TPO-LLM-WebUI: uma estrutura de IA em que você pode inserir perguntas para treinar um modelo em tempo real e gerar os resultados.
Introdução geral
O TPO-LLM-WebUI é um projeto inovador de código aberto da Airmomo no GitHub que permite a otimização em tempo real de modelos de idiomas grandes (LLMs) por meio de uma interface da Web intuitiva. Ele adota a estrutura TPO (Test-Time Prompt Optimization), dando adeus ao tedioso processo de ajuste fino tradicional e otimizando diretamente a saída do modelo sem treinamento. Depois que o usuário insere uma pergunta, o sistema usa modelos de recompensa e feedback iterativo para permitir que o modelo evolua dinamicamente durante o processo de raciocínio, tornando-o cada vez mais inteligente e melhorando a qualidade do resultado em até 50%. Seja para polir documentos técnicos ou gerar respostas de segurança, essa ferramenta leve e eficiente oferece suporte avançado para desenvolvedores e pesquisadores.


Lista de funções
- Evolução em tempo realOtimização do resultado por meio da fase de inferência: quanto mais for usado, mais atenderá às necessidades do usuário.
- Não é necessário ajuste finoNão atualizar os pesos do modelo e melhorar diretamente a qualidade da geração.
- Compatível com vários modelosSuporte para carregar diferentes modelos de base e de recompensa.
- Alinhamento dinâmico de preferênciasAjuste da produção com base no feedback de recompensa para se aproximar das expectativas humanas.
- Visualização de raciocínioDemonstrar o processo de iteração da otimização para facilitar a compreensão e a depuração.
- Leve e eficiente: A computação é de baixo custo e simples de implementar.
- Código aberto e flexívelCódigo-fonte: fornece código-fonte e oferece suporte ao desenvolvimento definido pelo usuário.
Usando a Ajuda
Processo de instalação
A implementação do TPO-LLM-WebUI requer algumas configurações básicas do ambiente. Abaixo estão as etapas detalhadas para ajudar os usuários a começar rapidamente.
1. preparação do ambiente
Certifique-se de que as seguintes ferramentas estejam instaladas:
- Python 3.10Ambiente operacional principal.
- GitCódigo do projeto: Usado para obter o código do projeto.
- GPU (recomendado)GPUs NVIDIA aceleram a inferência.
Crie um ambiente virtual:
Use a Condi:
conda create -n tpo python=3.10
conda activate tpo
ou as próprias ferramentas do Python:
python -m venv tpo
source tpo/bin/activate # Linux/Mac
tpo\Scripts\activate # Windows
Faça o download e instale as dependências:
git clone https://github.com/Airmomo/tpo-llm-webui.git
cd tpo-llm-webui
pip install -r requirements.txt
Instale o TextGrad:
O TPO depende do TextGrad, que requer instalação adicional:
cd textgrad-main
pip install -e .
cd ..
2. modelo de configuração
É necessário fazer o download manual do modelo básico e do modelo de bônus:
- modelo básicoComo
deepseek-ai/DeepSeek-R1-Distill-Qwen-32B(Abraçando o rosto) - modelagem de incentivosComo
sfairXC/FsfairX-LLaMA3-RM-v0.1(Abraçando o rosto)
Coloque o modelo no diretório especificado (por exemplo/model/HuggingFace/), e emconfig.yamlDefina o caminho no campo
3. inicie o serviço vLLM
fazer uso de vLLM Modelo básico de hospedagem. Tome como exemplo 2 GPUs:
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--dtype auto
--api-key token-abc123
--tensor-parallel-size 2
--max-model-len 59968
--port 8000
Depois que o serviço estiver em execução, ouça a mensagem http://127.0.0.1:8000.
4. executando a WebUI
Inicie a interface da Web em um novo terminal:
python gradio_app.py
acesso ao navegador http://127.0.0.1:7860A seguir, apresentamos uma lista dos produtos mais populares e mais procurados disponíveis no mercado.
