
Voxtral TTS是什么
Voxtral TTS是法国AI公司Mistral AI发布的开源文本转语音模型,采用40亿参数轻量化架构,量化后仅需3GB内存即可在智能手机等边缘设备实时运行。模型原生支持英语、法语、德语等9种语言,具备零样本语音克隆能力,仅需2-3秒参考音频即可复刻任意说话人音色与情感风格。首音频延迟仅70-90毫秒,实时因子达6倍,在盲测中语音自然度与情感表达均超越ElevenLabs Flash v2.5。
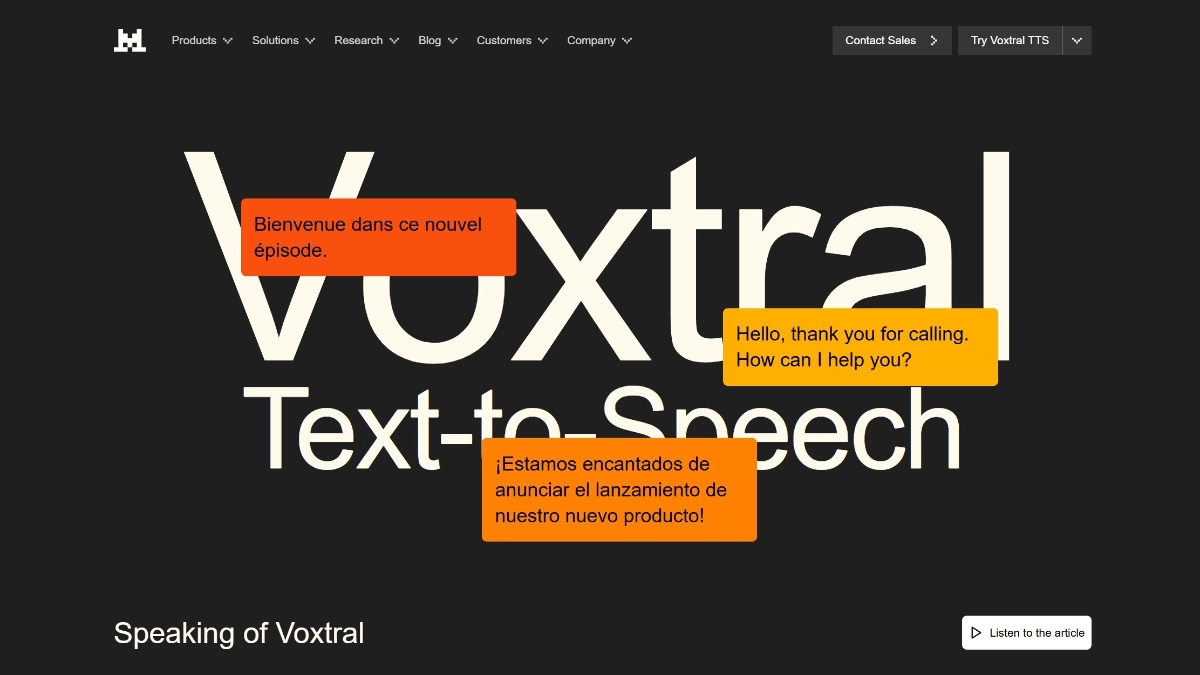
Voxtral TTS的功能特色
- 제로 샘플 음성 복제:仅需2-3秒参考音频即可克隆任意说话人声音,自动捕捉口音、语调、情感起伏和自然口语习惯,无需针对特定说话人微调。
- 多语言原生支持:原生支持英语、法语、德语、西班牙语、荷兰语、葡萄牙语、意大利语、印地语、阿拉伯语共9种语言,支持跨语言音色迁移(如用英语克隆中文说话人音色)。
- 감정적 스타일 제어:可生成中性、快乐、悲伤、讽刺等多种情感语调,无需手动标注情感标签,情感表达与ElevenLabs v3相当。
- 超低延迟高性能:首音频延迟仅70-90毫秒,实时因子达6倍(生成10秒音频约需1.6秒),适合实时语音对话场景。
- 边缘设备友好:40亿参数架构量化后仅需约3GB内存,可在智能手机、智能手表、笔记本电脑等边缘设备实时运行。
- 开源可商用:基于CC BY-NC 4.0许可证发布,模型权重可在Hugging Face下载,支持企业本地部署,避免供应商锁定和数据隐私风险。
- 多种接入方式:支持Mistral Studio在线体验、API调用(约$0.016/千字符)、本地部署三种使用模式。
- 完整语音生态:与Voxtral Transcribe转录模型配合,可构建端到端语音到语音流水线,无需依赖外部供应商。
Voxtral TTS的核心优势
- 开源权重:基于CC BY-NC 4.0许可证发布,模型权重可在Hugging Face下载,支持企业本地部署,避免供应商锁定和数据隐私风险。
- 轻量化架构:40亿参数(实际推理约30亿参数),量化后仅需约3GB内存,可在智能手机、智能手表、笔记本电脑等边缘设备实时运行。
- 다국어 지원:原生支持英语、法语、德语、西班牙语、荷兰语、葡萄牙语、意大利语、印地语、阿拉伯语共9种语言,支持跨语言音色迁移。
- 제로 샘플 음성 복제:仅需3-5秒(最短2-3秒)参考音频即可克隆任意说话人声音,自动捕捉口音、语调、情感起伏和自然口语习惯。
- 超低延迟高性能:首音频延迟仅70-90毫秒,实时因子达6倍(生成10秒音频约需1.6秒),适合实时语音对话场景。
- 감정적 스타일 제어:可生成中性、快乐、悲伤、讽刺等多种情感语调,无需手动标注情感标签。
Voxtral TTS官网是什么
- 프로젝트 웹사이트:https://mistral.ai/news/voxtral-tts
- 허깅페이스 모델 라이브러리:https://huggingface.co/mistralai/Voxtral-4B-TTS-2603
- 기술 문서:https://mistral.ai/static/research/voxtral-tts.pdf
使用Voxtral TTS的操作步骤
