
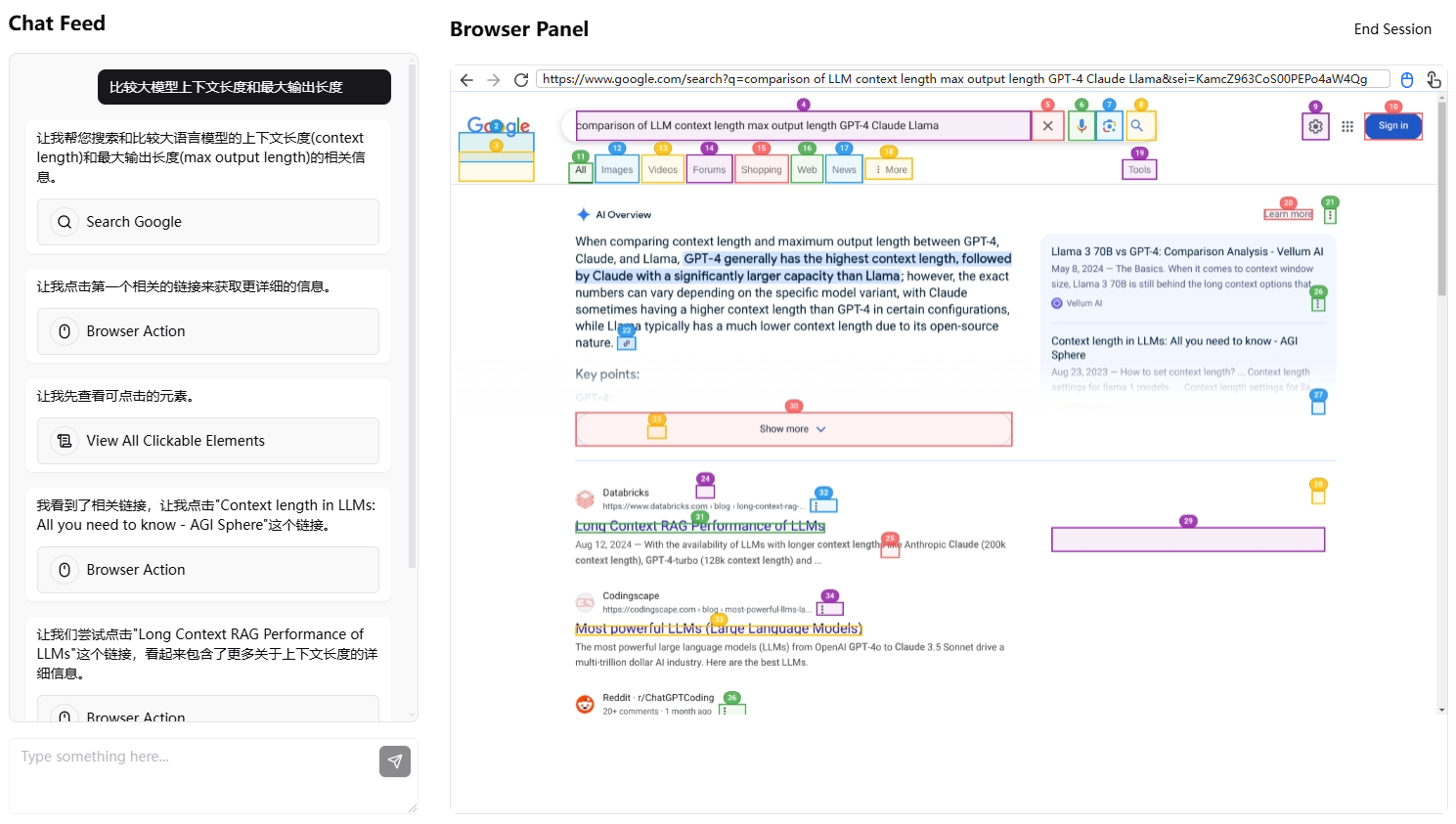
OneFileLLM: integração de várias fontes de dados em um único arquivo de texto
Introdução geral
O OneFileLLM é uma ferramenta de linha de comando de código aberto projetada para consolidar várias fontes de dados em um único arquivo de texto para facilitar a entrada em modelos de linguagem grande (LLMs). Ela é compatível com o processamento de repositórios do GitHub, artigos do ArXiv, transcrições de vídeos do YouTube, conteúdo da Web, artigos do Sci-Hub e arquivos locais, gerando automaticamente texto estruturado e copiando-o para a área de transferência. O desenvolvedor Jim McMillan projetou a ferramenta para simplificar a criação de prompts LLM e reduzir a tediosa tarefa de organizar manualmente os dados. Desenvolvida em Python, a ferramenta é compatível com vários formatos de arquivo, pré-processamento de texto e agrupamento de XML, o que a torna adequada para desenvolvedores, pesquisadores e criadores de conteúdo. É fácil de instalar, flexível para configurar e pode ser operada a partir da linha de comando ou por meio de uma interface da Web.

