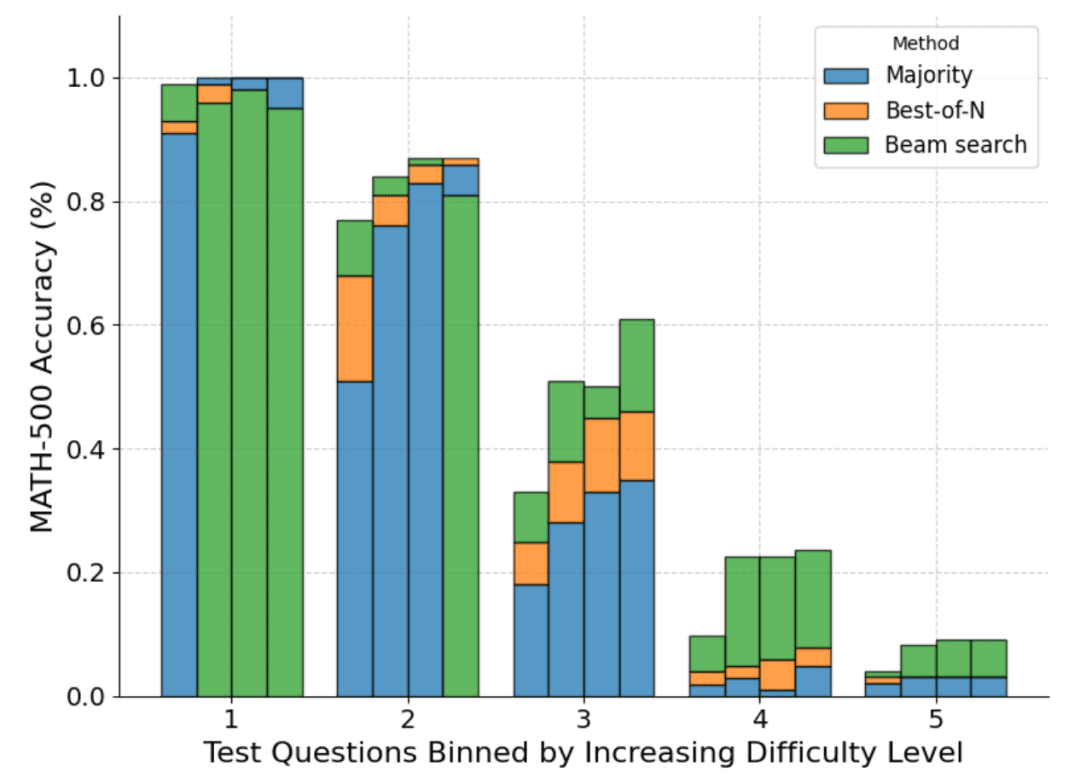
Как видно, каждый столбик представляет собой бюджет, рассчитанный на момент проведения теста, а относительная точность каждого метода показана внутри каждого столбика. Например, в четырех столбиках для уровня сложности 2:
Голосование по большинству голосов является наихудшим методом для всех вычислительных бюджетов, за исключением N=256 (кластерный поиск работает хуже всего).
Кластерный поиск лучше всего подходит для N=[4,16,64], а Best-of-N - для N=256.
Следует отметить, что кластерный поиск добился устойчивого прогресса в решении задач умеренной и сложной сложности (уровни 3-5), но он, как правило, работает хуже, чем Best-of-N (или даже мажоритарное голосование) в более простых задачах, особенно при больших вычислительных бюджетах.
Просматривая дерево результатов, полученных в результате кластерного поиска, специалисты HuggingFace поняли, что если за один шаг назначается высокая награда, то все дерево разрушается по этой траектории, что негативно сказывается на разнообразии. Это привело их к поиску расширения кластерного поиска, которое максимизирует разнообразие.
DVTS: Повышение производительности за счет разнообразия
Как видно из вышеизложенного, кластерный поиск обеспечивает более высокую производительность, чем Best-of-N, но при решении простых задач и больших вычислительных бюджетах на момент тестирования имеет тенденцию к снижению производительности.
Для решения этой проблемы компания HuggingFace разработала расширение под названием "Diversity Validator Tree Search" (DVTS), целью которого является максимизация разнообразия при большом количестве N.
DVTS работает аналогично кластерному поиску со следующими изменениями:
- Для заданных N и M исходное множество разбивается на N/M независимых поддеревьев.
- Для каждого поддерева выберите шаг с наивысшей оценкой PRM.
