
DeepSeek prático: construção do gráfico de conhecimento em três etapas - extração única, fusão de várias partes, geração de tópicos

Pergunta: Os gráficos de conhecimento são importantes, o modelo de linguagem DeepSeek está em alta, ele pode ser usado para criar gráficos de conhecimento rapidamente? Quero experimentar. DeepSeek do real para ver como ele se sai na extração de informações, na integração do conhecimento e na criação de gráficos a partir do nada.
Métodos: Realizei três experimentos para testar os recursos de criação de gráficos de conhecimento do DeepSeek:
- Mapeamento de construção de artigo único: Forneça um artigo ao DeepSeek e veja se ele consegue obter as informações com precisão e criar um gráfico.
- Mapeamento de fusão de vários artigos: Dê ao DeepSeek vários artigos para ver se ele pode adicionar novos conhecimentos a um gráfico existente.
- Mapeamento de geração de temas: Basta informar ao DeepSeek o tópico do atlas, não o artigo, e ver se ele consegue criar um atlas por conta própria.
Resultados: As experiências comprovam que o DeepSeek cria e funde bem os gráficos de conhecimento, mas ainda há espaço para melhorias.
Aqui está o procedimento exato e os resultados do experimento, que deixarei claro em termos mais simples.
I. Extração de conhecimento de um único artigo para criar um mapa
Objetivo: Testar a capacidade do DeepSeek de extrair conhecimento de um artigo e criar um gráfico de conhecimento.
Processo: Encontrei um artigo sobre bancos de dados gráficos NebulaGraph e pedi ao DeepSeek que lesse o artigo, extraísse as principais informações e, em seguida, gerasse o código do banco de dados NebulaGraph (nGQL) para criar um gráfico de conhecimento.
Instruções: "Você pode me ajudar a gerar um gráfico de conhecimento? Eu lhe darei o artigo, você extrairá as principais informações e criará o gráfico de conhecimento com o código nGQL."
Operação: Copie e cole o conteúdo do artigo diretamente no DeepSeek.
O código nGQL gerado pelo DeepSeek:
# Schema 定义(TAG 类型)
CREATE TAG IF NOT EXISTS product (
name STRING,
description STRING
);
CREATE TAG IF NOT EXISTS company (
name STRING
);
CREATE TAG IF NOT EXISTS feature (
name STRING
);
CREATE TAG IF NOT EXISTS tool (
name STRING
);
CREATE TAG IF NOT EXISTS scenario (
