
논문 주소: https://arxiv.org/abs/2404.17723
지식 그래프는 표적화된 방식으로만 엔티티 관계를 추출할 수 있으며, 이렇게 안정적으로 추출 가능한 엔티티 관계는 다음과 같이 이해할 수 있습니다.구조화된 데이터에 접근하기.
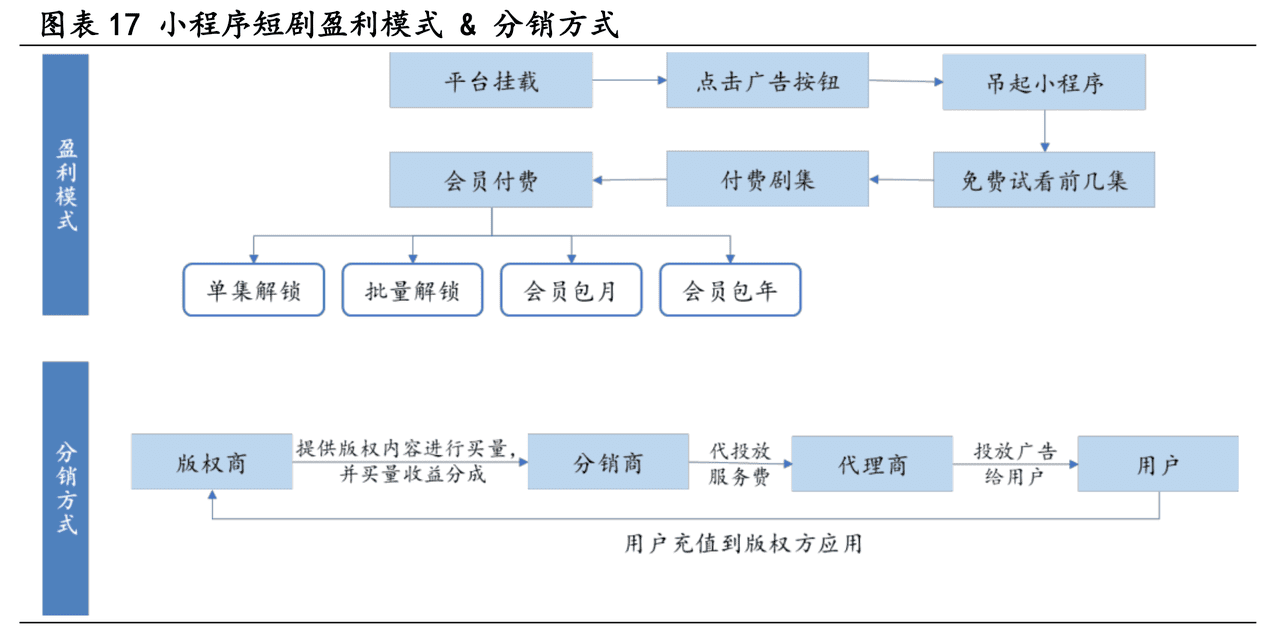
그림 1은 지식 그래프(KG)와 검색 증강 생성(RAG)을 결합한 고객 서비스 Q&A 시스템의 워크플로우를 보여줍니다. 이 프로세스는 아래에 요약되어 있습니다:
1. 지식 매핑: 시스템은 두 가지 주요 단계를 포함하여 과거 고객 서비스 문제 티켓으로부터 종합적인 지식 맵을 구축합니다:
- 내부 티켓 트리 표현: 각 이슈 티켓은 티켓의 여러 부분(예: 요약, 설명, 우선 순위 등)을 나타내는 노드가 있는 트리 구조로 구문 분석됩니다.
- 티켓 간 연결: 이슈 추적 티켓의 명시적 연결과 의미적 유사성을 통해 추론된 암시적 연결을 기반으로 개별 티켓 트리를 완전한 그래프로 연결합니다.
2. 임베딩 생성: 사전 학습된 텍스트 임베딩 모델(예: BERT 또는 E5)을 사용하여 그래프의 노드에 대한 임베딩 벡터를 생성하고 이러한 임베딩을 벡터 데이터베이스에 저장합니다.
3. 검색 및 질의응답 프로세스:
- 질문 의도 임베딩: 사용자 쿼리를 구문 분석하여 명명된 엔티티와 의도를 식별합니다.
- 임베딩 기반 검색: 엔티티를 사용하여 가장 관련성이 높은 티켓을 검색하고 관련 하위 그래프를 필터링합니다.
- 필터링: 가장 관련성이 높은 정보를 추가로 선별하고 식별합니다.
4. 검색된 티켓: 시스템이 사용자의 쿼리와 관련된 특정 티켓(예: ENT-22970, PORT-133061, ENT-1744, ENT-3547)을 검색하여 이들 간의 복제(CLONE_FROM/CLONE_TO) 및 유사성(SIMILAR_TO) 관계를 표시합니다.
5. 답변 생성: 최종적으로 시스템은 검색된 정보와 원래 사용자 쿼리를 합성하여 대규모 언어 모델(LLM)을 통해 답변을 생성합니다.
6. 그래프 데이터베이스 및 벡터 데이터베이스: 이 과정에서 그래프 데이터베이스는 아틀라스의 노드와 링크를 저장하고 관리하는 데 사용되며, 벡터 데이터베이스는 노드의 텍스트 임베딩 벡터를 저장하고 관리하는 데 사용됩니다.
7. LLM 사용 단계: 여러 단계에 걸쳐 대규모 언어 모델을 사용하여 텍스트를 구문 분석하고, 쿼리를 생성하고, 하위 그래프를 추출하고, 답변을 생성합니다.
이 순서도는 지식 그래프와 검색 개선 생성 기술을 결합하여 고객 서비스를 위한 자동화된 Q&A 시스템의 효율성과 정확성을 어떻게 개선할 수 있는지에 대한 개괄적인 시각을 제공합니다.

이 그림의 왼쪽은 지식 그래프의 구성을, 오른쪽은 검색 및 Q&A 프로세스를 보여줍니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...