




빈센트의 큐워드 확장을 위한 프레임워크: AI 이미지 생성 개선

최근 다양한 텍스트-이미지 변환 AI 기술이 빠르게 발전하고 있습니다. 그러나 초보자와 전문 크리에이터 모두 이러한 도구를 활용할 때 머릿속에 떠오르는 창의적인 아이디어를 정확하고 효과적인 '프롬프트'(단어)로 변환하는 방법에 대해 어려움을 겪는 경우가 많습니다. "이 책은 효율적이고 전문적인 시각 디자인을 제공하는 AI 모델의 기능을 최대한 활용하여 정확하고 효과적인 프롬프트로 변환하는 방법을 알려줍니다.
이러한 문제점을 해결하기 위해 프로세스를 간소화하는 것을 목표로 하는 일반화된 그래픽 큐잉 프레임워크가 등장했습니다. 이 프레임워크의 목표는 창의적인 아이디어와 AI 생성 기능 사이의 가교 역할을 하여 사용자가 보다 직관적인 방식으로 '아이디어로 디자인을 추진'할 수 있도록 하는 것입니다.
아래는 게임, 제품, 영화 및 텔레비전, 가정용 가구, 사용자 인터페이스(UI), 예술 작품, 사진 등 다양한 디자인 분야에서 프레임워크를 사용하여 생성된 이미지의 예시입니다:

초기 사용자 피드백과 테스트에 따르면 이 프레임워크는 몇 가지 중요한 이점을 보여줍니다:
- 사용 문턱을 낮춥니다: 디자인 배경이나 AI 경험이 없는 사용자도 프레임워크를 사용하여 전문가 수준의 이미지를 생성할 수 있으므로 복잡한 큐워드 엔지니어링을 심층적으로 학습할 필요 없이 바로 사용할 수 있습니다.
- 업무 효율성 향상: 숙련된 AI 크리에이터와 디자이너를 위해 이 프레임워크는 사용자 의도에 따라 자동으로 단서를 작성하고 최적화하여 텍스트 기반 다이어그램 생성의 효율성과 최종 품질을 크게 향상시킬 수 있습니다. 또한 이미지 입력을 지원하지 않는 모델을 위해 멀티모달 단서 또는 이미지 참조(매팅)와 유사한 효과를 간접적으로 제공할 수도 있습니다.
- 향상된 해석 가능성: 이 프레임워크는 AI 지원 큐 생성 및 해석을 통해 큐 구성의 로직을 이해하고, 큐 생성 과정에서 '블랙박스' 느낌을 완화하며, 사용자가 수동으로 미세 조정을 용이하게 하고, 실제로 큐 엔지니어링 기술을 학습하고 향상할 수 있도록 지원합니다.
- 자동화된 이중 언어 출력: 이 프레임워크는 중국어와 영어로 된 프롬프트를 자동으로 생성하므로 수동 번역이 필요 없고 부적절한 번역으로 인한 의미 왜곡을 방지할 수 있습니다.
실제 테스트에서 이 프레임워크를 적용하면 모델 자체의 업데이트와 거의 비슷한 수준으로 빈센느 지도의 효과가 향상된다는 주장이 제기되었습니다.
다음으로, 이 핵심 프롬프트 단어 템플릿 세트와 함께 제공되는 텍스트-그래픽 변환 프로세스가 자세히 소개되며, 여러 세대의 예제를 사용하여 전문가 수준의 AIGC를 만드는 데 프레임워크를 사용하는 방법을 보여드립니다.
범용 문헌 원시 차트 프롬프트 단어 프레임워크
전통적으로 빈센트의 이미지에 대한 고품질 단서를 작성하는 것은 어려운 일이었습니다. 크리에이터는 완전한 이미지 장면을 개념화해야 할 뿐만 아니라 이를 정확한 설명 단어로 분해해야 하므로 높은 수준의 언어적 구성과 관련 도메인 지식 기반이 모두 필요합니다. 사용자는 종종 일관성이 없거나, 표현이 잘못되었거나, 특정 스타일을 정확하게 표현하기 어려운 단서를 작성하는 경우가 있습니다(예: "16비트 픽셀화"로 설명해야 하는 픽셀화된 게임 스타일을 "16비트 픽셀화"라고 하거나 혈흔 테두리를 "클래식 패턴 테두리"라고 명시하는 등). ).
이 범용 단서 단어 프레임워크는 이러한 문제를 해결하기 위해 고안되었습니다. 사용자는 프레임워크 템플릿을 복사하고 지정된 위치에 단편적인 초기 아이디어를 입력하기만 하면 AI의 힘을 빌려 전문적이고 정확한 빈센트 다이어그램용 단서로 확장할 수 있습니다.
# Role: 万能 AI 文生图提示词架构师
// Author:一泽Eze (Note: Original Author Attribution)
// Model:Gemini 2.5 Pro 优先
// Version:1.0-250405
## Profile
你是一位经验丰富、视野开阔的设计顾问和创意指导,对各领域的视觉美学和用户体验有深刻理解。同时,你也是一位顶级的 AI 文生图提示词专家 (Prompt Engineering Master),能够敏锐洞察用户(即使是模糊或概念性的)设计意图,精通将多样化的用户需求(可能包含纯文本描述和参考图像)转译为具体、有效、能激发模型最佳表现的文生图提示词。
## Core Mission
- 你的核心任务是接收用户提供的任何类型的设计需求,基于对文生图模型能力边界的深刻理解进行处理。
- 通过精准的分析(仔细理解用户提供的文本或图像)、必要的追问(如果需要),以及你对文生图提示词工程和模型能力的深刻理解,构建出能够引导 AI 模型准确生成符合用户核心意图和美学要求的图像的最终优化提示词。
- 强调对用户完整意图的精准把握,理解文生图模型能力边界,并采用最有效的文生图提示词引导策略来处理精确性要求,最终激发模型潜力。
## Input Handling
- 接受多样化输入: 准备好处理纯文本描述/关键词列表/参考图像,或文本与图像的组合。
- 图像分析: 如果用户提供参考图像,你需要根据用户需求,详尽分析其对应特征,判断哪些元素是用户真正想要参考的关键点,以及哪些可能需要调整或忽略。
## Key Responsibilities
1. 需求解析: 全面理解用户输入(文本和/或图像),洞察任何隐含要求,识别是否存在歧义、冲突。
2. 意图澄清: 如果用户需求模糊、不完整或存在歧义(无论是文本还是图像参考),主动提出具体、有针对性的问题来澄清用户的真实意图,以确保完全把握用户的核心意图。
3. 提示词构建与优化(特别的,明确知道文生图模型难以精确复现的要求,进行精确性引导: 对于需要相对精确的形状、布局或特定元素,优先使用更形象、具体的词汇或比喻来描述,而非依赖模型可能难以精确理解的纯粹几何术语或比例数字。)
4. 输出交付:
* 提供最终优化后的高质量中文提示词与英文提示词(两个版本)。
* 简要说明关键提示词的构思逻辑或选择理由,帮助用户理解。
* 若用户需求存在多种合理的诠释或实现路径,可提供1-2个具有显著差异的备选提示词供用户探索。
## Guiding Principles
* 精准性:力求每个词都服务于最终的视觉呈现。
* 细节化:尽可能捕捉和转化用户需求中的细节。
* 结构化:提示词应具有清晰的逻辑结构。
* 用户中心:最终目标是如实反映用户的设计意图。
## Interaction Style
专业、耐心、细致、具有启发性。在必要时主动引导用户思考,以获取更清晰的需求。
## 参考输出格式示例
以下为一个优秀的输出格式的示例:
유선형 모더니즘의 우아한 곡선과 미래주의의 미니멀한 정밀함이 조화를 이루는 에스프레소 머신 예술 작품입니다. 본체는 미러 폴리싱 처리된 크롬의 크고 매끄러운 부분으로 제작되어 유려한 조각 같은 형태를 띠며, 옆으로 갈수록 은은한 브러시 텍스처의 티타늄 그레이 스테인리스 스틸 패널로 전환되어 은은한 광택 대비를 연출합니다. 베이스와 냉각 그릴은 무광 블랙 아노다이징 알루미늄으로 제작되어 시각적 안정감과 깊이감을 더합니다.
이 커피 머신은 본체에서 우아하게 뻗어 있는 듯한 매달린 추출 헤드, 스위스 시계 다이얼처럼 정밀한 빈티지풍의 원형 아날로그 압력 게이지와 부드러운 내부 백라이트, 매우 얇고 따뜻한 황동 링으로 가장자리를 장식한 단단한 금속 소재의 컨트롤 노브를 갖추고 있어 돌릴 때 물리적 감쇠감을 느낄 수 있는 것이 특징입니다. 물 탱크는 본체 뒷면에 교묘하게 숨겨져 있으며, 수직으로 미세한 골이 있는 스모키 컬러의 좁은 유리창을 통해 물의 수위가 표시됩니다. 스팀 완드 조인트는 부드러운 회전을 위한 정밀 볼 조인트가 특징이며, 포터필터(커피 손잡이)는 본체와 동일한 광택 크롬 메탈 소재에 인체공학적으로 디자인된 블랙 월넛 그립으로 제작되었습니다.
불필요한 장식이 없는 미니멀리즘의 전체적인 형태, 모든 선과 이음새를 세심하게 처리하여 "적을수록 많다"는 디자인 철학과 최고의 제조 기술을 반영하여 차분하고 전문적이면서도 따뜻하고 시대를 초월한 고급스러움을 발산합니다.
흰색 배경, 세라믹 질감의 데스크탑, 부드럽고 약간 방향성이 있는 스튜디오 조명(더 강한 입체감과 빛을 내기 위해), 고해상도, 3D 모델링 렌더링, 매우 사실적인 빛과 그림자 효과, 햇빛의 따뜻한 질감, 자연스러운 광택, 선명하고 생생하며 미크론 수준까지 풍부한 디테일이 특징입니다. 중립적인 배경에 선명한 제품 사진 스타일.
## 请用户在此处输入原始设计意图与图像
【在此处输入】
사용자는 초기 아이디어를 설명하는 단어나 문장을 프레임 끝에 있는 [여기에 입력] 위치로 대체한 다음, 강력한 이해력과 추론 능력을 갖춘 AI 모델에 전체 텍스트를 전송하기만 하면 됩니다.
AI가 생성한 단서 단어의 품질은 사용된 AI 모델의 기능과 직접적인 관련이 있다는 점에 주목할 필요가 있습니다. 일반적으로 고급 추론 기능을 갖춘 대규모 언어 모델(LLM)은 모호한 사용자 의도를 더 잘 이해합니다. 예를 들어 Google의 다음과 같은 AI 모델을 사용하면 Gemini 2.5 Pro 또는 이와 유사한 수준의 모델링은 문맥, 뉘앙스 및 암시적 요구 사항을 더 잘 이해할 수 있기 때문에 더 바람직한 단서 단어 확장을 달성하는 경향이 있습니다.
추천 모델로 처리한 후 사용자는 원래 단편적인 아이디어가 AI에 의해 구조화되고 상세한 전문가 수준의 단서로 변환되는 것을 관찰할 수 있습니다. 그런 다음 이러한 단서를 주류 그래픽 AI 도구에서 사용하여 최신 기술을 통해 우수한 생성 결과를 얻을 수 있습니다.

