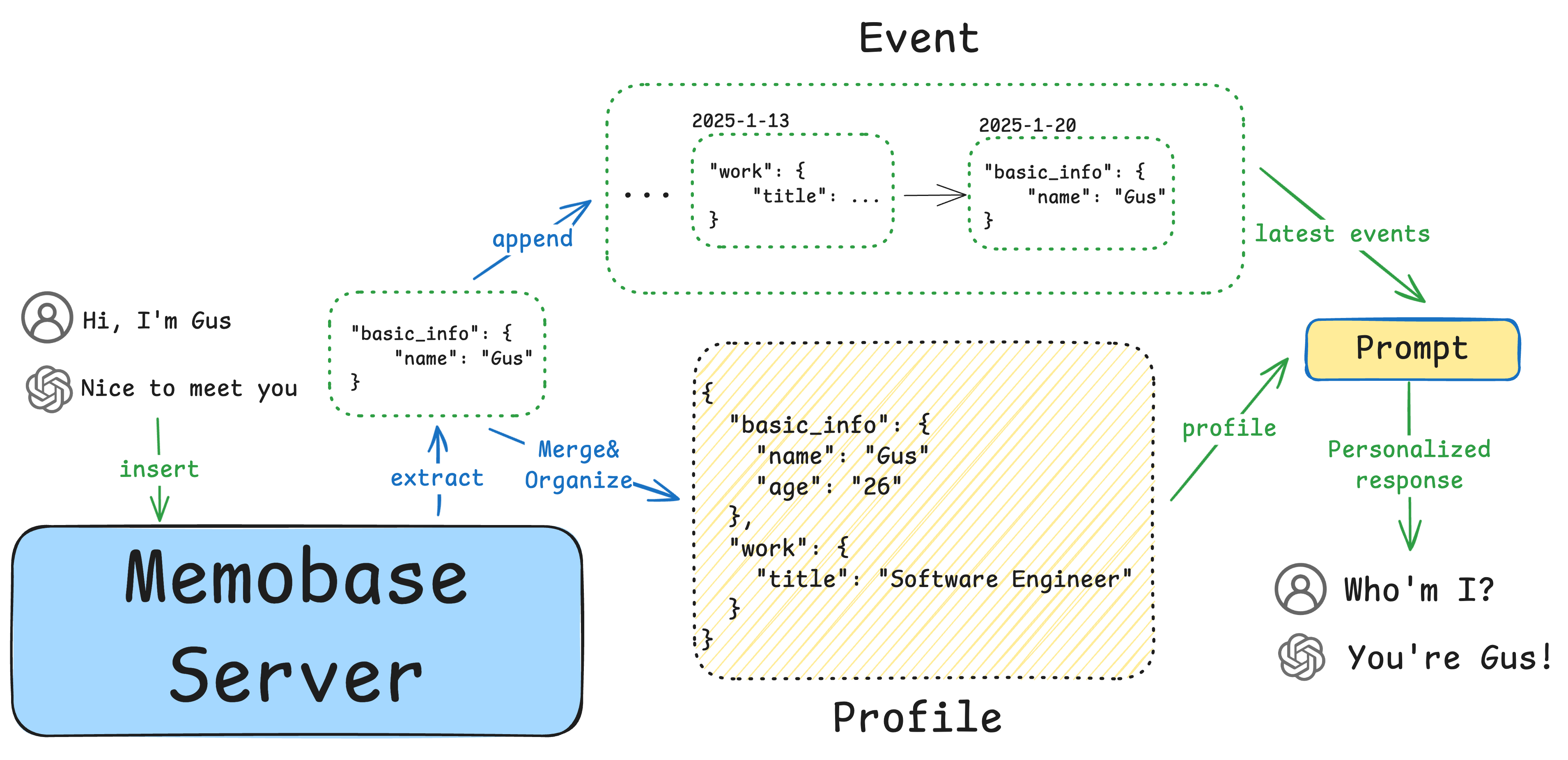

일반 소개
Zonos는 Zyphra에서 개발한 오픈 소스 음성 합성 및 음성 복제 도구로, Zonos-v0.1 버전은 고급 기능을 사용합니다. 트랜스포머 Zonos의 음성 복제 기능은 단 몇 초의 레퍼런스 오디오만으로 고품질의 음성 출력을 생성합니다. 이 도구는 영어, 일본어, 중국어, 프랑스어, 독일어 등 여러 언어를 지원하고 오디오 품질과 감정을 세밀하게 제어할 수 있으며, Zonos의 음성 복제 기능은 단 몇 초의 레퍼런스 오디오만 제공하면 매우 자연스러운 음성을 생성합니다. 사용자는 깃허브를 통해 모델 가중치와 샘플 코드를 다운로드하여 허깅페이스에서 사용해 볼 수 있습니다.

