

RTX 4090 그래픽 카드로 DeepSeek-R1을 실행합니다.Q4_K_M 정량화된 671B 풀 블러드 버전에 대한 권장 환경 설정에 의존하는 경우 14B 또는 32B의 정량화 된 버전으로, 그리고 KTransformers를 사용하는 경우 Unsloth 정량적 버전이 도입되었으며, 여기에 또 다른 버전이 있습니다. Ollama 설치 튜토리얼 DeepSeek R1 671B 로컬 배포 튜토리얼: 올라마 및 동적 정량화 기반'극한의 파워'를 원하는지, '더 빠른 속도'를 원하는지에 따라 다릅니다. '극한의 파워'를 원하는지, '더 빠른 속도'를 원하는지에 따라 다릅니다.
1️⃣ RTX 4090 풀 블러드 버전(671B)도 실행되나요?
예! 칭화대학교 팀의 KT트랜스포머 단일 4090 그래픽 카드로 풀 블러드 버전을 실행할 수 있습니다.
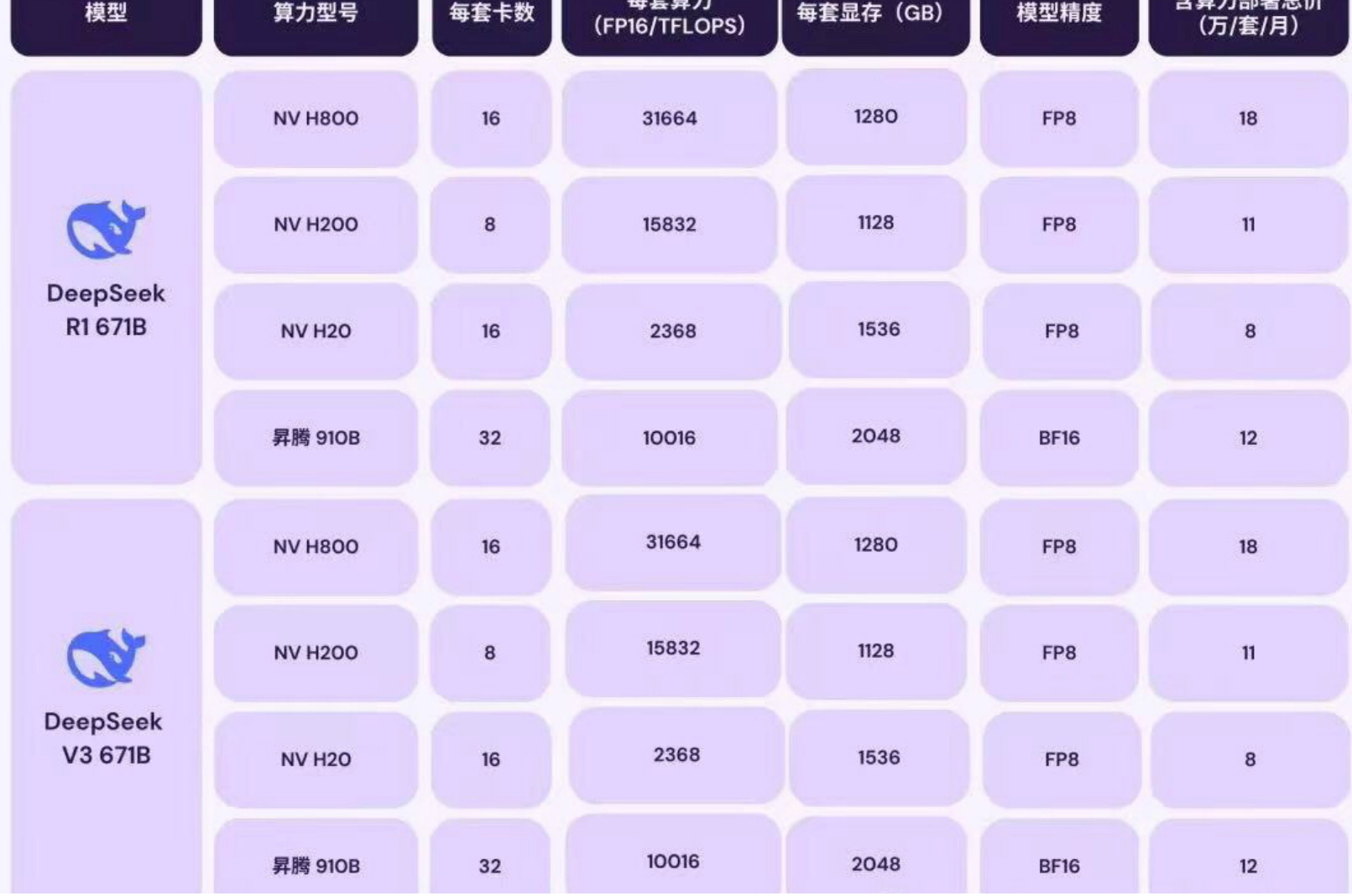
- VGA 메모리 요구 사항Q4_K_M 퀀티즈드 에디션은 14GB의 비디오 메모리만 필요하며, 4090은 24GB면 충분합니다.
- 속도초당 최대 286단어의 전처리 속도와 초당 약 14단어의 생성 속도는 이미 일반인이 보기에는 너무 빠른 속도입니다.
- 시나리오코드 작성, 다중 라운드 대화와 같이 복잡한 추론이 필요한 작업.
2️⃣ 속도가 너무 느리다면? 더 작은 버전을 사용해 보세요.
초당 14단어가 너무 느리다고 생각되면 더 작은 모델을 선택할 수 있습니다:
- 14B 정량화 버전그래픽 메모리 요구 사항은 약 6.5GB로, 일상적인 쓰기와 번역에 더 빠른 속도를 제공합니다.
- 32B 양자화 버전14.9GB의 비디오 메모리가 필요하며 긴 텍스트 처리(예: 전체 논문 분석)를 지원합니다.
3️⃣ 풀 블러드 버전이 대신 실행되는 이유는 무엇인가요?
기술적 트릭을 소개합니다:정량적 + 계산적 오프로딩.
- 정량화 가능모델을 더 작은 크기로 '압축'(예: 4비트 양자화(Q4))하면 메모리 사용량이 70% 감소합니다.
- 언로드 계산중요하지 않은 연산 작업은 CPU가 처리하도록 내버려두고 GPU가 가장 잘할 수 있는 작업만 처리하도록 합니다.
4️⃣ 다른 그래픽 솔루션과 비교
다시 정식 버전을 실행합니다:
- H100 그래픽 클러스터수십만 달러의 비용이 들며 더 빠르지만 일반인에게는 적합하지 않습니다.
- 자체 개발 그래픽 카드: 호환성이 충분하지 않고 웅덩이에 빠지기 쉽습니다.
평결에 도달하기4090은 가장 비용 효율적인 옵션입니다.
5️⃣ 배포 팁
- 비용 또는 지출
KTransformers이 프레임워크는 클릭 한 번으로 배포할 수 있으며 ChatGPT와 동일한 인터페이스가 제공됩니다. - 메모리가 부족하다면 조금 더 빠른 '전문가 6명만 활성화' 모드를 사용해 보세요.
가장 똑똑한 AI를 원한다면 671B Quantized를, 부드러운 대화를 원한다면 14B/32B를 선택하면 4090이 모든 것을 제공합니다!
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...