- Сгенерируйте M новых шагов из узла, выбранного на шаге (2), и выберите шаг с наивысшей оценкой PRM.
- Повторяйте шаг (3) до тех пор, пока не будет достигнут маркер EOS или максимальная глубина дерева.
На следующем графике показаны результаты применения DVTS к Llama 1B:
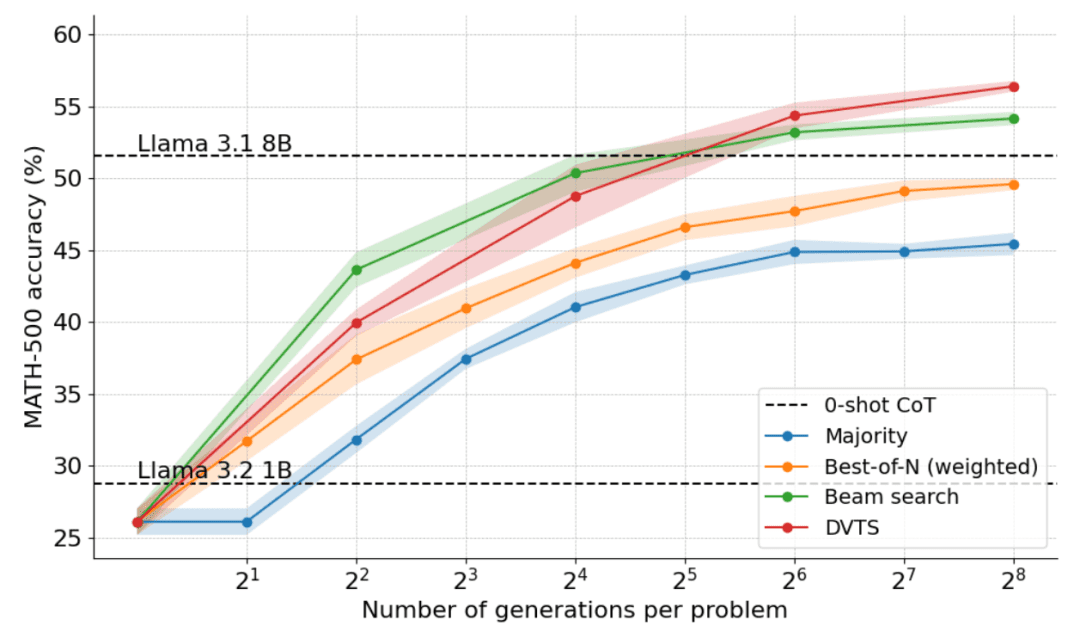
Видно, что DVTS дополняет кластерный поиск: при малых N кластерный поиск более эффективен для нахождения правильного решения, но при больших N в игру вступает разнообразие кандидатов DVTS, и можно добиться лучшей производительности.
Кроме того, в разбивке по сложности задачи, DVTS улучшает производительность простых/средних задач с большим N, в то время как кластерный поиск лучше всего работает с малым N.
вычислительно-оптимальное масштабирование (вычислительно-оптимальное масштабирование)
При большом разнообразии стратегий поиска возникает естественный вопрос: какая из них лучше? В статье DeepMind (доступна под названием Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters ) предлагается оптимальная с вычислительной точки зрения стратегия масштабирования, которая выбирает метод поиска и гиперпараметр θ для достижения оптимальной производительности при заданном вычислительном бюджете N : N : N:. параметр θ для достижения оптимальной производительности при заданном вычислительном бюджете N:
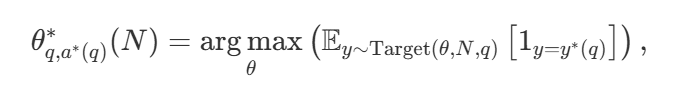
среди них 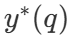 правильный ответ на вопрос q.
правильный ответ на вопрос q. 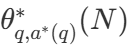 Вычисления по представлениям - оптимальная стратегия масштабирования. Поскольку вычислить
Вычисления по представлениям - оптимальная стратегия масштабирования. Поскольку вычислить 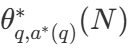 DeepMind предлагает аппроксимацию на основе сложности задачи, то есть распределение вычислительных ресурсов во время тестирования на основе того, какая стратегия поиска достигает наилучшей производительности при заданном уровне сложности.
DeepMind предлагает аппроксимацию на основе сложности задачи, то есть распределение вычислительных ресурсов во время тестирования на основе того, какая стратегия поиска достигает наилучшей производительности при заданном уровне сложности.