name STRING
);
CREATE TAG IF NOT EXISTS language (
name STRING
);
CREATE TAG IF NOT EXISTS auth_service (
name STRING
);
CREATE TAG IF NOT EXISTS ecosystem (
name STRING
);
# Schema 定义(EDGE 类型)
CREATE EDGE IF NOT EXISTS has_feature ();
CREATE EDGE IF NOT EXISTS used_by ();
CREATE EDGE IF NOT EXISTS provides_tool ();
CREATE EDGE IF NOT EXISTS supports_language ();
CREATE EDGE IF NOT EXISTS applicable_scenario ();
CREATE EDGE IF NOT EXISTS compatible_with ();
CREATE EDGE IF NOT EXISTS supports_auth ();
CREATE EDGE IF NOT EXISTS integrates_with ();
# 数据插入 - 核心产品
INSERT VERTEX product(name, description) VALUES
"NebulaGraph": ("NebulaGraph", "开源的分布式图数据库,支持千亿点万亿边数据集");
# 数据插入 - 产品特性
INSERT VERTEX feature(name) VALUES
"high_performance": ("高性能"),
"open_source": ("开源"),
"scalability": ("易扩展"),
"flexible_modeling": ("灵活数据建模"),
"read_write_balance": ("读写平衡"),
"compatibility": ("查询语言兼容性");
/* ... 此处省略 n多数据 ... */
Resultados: O código do DeepSeek é bom, a sintaxe está correta e é eficiente, pois combina vários dados em uma única instrução. O código é colocado no NebulaGraph para ser executado, e o gráfico tem a seguinte aparência:
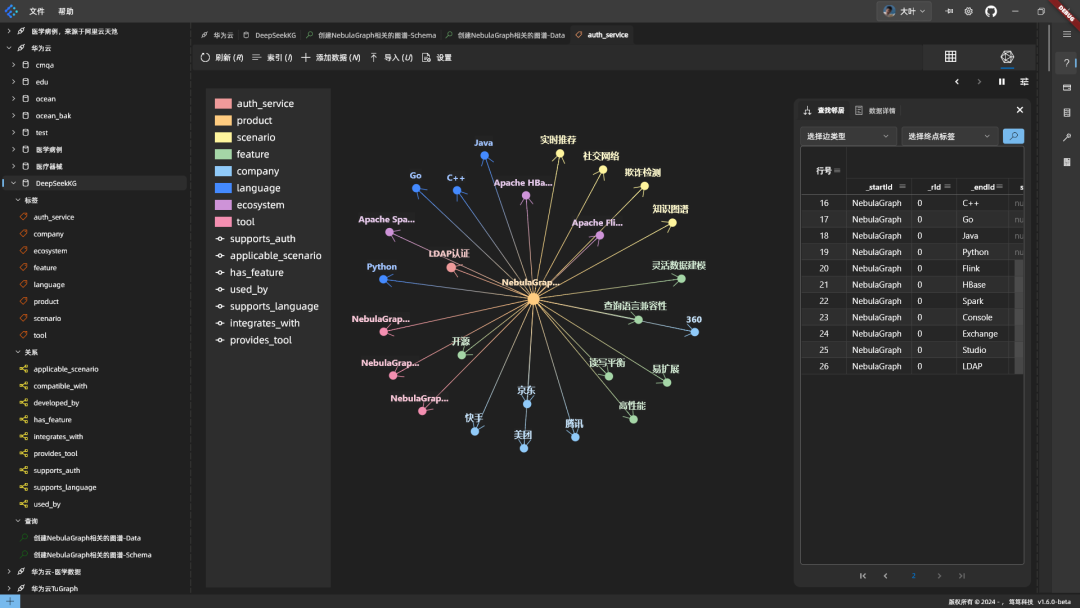
O gráfico é centralizado no NebulaGraph e mostra informações relevantes.
II. integração do conhecimento em vários artigos
Objetivo: Testar a capacidade do DeepSeek de fundir o conhecimento de vários artigos para ampliar um gráfico existente.
Processo: Primeiro, crie o gráfico com um artigo e, em seguida, forneça ao DeepSeek mais artigos sobre o NebulaGraph (da enciclopédia do Baidu) para mesclar o novo conhecimento no gráfico existente.
Instruções: "A seguir, outro artigo para você. Tente mesclar o mapeamento com a estrutura da tabela atual. Para alterar a estrutura da tabela, use o comando ALTER."
Operação: Os resumos das entradas do NebulaGraph e da 360 Encyclopedia foram fornecidos ao DeepSeek, respectivamente.
O código nGQL gerado pelo DeepSeek (léxico NebulaGraph):
# 结构变更 1:为 product 标签增加版本和时间属性
ALTER TAG product ADD (
license STRING,
current_version STRING,
release_date STRING,
last_updated STRING
);
# 结构变更 2:新增开发关系类型
CREATE EDGE IF NOT EXISTS developed_by();
# 数据更新 - 补充产品属性
INSERT VERTEX product(name, description, license, current_version, release_date, last_updated)