Lista de funções
- Detecção automática de tipos de entrada (por exemplo, repositórios do GitHub, links do YouTube, artigos do ArXiv, arquivos locais etc.).
- Suporte ao processamento de repositórios do GitHub, Pull Requests e problemas em um único texto.
- Extraia e converta o conteúdo em PDF de artigos do ArXiv e do Sci-Hub em texto.
- Obter transcrições de vídeos do YouTube.
- Rastreamento de conteúdo da Web, suporte para profundidade especificada de links de rastreamento.
- Manipula uma ampla variedade de formatos de arquivo, incluindo
.pye.ipynbe.txte.mde.pdfe.csvetc. - Fornece pré-processamento de texto, como remoção de palavras de parada, pontuação e conversão para letras minúsculas.
- Suporte para exclusão de arquivos e diretórios, filtragem de arquivos gerados automaticamente (por exemplo
*.pb.go) ou catálogo de testes. - Informe o número de tokens para texto compactado e não compactado para otimizar o gerenciamento de contexto do LLM.
- O texto de saída é encapsulado no formato XML para aumentar a eficiência do processamento do LLM.
- Copia automaticamente o texto não compactado para a área de transferência para facilitar a colagem na plataforma LLM.
- Fornece uma interface da Web do Flask para simplificar a entrada de URL ou caminho.
Usando a Ajuda
Processo de instalação
O OneFileLLM requer um ambiente Python e dependências relacionadas. Veja a seguir as etapas detalhadas de instalação:
- armazém de clones
Execute o seguinte comando em um terminal para clonar o repositório OneFileLLM:git clone https://github.com/jimmc414/onefilellm.git cd onefilellm - Criação de um ambiente virtual(Recomendado)
Para evitar conflitos de dependência, é recomendável criar um ambiente virtual:python -m venv .venv source .venv/bin/activate # Windows 使用 .venv\Scripts\activate - Instalação de dependências
montagemrequirements.txtAs dependências listadas nopip install -U -r requirements.txtAs dependências incluem
PyPDF2(Processamento de PDF),BeautifulSoup(rastreador da Web),tiktoken(contagem de tokens),pyperclip(Operação da área de transferência),youtube-transcript-api(transcrição do YouTube), etc. - Configuração de tokens de acesso ao GitHub(Opcional)
Para acessar repositórios privados do GitHub, você precisa configurar um token de acesso pessoal:- Faça login no GitHub e vá para Configurações > Configurações de desenvolvedor > Token de acesso pessoal.
- Para gerar um novo token, selecione
repo(armazém privado) oupublic_repo(Open Warehouse) Competência. - Defina o token como uma variável de ambiente:
export GITHUB_TOKEN=<your-token> # Windows 使用 set GITHUB_TOKEN=<your-token>
- Verificar a instalação
Execute o seguinte comando para verificar se a instalação foi bem-sucedida:python onefilellm.py --helpSe uma mensagem de ajuda for exibida, a instalação está correta.
modo de execução
O OneFileLLM é compatível com a linha de comando e com a interface da Web:
- modo de linha de comando
Execute o script principal e insira manualmente o URL ou o caminho:python onefilellm.pyou especifique o URL/caminho diretamente na linha de comando:
python onefilellm.py https://github.com/jimmc414/onefilellm - Modo de interface da Web
Execute a interface da Web do Flask:python onefilellm.py --webAbra seu navegador e acesse
http://localhost:5000Insira a URL ou o caminho e clique em "Process" para obter o resultado.