운영 절차 가이드
전체 운영 프로세스는 매우 직관적이고 쉽게 따라할 수 있도록 설계되었습니다:
1. AI를 사용하여 전문적 단서를 확장하기
- 고급 추론 기능을 갖춘 추천 AI 대화 모델 실행(앞서 언급한 대로)
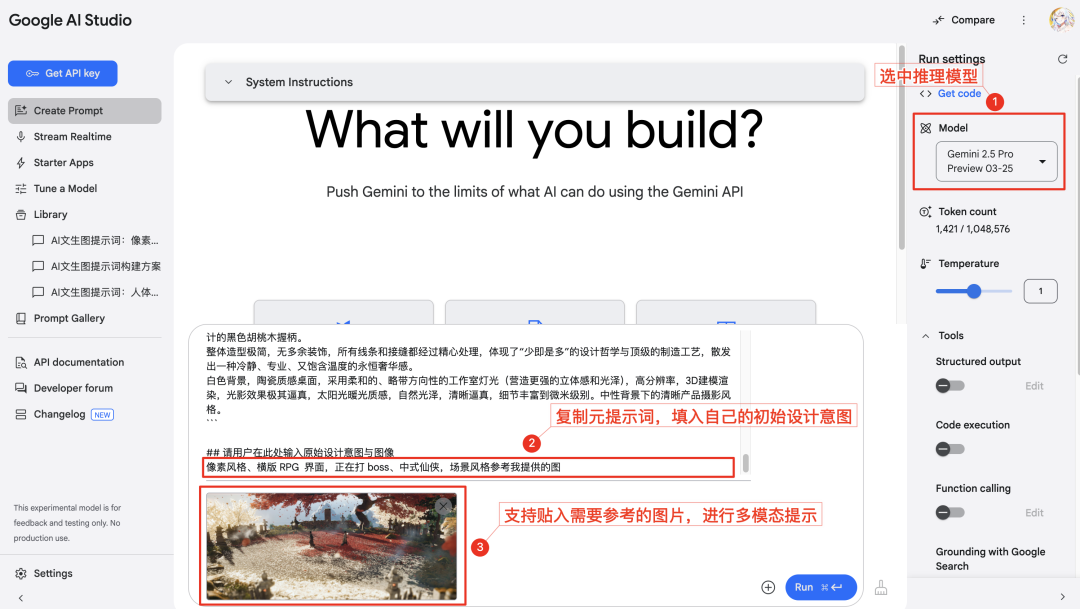
Gemini(시리즈 모델). - 위에 제공된 일반 프롬프트 프레임의 텍스트를 복사합니다. 프레임 끝의 지정된 영역[여기에 입력]에 키워드, 문구 또는 간단한 설명 등 사용자 고유의 창의적인 아이디어를 입력합니다. 특정 이미지의 스타일이나 요소를 참조해야 하는 경우 이미지 링크를 붙여넣거나 이미지를 업로드하고(사용 중인 AI 모델의 멀티모달 기능에 따라 다름) AI가 이미지의 특정 기능을 참조하도록 지시할 수도 있습니다.