VALUES
"NebulaGraph": ("NebulaGraph", "分布式图数据库", "Apache 2.0", "v3.3.0", "2019-05-15", "2022-11-14");
# 新增开发公司(复用 company 标签)
INSERT VERTEX company(name)
VALUES
"Yueshu": ("杭州悦数科技有限公司");
# 新增特性(复用 feature 标签)
INSERT VERTEX feature(name)
VALUES
"acl_mechanism": ("ACL 机制"),
"linear_scaling": ("线性扩容"),
"data_recovery": ("数据恢复"),
"htap": ("HTAP 混合负载"),
"nGQL_language": ("nGQL 查询语言");
# 关系建立(复用已有关系类型)
INSERT EDGE has_feature()
VALUES
"NebulaGraph"->"acl_mechanism":(),
"NebulaGraph"->"linear_scaling":(),
"NebulaGraph"->"data_recovery":(),
"NebulaGraph"->"htap":(),
"NebulaGraph"->"nGQL_language":();
# 新增开发关系
INSERT EDGE developed_by()
VALUES
"NebulaGraph"->"Yueshu":();
O código nGQL gerado pelo DeepSeek (360 palavras):
# 结构变更 1:为 company 标签增加创始人、成立时间和收入属性
ALTER TAG company ADD (founder STRING, founded_date STRING, revenue DOUBLE);
# 结构变更 2:新增事件类型 TAG
CREATE TAG IF NOT EXISTS event (
type STRING,
date STRING,
amount DOUBLE,
details STRING
);
# 数据更新:补充 360 公司信息
INSERT VERTEX company(name, founder, founded_date, revenue)
VALUES
"360": ("奇虎360", "周鸿祎", "2005-09", 116.15);
# 数据插入:产品生态(复用 product 标签)
INSERT VERTEX product(name)
VALUES
"360_Security_Guard": ("360安全卫士"),
"360_Browser": ("360安全浏览器"),
"360_Cloud": ("360安全云");
# 数据插入:重大事件(使用新增 event 标签)
INSERT VERTEX event(type, date, amount, details)
VALUES
"acquisition_360.com": ("域名收购", "2015-02-04", 1700.0, "1.1亿人民币收购 360.com"),
"privatization": ("私有化", "2015-12", 9300.0, "93 亿美元私有化交易");
# 关系建立:复用 developed_by 边连接产品
Resultados: O DeepSeek pode modificar a estrutura da tabela com base no novo artigo (por exemplo, fornecendo produto responder cantando empresa tabela mais campos) e também adicionou um novo tipo de relacionamento. Ele faz isso conforme necessário com a função ALTER para alterar a estrutura da tabela. O pequeno problema é que o comentário usa o comando --O nGQL não é reconhecido, altere-o manualmente. # Na linha.
O código é colocado no banco de dados para execução, e o mapeamento fundido funciona:
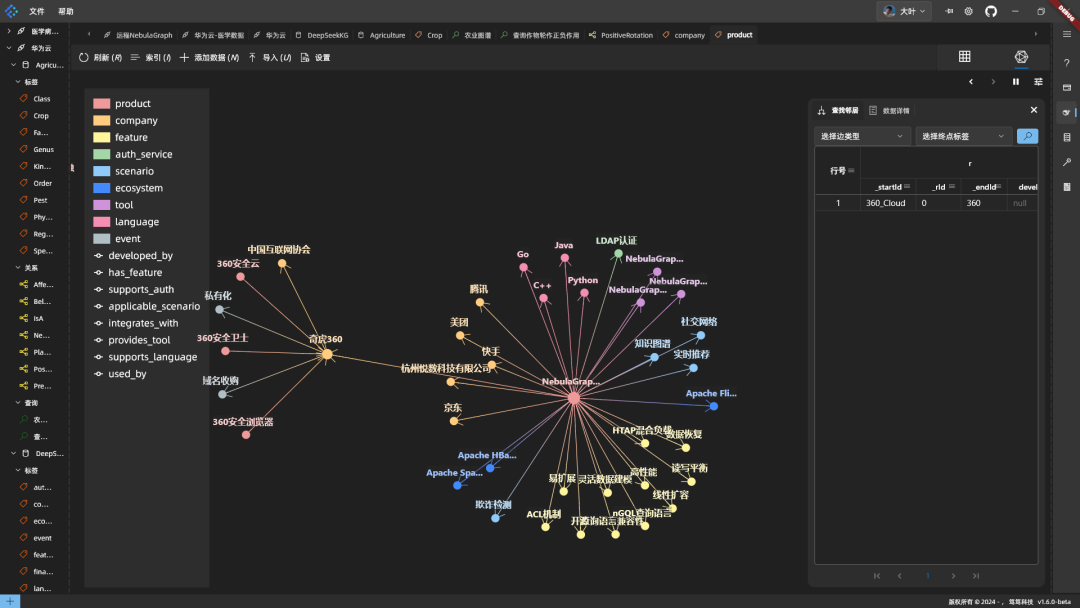
Resumo: O DeepSeek é bom para criar gráficos e fundir conhecimentos. No entanto, o servidor às vezes é lento e o NebulaGraph altera o esquema de forma assíncrona e demora um pouco para entrar em vigor.