Funções principais
No centro do OneFileLLM está a integração de várias fontes de dados em um único texto, que é exibido como uncompressed_output.txt(não compactado),compressed_output.txt(compactado) e processed_urls.txt(rastreamento de uma lista de URLs). Veja a seguir como usar as principais funções:
- Processamento de repositórios do GitHub
Digite o URL do repositório (por exemplohttps://github.com/jimmc414/onefilellm), a ferramenta obtém recursivamente os tipos de arquivos compatíveis (por exemplo.pye.md), consolidados em um único texto.
Exemplo:python onefilellm.py Enter URL or path: https://github.com/jimmc414/onefilellmO arquivo de saída contém o conteúdo do arquivo de repositório no seguinte formato de wrapper XML:
<source type="github_repository"> <content> [文件内容] </content> </source>O texto é copiado automaticamente para a área de transferência.
- Como lidar com problemas ou solicitações pull do GitHub
Insira um pull request (por exemplo.https://github.com/dear-github/dear-github/pull/102) ou o URL do problema (por exemplo.https://github.com/isaacs/github/issues/1191), a ferramenta extrai detalhes de diferenças, comentários e todo o conteúdo do repositório.
O resultado da amostra inclui alterações de código, comentários e documentação relacionada encapsulada como:<source type="github_pull_request"> <content> [差异详情和评论] </content> </source> - Extrair artigos do ArXiv ou do Sci-Hub
Digite o URL do ArXiv (por exemplohttps://arxiv.org/abs/2401.14295) ou Sci-Hub DOI/PMID (por exemplo.10.1053/j.ajkd.2017.08.002talvez29203127), a ferramenta converte PDF em texto.
Exemplo:Enter URL or path: https://arxiv.org/abs/2401.14295A saída é o texto em XML do documento:
<source type="arxiv_paper"> <content> [论文内容] </content> </source> - Obtenha a transcrição do YouTube
Digite o URL do vídeo do YouTube (por exemplohttps://www.youtube.com/watch?v=KZ_NlnmPQYk), ferramenta para extrair texto transcrito.
Exemplo:Enter URL or path: https://www.youtube.com/watch?v=KZ_NlnmPQYkO resultado é:
<source type="youtube_transcript"> <content> [转录内容] </content> </source> - rastreador da web
Digite o URL da página da Web (por exemplohttps://llm.datasette.io/en/stable/), a ferramenta rastreia a página e especifica links profundos (padrão)max_depth=2).
Exemplo:Enter URL or path: https://llm.datasette.io/en/stable/O resultado é um texto segmentado da Web, encapsulado como:
<source type="web_documentation"> <content> [网页内容] </content> </source> - Manipulação de arquivos ou diretórios locais
Digite o caminho do arquivo local (por exemploC:\documents\report.pdf) ou catálogo (por exemploC:\projects\research), a ferramenta extrai o conteúdo ou integra os tipos de arquivos compatíveis do diretório.
Exemplo:Enter URL or path: C:\projects\researchA saída é o conteúdo do catálogo em formato XML.
Operação da função em destaque
- Encapsulamento de saída XML
Todos os resultados estão no formato XML, que fornece uma estrutura clara e melhora a eficiência do processamento do LLM. O formato é o seguinte:<source type="[source_type]"> <content> [内容] </content> </source>Entre eles
source_typeinclusive por meio degithub_repositoryearxiv_paperetc. - Exclusão de arquivos e diretórios
Suporte para exclusão de arquivos específicos (por exemplo*.pb.go) e catálogos (por exemplotests) Modificaçãoonefilellm.pyacertou em cheioexcluded_patternsresponder cantandoEXCLUDED_DIRSLista:excluded_patterns = ['*.pb.go', '*_test.go'] EXCLUDED_DIRS = ['tests', 'mocks']Isso reduz o conteúdo estranho e otimiza o uso de tokens.