- 온라인 경험:访问Mistral Studio控制台或Le Chat平台,登录账号后直接在输入框输入文本,选择语音风格或上传参考音频,点击生成即可试听或下载音频。
- API 호출:注册Mistral账号获取API密钥,通过REST API发送文本和可选的参考音频URL,设置语言、情感风格等参数,接收返回的音频流或文件,定价约$0.016/千字符。
- 本地部署前置准备:从Hugging Face下载Voxtral TTS模型权重,确保设备具备至少3GB显存/内存,安装PyTorch或transformers库及相关依赖。
- 本地推理运行:加载模型后输入目标文本,可选传入2-3秒参考音频进行零样本克隆,设置输出语言和情感风格,执行推理生成音频文件。
- 배치 파일:准备文本列表和对应参考音频路径,编写脚本循环调用模型接口,设置批处理大小以优化GPU利用率,导出音频文件至指定目录。
- 流式集成:使用vLLM-Omni框架配置异步分块流式推理,设置首包延迟阈值,接入实时对话系统或语音客服流水线。
- 音色库管理:收集优质参考音频样本,按说话人/语言/情感分类存储,建立音色配置文件以便快速调用和批量克隆。
Voxtral TTS的适用人群
- AI开发者与工程师:需要集成高质量语音合成能力到应用中的技术人员,可利用开源权重本地部署或API调用,避免供应商锁定。
- 语音AI产品经理:负责构建语音客服、智能助手、IVR系统等产品,需低延迟、高自然度TTS能力支撑实时对话场景。
- 内容创作者与播客主:有声书、电子学习课程、播客内容制作者,可利用零样本克隆快速生成个性化配音。
- 本地化与翻译团队:需要跨语言配音能力的国际化团队,支持9种语言原生合成与跨语言音色迁移。
- 边缘设备开发者:在智能手机、智能手表、IoT设备上部署语音功能的嵌入式开发者,模型量化后仅需3GB内存。
- 隐私敏感型企业:金融、医疗、政务等对数据安全要求高的机构,可本地部署确保语音数据不出域。
Voxtral TTS的常见问题FAQ
Q:Voxtral TTS是免费的吗?
A:模型权重基于CC BY-NC 4.0许可证开源,可免费下载用于非商业用途;商业使用需遵守许可证条款,API调用定价约$0.016/千字符。
Q:Voxtral TTS支持中文吗?
A:原生支持9种语言(英/法/德/西/荷/葡/意/印/阿),中文不在原生支持列表,但可通过跨语言克隆用英文合成中文说话人音色。
Q:需要多少显存才能本地运行?
A:量化后模型仅需约3GB内存/显存,可在智能手机、智能手表、笔记本电脑等边缘设备实时运行。
Q:克隆一个声音需要多长的参考音频?
A:零样本克隆仅需2-3秒参考音频即可捕捉说话人音色、口音和情感特征,无需针对特定说话人微调。
Q:生成延迟是多少?适合实时对话吗?
A:首音频延迟70-90毫秒,实时因子达6倍(生成10秒音频约1.6秒),支持实时语音对话场景。
Q:可以控制生成语音的情感吗?
A:支持中性、快乐、悲伤、讽刺等多种情感风格控制,无需手动标注情感标签。
Q:与ElevenLabs相比如何?
A:盲测中语音自然度胜率58.3%,零样本克隆胜率68.4%,情感表达与ElevenLabs v3相当。
© 저작권 정책
기사 저작권 AI 공유 서클 모두 무단 복제하지 마세요.
관련 문서


댓글 없음...