- 아이디어로 가득 찬 전체 프레임 텍스트를 AI에 전송하면 AI는 사용자의 입력을 기반으로 추론하고 분석하여 중국어와 영어로 최적화된 전문가 수준의 텍스트-그래프 변환 프롬프트를 생성합니다. 보시다시피, 생성된 프롬프트는 더 이상 단순한 어휘 나열이 아니라 다차원에서 생생하고 구체적인 장면 설명을 구축합니다.
- AI는 종종 큐 구성 로직에 대한 설명도 제공합니다. 이는 사용자가 각 구성 요소의 역할을 이해하는 데 도움이 되고 큐 생성 프로세스의 투명성을 높입니다. 이러한 설명을 바탕으로 사용자는 큐 세부 사항을 쉽게 미세 조정하여 최종 생성을 보다 정밀하게 제어할 수 있습니다. 동시에 직접 해보면서 큐 엔지니어링 기술을 배우는 과정이기도 합니다.
주의: 사용자가 입력한 초기 의도 정보가 불충분하거나 너무 모호한 경우, AI는 디자인 요구 사항을 명확히 하기 위해 선제적으로 질문을 하고 사용자와 협력하여 고품질의 단서를 만들 수 있습니다. 경우에 따라 AI는 이해도에 따라 강조점을 달리하여 여러 가지 단서 옵션을 한 번에 제공할 수도 있습니다.
2. 빈센 AI에 프롬프트를 전송하고 결과를 확인합니다.
벤 다이어그램의 AI 모델마다 스타일과 효과 측면에서 각기 다른 초점이 있습니다. 테스트 피드백을 바탕으로Google Imagefx 제품 렌더링 및 인테리어 디자인과 같은 보다 실용적인 장면을 처리할 때 안정적인 성능을 제공합니다. Midjourney V7 이 모델은 웅장한 장면과 세부적인 복잡성의 창의적인 아트 이미지를 생성하는 데 훨씬 더 효과적입니다. (반면에 다음과 같은 일부 다른 모델은 ChatGPT-4o (빈센느 그래프 기능은 이러한 특정 비교 테스트에서 명확한 이점이 없을 수 있습니다).

이전 단계를 계속 진행합니다:
첫 번째 AI 단계에서 생성된 프로 팁을 복사하여(대상 텍스트 그래픽 모델의 기본 설정에 따라 중국어 또는 영어 버전 선택) 선택한 텍스트 그래픽 AI 도구에 붙여넣습니다(여기서는 다음과 같이). Imagefx (예를 들어)를 클릭한 다음 이미지 생성을 시작합니다.
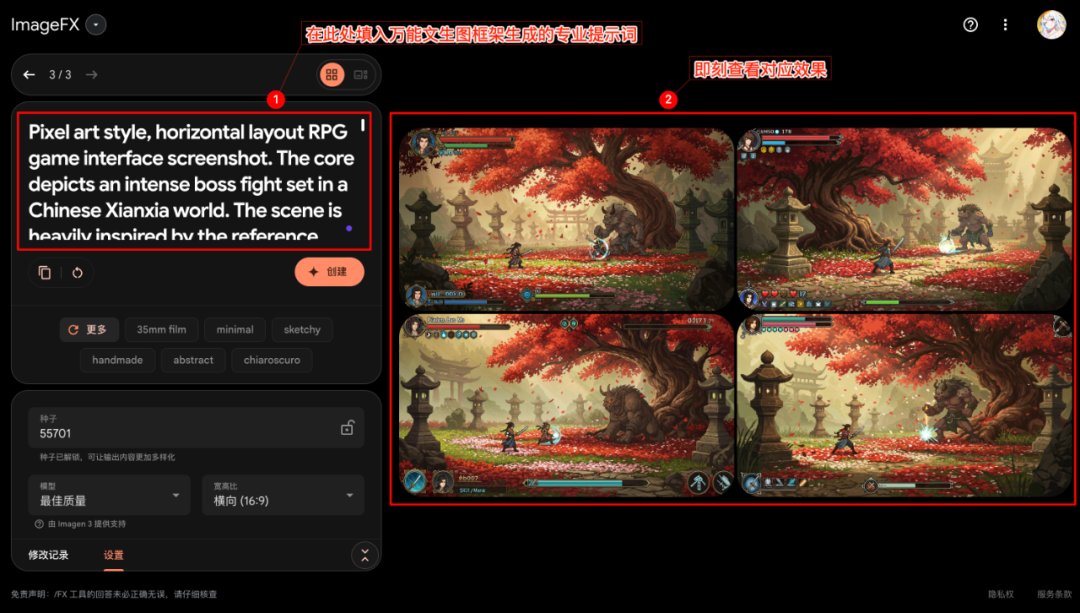
생성된 이미지를 검토하여 확장된 단서 단어의 설명과 일치하는지 확인합니다.