III. geração de temas: mapeamento agrícola a partir do nada
Objetivo: Teste da capacidade do DeepSeek de gerar gráficos de conhecimento com base em tópicos sem artigos.
Processo: Crie um novo diálogo e deixe o DeepSeek gerar o código de mapeamento diretamente sobre o tópico "Agricultura". Nenhum artigo é fornecido, é um "free-for-all".
Instruções: "Quero criar um gráfico de conhecimento agrícola. Use o banco de dados NebulaGraph e gere um script nGQL. Os nomes das tabelas são grandes, os nomes dos atributos são pequenos. Os nomes dos esquemas são envolvidos por `` para evitar conflitos. Gere pelo menos 3.000 nós."
Código nGQL gerado pelo DeepSeek (parcial):
# ======================================= #
# 创建图空间
# ======================================= #
CREATE SPACE `Agriculture` (vid_type = FIXED_STRING(32));
USE `Agriculture`;
# ======================================= #
# 定义标签 Schema(大驼峰命名)
# ======================================= #
CREATE TAG IF NOT EXISTS `Crop` (
`cropId` int,
`cropName` string,
`growthPeriod` int,
`suitableTemp` string,
`yieldPerMu` float
);
# ======================================= #
# 此处省略好多脚本
# ======================================= #
Problemas e melhorias:
- Limite de contagem de nós: Comecei com 3.000 nós, o DeepSeek se recusou e deu o Python para importar o código CSV. Eu não queria usar o Python, então reduzi o número de nós.
- A questão da anotação surge novamente: Os comentários do código são novamente --Gostaria de apontar o problema novamente.
Instruções de aprimoramento: "Use o # para comentários, sem código Python, 3.000 nós são demais. Apenas me dê o script ngql para 50 nós."
Diálogo e instruções de acompanhamento: Para refinar o mapa, continuei a conversar com o DeepSeek, pedindo que ele adicionasse dados, fortalecesse as associações, organizasse o mapa por classificação (filo, ordem, família, gênero e espécie) e também pedisse que gerasse dados de rotação de culturas.
Por exemplo, minhas instruções:
- "Dados suplementares para vínculos de dados mais sólidos."
- "Faça um atlas com essas classificações [de filos, ordens, famílias, gêneros e espécies]."
- "Identifique contraindicações e ganhe culturas na rotação de culturas existentes."
- "Combinação de dados mapeados de tecidos de culturas para fornecer scripts nGQL no formato anterior"
Interlúdio experimental: DeepSeek, uma vez. INSERIR usa a sintaxe Cypher, que não é compatível com o nGQL, e isso foi apontado e alterado.
Instruções: "Essa instrução de inserção não é a sintaxe nGQL. Altere-a para que a DDL venha primeiro e a DML venha depois."
