

VTP란 무엇인가요?
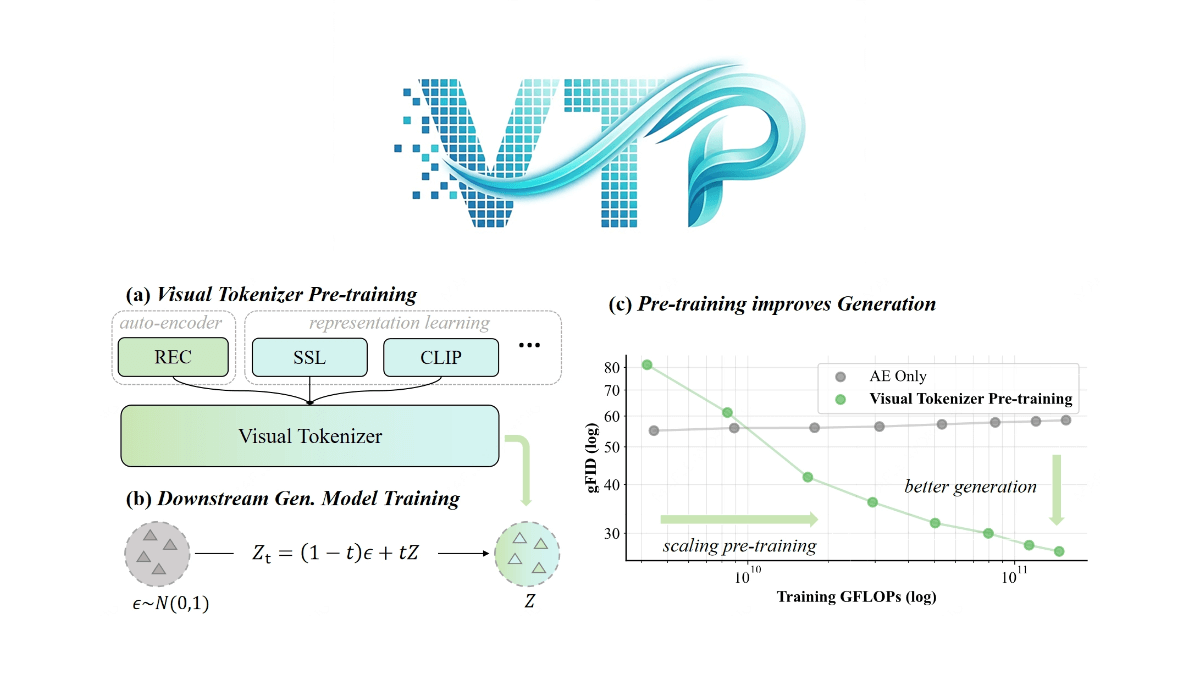
미니막스 콘치 비디오 팀이 제안한 시각 생성 모델의 핵심 기술인 VTP(Visual Tokenizer Pre-training)는 시각 토큰화기(토큰라이저)의 사전 학습 방식을 개선하여 생성 시스템의 성능을 향상시키는 기술입니다. 기존 방식에서는 토큰라이저가 이미지 재구성에만 집중했지만, VTP는 생성 품질의 핵심 동인으로 의미 이해 기능을 혁신적으로 도입했습니다. 이 프레임워크는 비전 트랜스포머 아키텍처를 채택하고 2단계 훈련 전략(표현 학습 최적화를 위한 사전 훈련 단계, 이미지 품질 향상을 위한 미세 조정 단계)과 멀티태스킹 목표(재구성, 자체 감독, 그래픽 비교)를 통해 처음으로 토큰나이저의 스케일업, 즉 계산 능력과 데이터 양이 증가하면 생성 효과가 동시에 향상되는 것을 달성했습니다. 실험 결과, VTP는 동일한 계산 예산에서 기존 VAE보다 훨씬 뛰어난 성능을 보여줌으로써 확산 모델과 멀티모달 매크로 모델에 보다 효율적인 시각적 기반을 제공합니다.
VTP의 특징
- 멀티태스크 공동 최적화VTP는 이미지-텍스트 대비 학습, 자기 지도 학습(예: 자체 증류 및 마스크 이미지 모델링), 공동 다중 작업 학습을 위한 대상의 픽셀 수준 재구성을 결합하여 모델의 의미 이해와 공간 인식을 향상시킵니다.
- 효율적인 확장성VTP는 뛰어난 확장성을 보여주며, 훈련 연산(FLOP), 모델 파라미터, 데이터 세트 크기가 증가함에 따라 생성 성능이 꾸준히 향상되어 대규모 사전 훈련 시 기존 셀프 인코더의 성능 병목 현상을 극복할 수 있습니다.