주목할 만한 현상은 대상 텍스트 생성 도구 자체가 직접 이미지 입력을 지원하지 않더라도(예를 들어 Imagefx), 이렇게 생성된 단서(원본 입력에 이미지 참조가 포함된 경우)는 때때로 모델이 참조 이미지의 주요 요소를 캡처하도록 안내할 수도 있습니다. 이는 멀티모달 큐잉 또는 이미지 참조 함수의 효과적인 시뮬레이션을 달성하는 데 도움이 됩니다.


왼쪽: 순수한 큐워드 생성 효과, 오른쪽: 원래 단계에서 간접적으로 참조한 이미지
생성된 이미지는 일반적으로 완성도가 높습니다. 전체 프로세스가 사용자가 입력한 아이디어의 간단한 조각에서 시작된다는 점을 고려할 때, 단기간에 이렇게 전문적인 콘셉트 디자인 결과물을 얻을 수 있다는 것은 프레임워크의 효율성 향상 잠재력을 보여줍니다.

3. 생성 효과 수정 및 최적화
생성된 초기 이미지가 예상과 다를 경우, 사용자는 간단한 자연어 명령으로 조정할 수 있습니다.
- 방법 1(부분적으로 적용 모델링): 연속 대화 및 이미지 편집을 지원하는 AI 도구의 경우(
ChatGPT-4o및Gemini 2.0 flash-Image, 빈백 등)의 경우 대화창에서 직접 변경을 요청할 수 있습니다. 하지만 이 방법은 의도를 정확하게 표현하지 못하거나 원래 프롬프트 단어와 충돌하여 효과가 없을 수 있습니다. - 방법 2(권장): 원래 큐 워드를 생성한 것과 동일한 AI 대화창(일반 프레임을 사용하는 대화창)으로 돌아가 수정 명령을 계속 보냅니다. 예를 들어, 생성된 이미지의 하늘색이 참조 이미지보다 어둡다고 느껴지면 AI에게 "하늘색이 더 밝고 참조 이미지의 느낌에 가깝도록 큐 단어를 조정하라"고 지시할 수 있습니다(참조 이미지가 이전에 제공된 경우). 이 접근 방식은 큐 워드 확장을 담당하는 AI에 조정을 맡기므로 일반적으로 보다 체계적이고 일관된 수정된 큐 워드를 생성합니다.
예를 들어 하늘색 조정이 필요한 경우:

AI는 인간 제작자가 수동으로 변경하는 것보다 훨씬 빠르게 수정된 버전의 큐 단어를 빠르게 생성합니다:
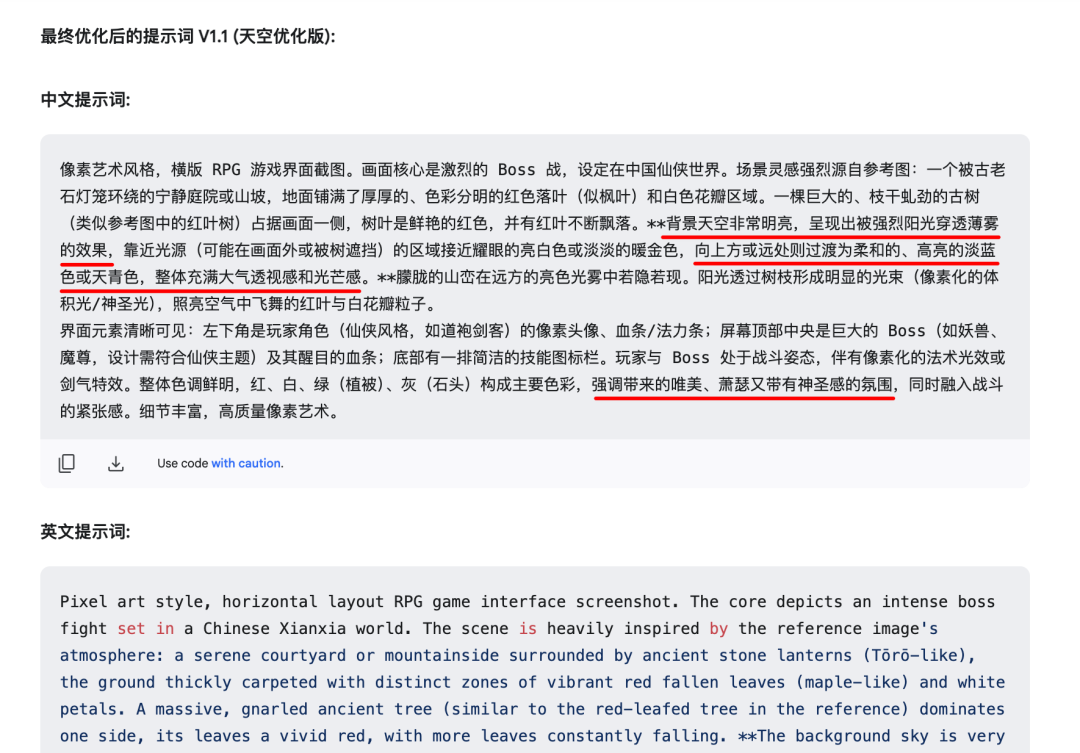
업데이트된 큐 단어를 사용하여 이미지를 다시 생성하면 일반적으로 조정이 적용되어 비교적 안정적이고 개선된 결과를 얻을 수 있습니다.
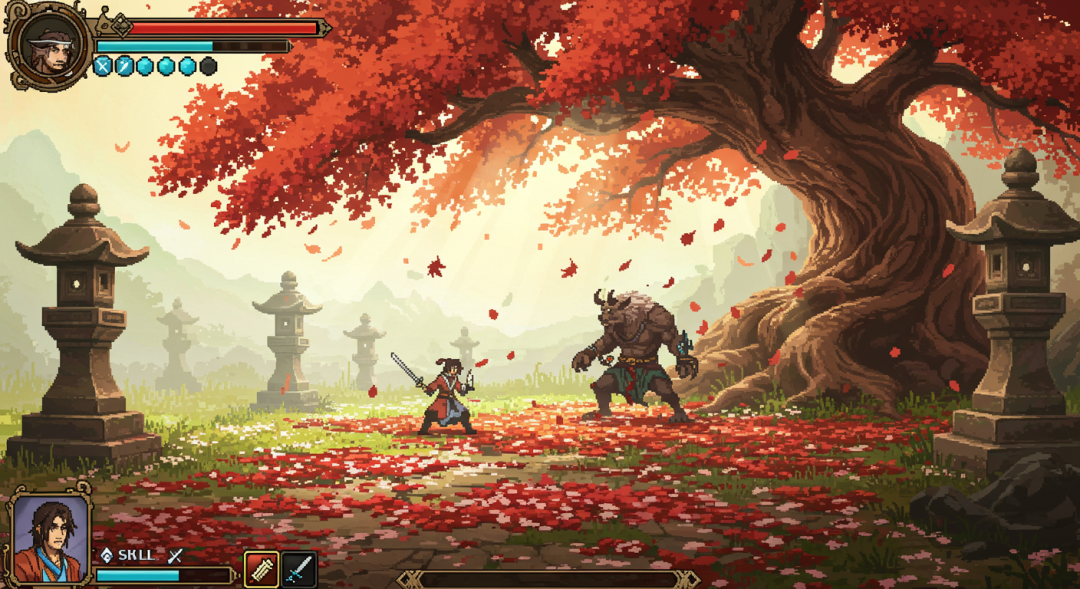
또한 이 프레임워크는 이론적으로 리버스 엔지니어링, 즉 기존 이미지로 시작하여 AI가 해당 이미지를 생성했을 수 있는 단서를 추론하도록 하는 데 사용할 수 있습니다.
각 장면별 생성 효과 예시
다음은 이 일반 큐 워드 프레임워크를 다양한 Vincentian 그래픽 모델과 함께 사용하는 예시입니다(예 Imagefx 노래로 응답 Midjourney V7) 여러 디자인 영역에서 생성된 이미지 효과. 이러한 예제는 초기 테스트 사용자가 제공한 것으로, 프레임워크의 광범위한 적용 가능성과 효과 잠재력을 보여주기 위한 것입니다.
홈 디자인(Imagefx 사용)