Например, для более простых задач и низких вычислительных бюджетов лучше использовать такие стратегии, как Best-of-N, а для более сложных задач лучше использовать поиск по множеству shu. На рисунке ниже показана кривая "вычисления-оптимизация"!
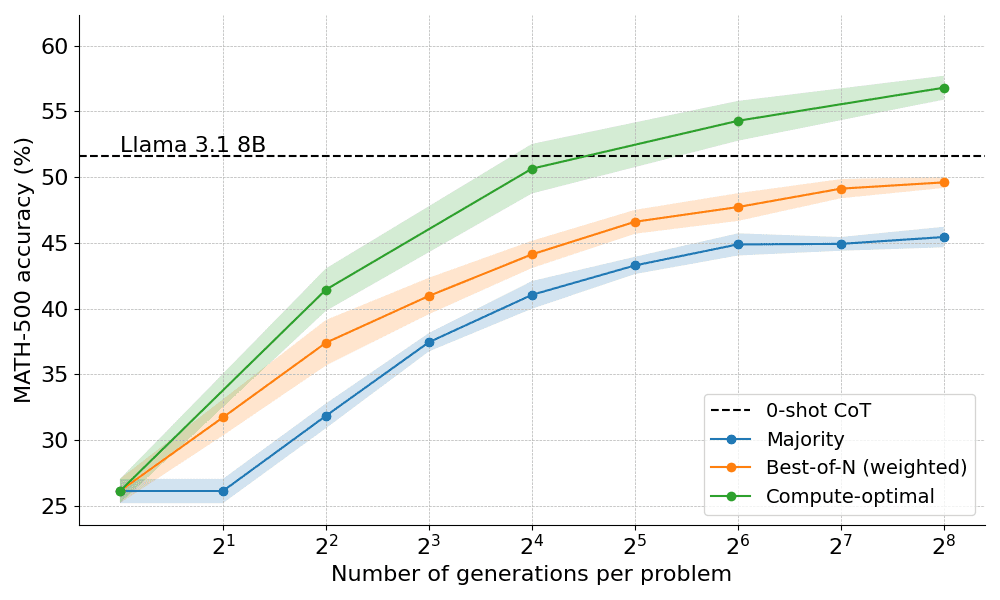
Расширение до более крупных моделей
В данной работе также исследуется распространение вычислительно-оптимального подхода на модель Llama 3.2 3B Instruct, чтобы увидеть, в какой момент PRM начинает ослабевать по сравнению с возможностями самой политики. Результаты показывают, что вычислительно-оптимальное расширение работает очень хорошо, причем модель 3B превосходит модель Llama 3.1 70B Instruct (которая в 22 раза больше первой!). .

Что дальше?
Исследование масштабирования вычислений в тестовое время раскрывает потенциал и проблемы использования подходов, основанных на поиске. Заглядывая в будущее, эта статья предлагает несколько интересных направлений:
- Сильные валидаторы: сильные валидаторы играют ключевую роль в улучшении производительности, и повышение надежности и универсальности валидаторов имеет решающее значение для развития этих подходов;
- Самооценка: конечной целью является достижение самооценки, т.е. модель может автономно проверять свои собственные результаты. Этот подход, по-видимому, используется в таких моделях, как o1, но на практике его все еще трудно достичь. В отличие от стандартной контролируемой тонкой настройки (SFT), самооценка требует более тонкой стратегии;
- (a) Интеграция мышления в процесс: включение явных промежуточных шагов или мышления в генеративный процесс может еще больше улучшить рассуждения и принятие решений. Включение структурированных рассуждений в процесс поиска позволяет повысить эффективность выполнения сложных задач;
- Поиск как инструмент генерации данных: метод также может выступать в качестве мощного процесса генерации данных для создания высококачественных обучающих наборов данных. Например, тонкая настройка такой модели, как Llama 1B, на основе правильных траекторий, полученных в результате поиска, может дать значительные преимущества. Этот подход, основанный на стратегии, похож на такие методы, как ReST или V-StaR, но с дополнительным преимуществом поиска, что дает перспективное направление для итеративного улучшения;
- Вызов большего количества PRM: Существует относительно небольшое количество PRM, что ограничивает их широкое применение. Разработка и распространение большего количества PRM для различных доменов - это ключевая область, в которую сообщество может внести значительный вклад.
© заявление об авторских правах
Авторское право на статью Круг обмена ИИ Пожалуйста, не воспроизводите без разрешения.
Похожие статьи




Нет комментариев...