- 뛰어난 세대 성능이미지넷에서 VTP는 78.21 TP3T의 제로 샘플 분류 정확도와 0.36의 rFID를 달성하여 다른 방법보다 훨씬 뛰어난 성능을 보이며, 사전 학습 연산량만 늘려도 생성 품질을 크게 향상시킬 수 있는 다운스트림 생성 작업에서 우수한 성능을 발휘합니다.
- 빠른 컨버전스VTP는 사전 훈련 단계부터 재설계되어 증류 기반 모델에 기반한 방식에 비해 더 높은 성능 상한과 4.1배 빠른 수렴을 달성하여 훈련 효율성을 크게 향상시켰습니다.
- 오픈 소스 및 사용 편의성VTP는 연구자와 개발자가 빠르게 시작하고 실제 프로젝트에 적용할 수 있도록 사전 학습된 가중치 다운로드 및 빠른 시작 스크립트를 포함한 자세한 설치 및 사용 지침을 제공합니다.
VTP의 핵심 이점
- 멀티태스크 학습 통합VTP는 이미지-텍스트 대비 학습, 자기 지도 학습, 픽셀 수준 재구성 목표를 통합하고 멀티태스크 공동 최적화를 통해 모델의 의미 이해와 생성 기능을 크게 향상시킵니다.
- 강력한 확장성VTP는 사전 학습 단계에서 뛰어난 확장성을 보여주며 연산, 모델 파라미터, 데이터 세트 크기가 증가함에 따라 생성 성능이 꾸준히 향상되어 기존 셀프 인코더의 한계를 극복합니다.
- 우수한 세대 품질이미지넷과 같은 벤치마크에서 VTP는 제로 샘플 분류 정확도 78.21 TP3T, rFID 0.36을 달성하여 생성 품질 측면에서 다른 방법을 크게 능가하고 다운스트림 생성 작업에서도 우수한 성능을 발휘합니다.
- 신속한 컨버전스 기능VTP는 사전 훈련 단계부터 재설계되어 기존 방식에 비해 더 높은 성능 상한과 4.1배 빠른 컨버전스를 달성하여 훈련 효율을 크게 향상시켰습니다.
- 오픈 소스 및 사용 편의성VTP는 사용자가 빠르게 시작하고 실제 프로젝트에 적용할 수 있도록 자세한 설치 가이드와 사전 교육 가중치를 제공하여 사용의 문턱을 낮춥니다.
- 혁신적인 사전 교육 패러다임VTP는 멀티태스크 학습을 통해 생성 능력을 향상시키고, 시각적 생성 분야에 새로운 아이디어와 방법을 제공하는 새로운 사전 교육 패러다임을 제시합니다.
VTP의 공식 웹사이트는 무엇인가요?
- GitHub 리포지토리:: https://github.com/MiniMax-AI/VTP
- 허깅페이스 모델 라이브러리:: https://huggingface.co/collections/MiniMaxAI/vtp
- arXiv 기술 논문:: https://arxiv.org/pdf/2512.13687v1
VTP가 표시되는 사용자
- 딥러닝 연구원시각적 생성 모델링에 관심이 있고 생성 품질과 의미 이해를 개선하기 위한 새로운 사전 훈련 방법을 모색하고자 하는 연구자를 위해 VTP는 새로운 기술 프레임워크와 실험적 아이디어를 제공합니다.
- 컴퓨터 비전 엔지니어고품질 비전 생성 애플리케이션(예: 이미지 생성, 비디오 생성 등)을 작업하는 엔지니어는 VTP의 효율적인 확장성과 뛰어난 성능 덕분에 생성 작업을 빠르게 구현하고 최적화할 수 있습니다.
- 자연어 처리(NLP) 전문가크로스 모달 학습 및 멀티 모달 융합에 중점을 둔 연구자인 VTP는 이미지-텍스트 대비 학습과 같은 기술을 통해 시각과 언어의 공동 모델링을 위한 새로운 관점과 도구를 제공합니다.
- 머신 러닝 개발자사전 학습된 모델을 실제 프로젝트에 빠르게 배포하고 적용하려는 개발자를 위해 VTP의 오픈 소스 코드와 상세한 사용자 가이드는 사용 장벽을 낮추고 프로젝트에 빠르게 통합할 수 있도록 지원합니다.
- 학술 연구자인공지능, 컴퓨터 비전 및 자연어 처리 관련 분야의 학계 연구자들에게 새로운 연구 방향과 실험 플랫폼을 제공하여 관련 분야의 학문적 발전을 촉진하는 데 도움을 줍니다.
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서



댓글 없음...