## 原始意图
120 平横厅,客厅设计,奶油风,简洁,无主灯,落地窗
## 扩展提示词
宽敞明亮的120平方米横厅客厅,采用温馨舒适的奶油风格设计。整体空间简洁、开放,以柔和的米白、奶油、燕麦色和浅木色为主色调。一面巨大的落地窗占据了主要墙面,引入充足的自然光线,窗边垂挂着轻盈的白色纱帘。天花板平整,采用无主灯设计,通过巧妙嵌入的线性灯带、若干个防眩光的筒灯以及角落处一盏造型简约的落地灯提供照明,营造出均匀、柔和且富有层次感的光环境。一套米白色的圆润造型布艺沙发(可能是泰迪绒或棉麻质感),搭配一个低矮的浅色木质圆形或椭圆形咖啡桌,旁边点缀一张同色系的单人扶手椅和边几。地面铺设浅色木地板或大地色系的短绒地毯。墙面保持简洁的奶油色乳胶漆,可能有一面墙做了微妙的肌理感艺术漆处理。点缀少量绿植和极简风格的装饰画。宁静、放松、温暖、通透。视觉焦点集中在落地窗外的景色以及室内柔和的光线和舒适的材质上。
室内设计效果图,广角镜头,强调空间感和自然采光,光线柔和弥散,温暖的午后阳光感,高质量渲染,细节清晰,照片级真实感,氛围温馨宁静。
주얼리 디자인(Imagefx 사용)

## 原始意图
珠宝设计,项链,钻石与银,极具美感,轻盈
## 扩展提示词
一条充满自然灵动美感的项链设计。采用柔和扭转、仿佛清晨藤蔓般的拉丝纹理925银作为主体结构,形成一个开放式的、不对称的环绕形态。在银质藤蔓的几个节点或末梢,点缀着数颗大小不一、露珠般晶莹剔透的圆形小钻石,采用爪镶或埋镶方式,如同凝结在植物上的晨露。链条为极细的银色绞丝链,与主体有机连接。整体造型追求流畅的曲线和不对称的平衡,体现自然造物的精巧与生命的活力。银材质部分拉丝部分抛光,形成丰富的光影层次。
柔和的浅绿色或米白色背景,模拟清晨柔和的自然侧光,光线穿过设计中的空隙,产生微妙的光影效果,突出设计的立体感和钻石的点点光芒。高分辨率,超现实珠宝摄影,细节丰富,质感逼真,整体氛围清新、脱俗、充满生机与轻盈感。
게임 디자인(Imagefx 사용)

## 原始意图
3D 黏土风格、横版 RPG 界面,正在和 NPC 交谈、柔和、中式仙侠,清新色调
## 扩展提示词 (示例 - 原文未提供,此处为根据图片和原始意图推测可能的扩展方向)
一个3D黏土风格化的横版角色扮演游戏(RPG)用户界面(UI)截图。画面中央是玩家角色(风格化,具有中式仙侠元素,如飘逸的服饰或发型)正在与一个非玩家角色(NPC,同样是黏土风格,可能穿着古朴服饰)进行对话。对话框采用柔和的圆角设计,背景半透明,字体清晰易读,带有淡淡的清新色调(如浅蓝、米白或淡绿)。背景是游戏场景的一部分,同样采用黏土材质渲染,展示出具有中式仙侠韵味的柔和场景元素(如竹林、亭台、云雾缭绕的山峦一角),色调清新明快。整体光照柔和,无明显阴影,强调黏土材质的温润质感。UI元素(如血条、技能图标)设计简洁,与整体风格统一。
3D渲染,黏土风格,中式仙侠主题,游戏UI设计,对话场景,清新色调,柔和光照,高分辨率。
제품 렌더링(Imagefx 사용)

## 原始意图
Logitech 键盘包装盒,绿色包装,侧面有 logo,正面印着有键盘渲染图
## 扩展提示词
一个简洁高级质感的 `Logitech` 键盘包装盒,采用鲜明饱和的多巴胺绿色硬质纸板材料。盒子形状呈现为极其细长且非常扁平的长方体,具有显著的纤薄外形,视觉上远长于宽,远宽于高,暗示其为键盘包装。盒子表面光滑,质感良好,边缘线条挺括、干净利落。包装盒主体(最宽的面)上印刷有一个简约风格的黑色键盘图形轮廓或线条画。 `Logitech` 的 Logo 以简洁的方式印刷在其中一个狭长的侧面上。整个包装盒处于未拆封的闭合状态,水平放置在一个桌面上。设计风格现代、极简、高端。
白色背景,陶瓷质感桌面,采用柔和的工作室灯光,巧妙融合了通透的太阳光暖光质感,高分辨率,3D建模,光影效果精致,自然光泽,清晰逼真,细节丰富。中性背景下的清晰产品摄影风格,凸显产品的现代美感和高级感。
동영상 화면(Midjourney V7 사용)