기능 목록
- 제로 샘플 TTS 음성 복제고품질 음성 출력을 생성하기 위해 텍스트와 10~30초 분량의 스피커 샘플을 입력합니다.
- 오디오 접두사 입력더 풍부한 화자 매칭을 위해 텍스트 및 오디오 접두사를 추가합니다.
- 다국어 지원언어: 영어, 일본어, 중국어, 프랑스어, 독일어가 지원됩니다.
- 오디오 품질 및 감정 제어말하기 속도, 음조 변화, 음질, 감정(예: 행복, 두려움, 슬픔, 분노) 등 생성된 오디오의 여러 측면을 세밀하게 제어할 수 있습니다.
- 실시간 음성 생성고음질 음성의 실시간 생성을 지원합니다.
도움말 사용
설치 프로세스
- 복제 프로젝트터미널에서 다음 명령을 실행하여 Zonos 프로젝트를 복제합니다:
bash
git clone https://github.com/Zyphra/Zonos.git
cd Zonos - 종속성 설치다음 명령을 사용하여 필요한 Python 종속 요소를 설치합니다:
bash
pip install -r requirements.txt - 모델 가중치 다운로드허깅페이스에서 필요한 모델 가중치를 다운로드하여 프로젝트 디렉토리에 배치합니다.
사용법
- 모델 로드파이썬 환경에서 Zonos 모델을 로드합니다:
import torch import torchaudio from zonos.model import Zonos from zonos.conditioning import make_cond_dict model = Zonos.from_pretrained("Zyphra/Zonos-v0.1-transformer", device="cuda") - 음성 생성음성 출력을 생성하기 위해 텍스트 및 화자 샘플을 제공합니다:
python
wav, sampling_rate = torchaudio.load("assets/exampleaudio.mp3")
speaker = model.make_speaker_embedding(wav, sampling_rate)
cond_dict = make_cond_dict(text="Hello, world!", speaker=speaker, language="en-us")
conditioning = model.prepare_conditioning(cond_dict)
codes = model.generate(conditioning)
wavs = model.autoencoder.decode(codes).cpu()
torchaudio.save("sample.wav", wavs[0], model.autoencoder.sampling_rate) - 라디오 인터페이스 사용음성 생성에는 Gradio 인터페이스를 사용하는 것이 좋습니다:
bash이렇게 하면
uv run gradio_interface.py
# 或者
python gradio_interface.pysample.wav파일을 프로젝트 루트 디렉토리에 저장합니다.
세부 기능 작동 흐름
- 제로 샘플 TTS 음성 복제::
- 원하는 텍스트와 화자의 10~30초 샘플을 입력하면 모델이 고품질의 음성 출력을 생성합니다.
- 오디오 접두사 입력::
- 텍스트 및 오디오 접두사를 추가하여 더욱 풍부한 화자 매칭을 구현할 수 있습니다. 예를 들어 속삭임 오디오 접두사를 사용하여 속삭임 효과를 생성할 수 있습니다.
- 다국어 지원::
- 원하는 언어(예: 영어, 일본어, 중국어, 프랑스어 또는 독일어)를 선택하면 모델이 해당 언어로 음성 출력을 생성합니다.
- 오디오 품질 및 감정 제어::
- 모델의 조건 설정 기능을 사용하여 말하기 속도, 음조 변화, 음질, 감정(예: 행복, 두려움, 슬픔, 분노) 등 생성된 오디오의 모든 측면을 세심하게 제어할 수 있습니다.
- 실시간 음성 생성::
- Gradio 인터페이스 또는 기타 실시간 생성 방법을 사용하여 고음질 음성을 빠르게 생성할 수 있습니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...