- contagem de tokens
fazer uso detiktokenCalcula o número de tokens para texto compactado e não compactado, exibido no console:Uncompressed token count: 1234 Compressed token count: 567Ajuda o usuário a garantir que o texto caiba na janela de contexto do LLM.
- Pré-processamento de texto
A ferramenta remove automaticamente as palavras de parada e a pontuação, converte para letras minúsculas e gera uma saída compactada. Os usuários podem modificarpreprocess_textpersonaliza a lógica de processamento. - Integração da área de transferência
A saída não compactada é automaticamente copiada para a área de transferência e colada diretamente nas plataformas LLM (por exemplo, ChatGPT, Claude). - interface da web
A interface do Flask simplifica as operações, pois o usuário insere um URL ou caminho e faz o download do arquivo de saída ou copia o texto. Adequado para usuários não técnicos.
Configuração personalizada
- Tipo de documento
modificaçõesallowed_extensionsadicionando ou removendo tipos de arquivos suportados:allowed_extensions = ['.py', '.txt', '.md', '.ipynb', '.csv'] - Profundidade de rastreamento da Web
modificaçõesmax_deptho valor padrão é 2:max_depth = 2 - Nome de domínio Sci-Hub
Se o nome de domínio do Sci-Hub não estiver disponível, altere oonefilellm.pyO URL do Sci-Hub no campo
advertência
- Garanta uma conexão estável com a Internet, pois a transcrição do YouTube e o acesso ao Sci-Hub dependem de APIs externas.
- Repositórios ou páginas da Web grandes podem gerar uma saída maior; recomenda-se verificar a contagem de tokens e ajustar as regras de exclusão.
- O acesso ao Sci-Hub pode exigir uma alteração de domínio devido a restrições regionais.
- Alguns formatos de arquivo (como PDF criptografado) podem não ser processados corretamente.
cenário do aplicativo
- Revisão do código
Os desenvolvedores inserem repositórios do GitHub ou URLs de solicitações pull, geram texto com código e comentários e inserem LLMs para analisar a qualidade do código ou sugestões de otimização. - Resumo da tese
Os pesquisadores inserem o URL de um artigo do ArXiv ou do Sci-Hub, extraem o texto e inserem o LLM para gerar um resumo ou responder a uma pergunta de pesquisa. - Agrupamento de conteúdo de vídeo
Os criadores de conteúdo inserem URLs de vídeos do YouTube para obter texto transcrito, inserem LLMs para extrair pontos-chave ou gerar scripts. - Integração de documentos
Os redatores técnicos inserem caminhos para páginas da Web ou diretórios locais, integram o conteúdo de documentos e inserem LLMs para reescrever ou gerar relatórios.
QA
- Quais formatos de arquivo são compatíveis com o OneFileLLM?
apoiar algo.pye.ipynbe.txte.mde.pdfe.csvetc., podem ser modificados modificando oallowed_extensionsPersonalização. - Como faço para acessar repositórios privados do GitHub?
Definir o token de acesso pessoal do GitHub como uma variável de ambienteGITHUB_TOKENexigirrepoPermissões. - Como reduzir o tamanho do texto de saída?
modificaçõesexcluded_patternsresponder cantandoEXCLUDED_DIRSExclusão de arquivos estranhos, ajuste demax_depthLimite a profundidade de rastreamento da Web. - Quais são as vantagens da saída XML?
O XML é claramente estruturado, rotulando a origem e o tipo de conteúdo e melhorando a capacidade do LLM de entender e processar informações complexas. - O que devo fazer se não conseguir baixar meu artigo do Sci-Hub?
Verifique a conexão de rede para ter certeza de que o DOI/PMID está correto ou atualize oonefilellm.pyO nome de domínio do Sci-Hub no
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...