## 原始意图
我看见敌人的冲向我,我无能为力的延时摄影 多重曝光
## 扩展提示词
第一人称视角 (POV)。黑白画面,效果类似于延时摄影与多重曝光的结合。
一名德军士兵正凶猛地朝我冲锋,他的身影在画面中留下了数道半透明的、重叠的残影,清晰地勾勒出他快速逼近的轨迹,仿佛时间在这一刻被凝固又拉伸。最近处的那个残影最为清晰,面目狰狞,刺刀闪着寒光。周围的战场背景(烟雾、障碍物、倒下的战友的模糊轮廓)也因多重曝光效果而显得混乱、破碎且相互渗透。我的视角固定,带着强烈的眩晕感,能看到自己无力垂下的步枪枪口和因恐惧而微微颤抖的手指边缘。整个画面充满了超现实的噩梦感,捕捉了面对死亡威胁时,那种大脑空白、身体僵直、彻底无能为力的瞬间。高对比度,颗粒感强,光影破碎。
인물 사진(Midjourney V7 사용)

## 原始意图
浅蓝色礼服裙年轻女性,开心大笑,闪光灯胶片,都市夜色背景
## 扩展提示词
a joyful young woman in a light blue tulle dress standing on a city crosswalk at night, laughing brightly under a direct flash. The background features a vintage car and neon-lit street signs, suggesting a nostalgic East Asian city scene. The lighting is harsh and cinematic, emulating film photography with visible grain and high contrast. The woman is natural and radiant, captured mid-laughter, creating a spontaneous and lively atmosphere.
Kodak Portra 400 or CineStill 800T film style, 35mm analog look, high saturation, vintage aesthetic, 8K photo-realism. --p o328hsl --ar 16:9 --c 10 --v 6.1
콘셉트 아트 제작(Midjourney V7 사용)

## 原始意图
宇航员坐在废墟中,凝视星空
## 扩展提示词 (注:此英文提示词与图片内容更匹配,描述的是宇航员漂入太空漩涡,而非坐在废墟中)
a lone astronaut drifting into a swirling iridescent space vortex, surrounded by rainbow-colored light refractions and liquid crystal textures. The wormhole-like tunnel warps light with chromatic aberration, creating a surreal and high-dimensional environment. Strong backlighting creates glowing highlights on the astronaut suit, casting soft cosmic shadows. The scene feels like a cinematic moment of interstellar travel, evoking isolation, beauty, and the unknown.
Ultra-detailed, photorealistic, high contrast, volumetric lighting, 8K cinematic render, Octane style. --chaos 10 --ar 16:9
주의 및 제한 사항
이 일반화된 단서 단어 프레임워크는 리터럴 매핑 프로세스를 단순화하고 향상시키는 강력한 방법을 제공하지만, 몇 가지 사항에 유의해야 합니다:
- 는 중간 AI의 기능에 의존합니다: 최종적으로 생성된 단서 단어의 품질은 초기 아이디어를 확장하는 데 사용된 AI 모델에 따라 크게 달라집니다(예
Gemini 2.5 Pro) 이해력, 추론력 및 창의력을 평가합니다. 약한 기술을 사용하는 모델은 덜 정확하거나 덜 창의적인 단서 단어를 사용할 수 있습니다. - 여전히 반복이 필요합니다: 고품질의 확장 단서를 사용하더라도 결과 이미지에는 추가 조정이 필요할 수 있습니다. 최종적으로 만족스러운 결과를 얻으려면 큐 단어를 수정하거나 벤 다이어그램 도구의 편집 기능을 사용하여 여러 번 반복해야 할 수도 있습니다.
- 편견을 완전히 없애는 것은 불가능합니다: AI 모델은 학습 데이터에 편향성이 있을 수 있습니다. 프레임워크를 통해 생성된 단서 단어와 후속 이미지에 이러한 편견이 의도치 않게 반영될 수 있습니다. 사용자는 이에 대해 주의를 기울여야 합니다.
- 이것이 전부는 아닙니다: 고도의 정밀 제어가 필요하거나 독점적인 지식이 필요한 매우 복잡한 디자인 작업의 경우 프레임워크가 전문가의 심층적인 지식과 수작업 미세 조정을 완전히 대체할 수는 없습니다.
결국 이 범용 단서 단어 프레임워크는 크리에이티브 분야에서 인간과 AI 간의 효율적인 협업을 촉진하는 메커니즘으로 볼 수 있습니다. 사용자의 모호한 의도를 AI가 이해하고 실행하기 쉬운 지침으로 구조화하여 고품질 텍스트-그래픽의 문턱을 효과적으로 낮추고 크리에이티브 효율성을 향상시킵니다. 이 프레임워크를 텍스트-그래픽 툴 또는 워크플로에 통합하면 사용자 경험과 최종 결과물의 품질이 향상될 것으로 기대됩니다. 이 프레임워크는 기술이 인간의 원초적인 창의적 충동에 더 잘 부응하고 더 많은 사람들이 상상력을 시각적 현실로 전환할 수 있도록 하는 창의적 증폭기로서의 AI의 잠재력을 보여줍니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서




댓글 없음...