Volume final de dados: Após algumas rodadas de diálogo, a quantidade de dados é mostrada:

Efeitos de mapeamento: Expanda alguns nós aleatórios para ver:
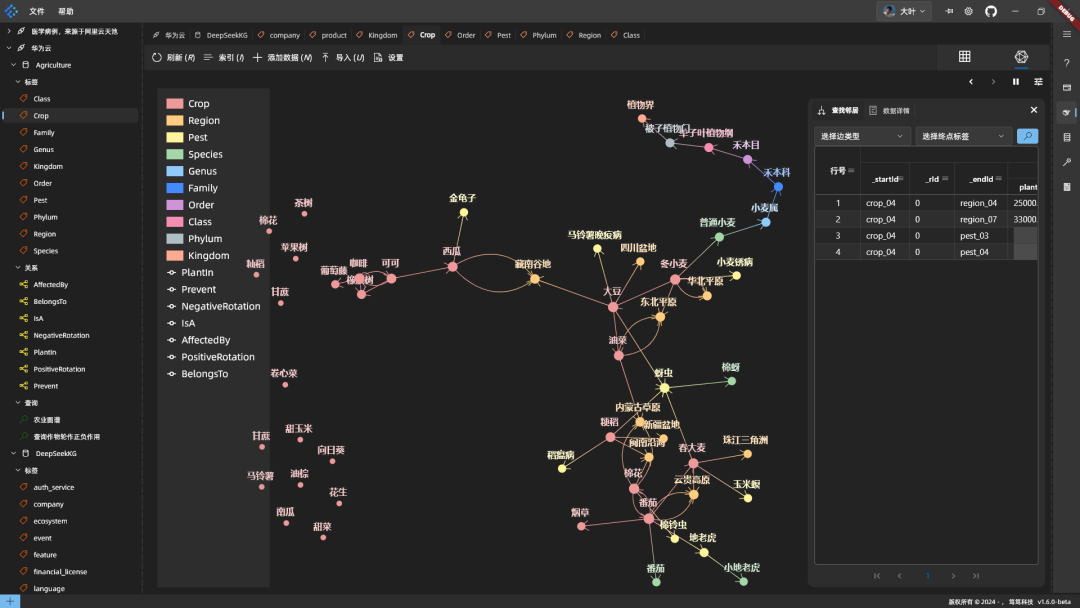
Exemplos de combinações de espécies rotativas que aumentam o rendimento: Efeitos combinatórios do plantio adventício que aumentam a produtividade:
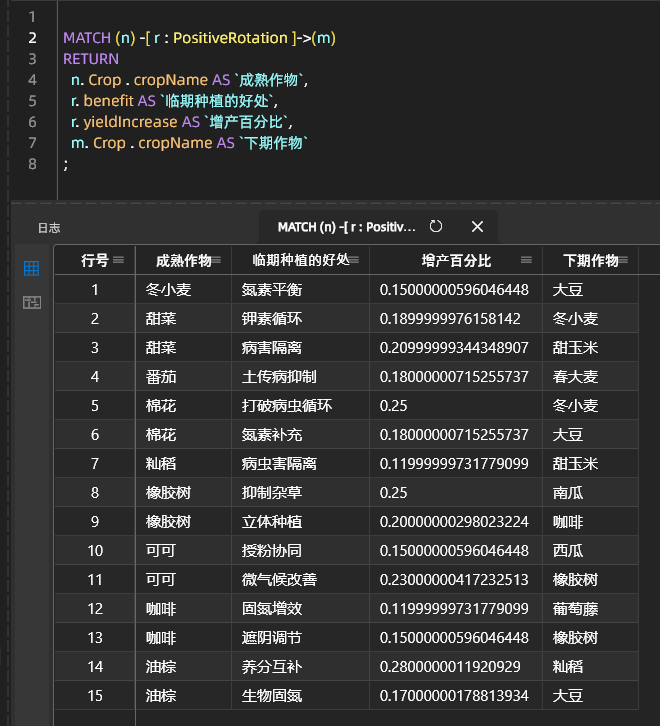
IV. Resumo
Conclusão: O DeepSeek é excelente na construção e fusão de gráficos de conhecimento, e os experimentos demonstram seus recursos:
- A extração de informações é rápida e precisa: O DeepSeek extrai rapidamente as principais informações do texto, gera scripts nGQL compatíveis e tem uma forte compreensão do idioma para reconhecer entidades, relacionamentos e eventos.
- Forte capacidade de integrar conhecimentos: O DeepSeek funde bem o conhecimento de vários artigos, expande e atualiza o gráfico com base em novos artigos e garante a integridade e a precisão do gráfico.
- Você pode criar um mapa a partir do nada: Nenhum artigo pode gerar gráficos por tópico. Há alguns problemas de sintaxe no processo de geração, mas os ajustes produzem scripts aceitáveis.
- Os detalhes precisam ser otimizados: Os scripts gerados pelo DeepSeek ocasionalmente apresentam problemas de sintaxe, como comentários incorretos. Ao gerar um grande número de nós, o servidor pode demorar a responder. Você precisa prestar atenção a esses problemas quando for usá-lo de fato.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...