Funções principais
Função 1: Inicialização do modelo
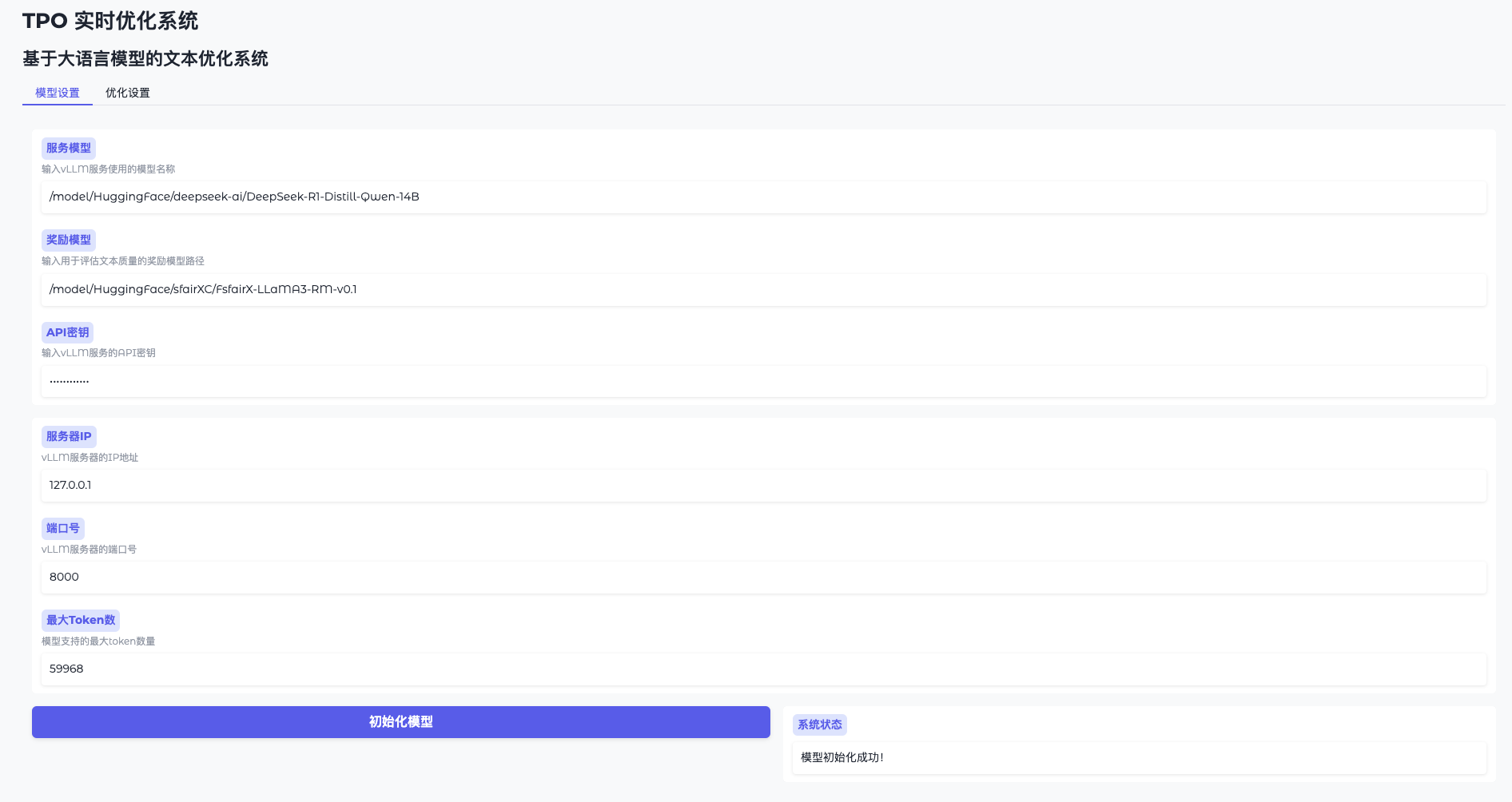
- Abrir configurações do modelo
Vá para a WebUI e clique em "Model Settings" (Configurações do modelo). - Conectando-se ao vLLM
Digite o endereço (por exemplohttp://127.0.0.1:8000) e a chave (token-abc123). - Carregando o modelo de recompensa
Especifique o caminho (por exemplo/model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1Clique em "Initialise" e aguarde de 1 a 2 minutos. - Confirmação de prontidão
A interface exibe a mensagem "Model ready" (Modelo pronto) e você pode continuar.
Função 2: Otimizar a produção em tempo real
- Alternar página de otimização
Vá para "Optimise Settings" (Otimizar configurações). - Problemas de entrada
Insira conteúdo como "Retoque este documento técnico". - Otimização operacional
Clique em "Start Optimisation" (Iniciar otimização) e o sistema gerará vários resultados candidatos e os aprimorará iterativamente. - Confira o processo evolutivo
A página de resultados exibe o resultado inicial e otimizado, com um aumento gradual da qualidade.
Recurso 3: Otimização do modo de script
Se não estiver usando a WebUI, você pode executar um script:
python run.py
--data_path data/sample.json
--ip 0.0.0.1
--port 8000
--server_model /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--reward_model /model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1
--tpo_mode tpo
--max_iterations 2
--sample_size 5
Os resultados da otimização são salvos em logs/ Pasta.
Descrição detalhada dos recursos especiais
Diga adeus ao ajuste fino, evolua em tempo real
- procedimento::
- Digite a pergunta e o sistema gera a resposta inicial.
- Recompense a avaliação do modelo e o feedback para orientar a próxima iteração.
- Após várias iterações, o resultado se torna "mais inteligente" e a qualidade melhora significativamente.
- de pontaEconomia de tempo e aritmética com a otimização a qualquer momento, sem treinamento.
Quanto mais você o usa, mais inteligente ele fica.
- procedimento::
- Use o mesmo modelo várias vezes com entradas diferentes para problemas diferentes.
- O sistema acumula experiência com base em cada feedback e o resultado é mais bem adaptado às necessidades.
- de pontaAprendizagem: aprende dinamicamente as preferências do usuário para obter melhores resultados a longo prazo.
advertência
- Requisitos de hardwareRecomendado 16 GB de memória de vídeo ou mais, várias GPUs precisam garantir que os recursos estejam livres e disponíveis.
export CUDA_VISIBLE_DEVICES=2,3Designação. - Solução de problemasQuando a memória de vídeo transbordar, diminua a
sample_sizeou verificar a ocupação da GPU. - Suporte à comunidadeConsulte o LEIAME ou os problemas do GitHub para obter ajuda.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...